I've been using VS Code for years, it's awesome. I thought I would never leave it until the end of my career. But everything changed since the day my colleague presented his awesome Neovim setup. It's pretty cool, but tough for me, a newbie in the Keyboard does everything space.
I spent my whole weekend setting up my own Neovim IDE. It's even worse since there are so many outdated configs that couldn't run on my potato machine. But that's another story, in this post, I'll just share something I couldn't miss in an IDE in this Age of AI: "Copilot".
Setup
There are many options out there. In this post, I will share my current setup with https://github.com/David-Kunz/gen.nvim.
gen.nvim
Generate text using LLMs with customizable prompts

Video

Requires
-
Ollama with an appropriate model, e.g.
llama3.1,mistral, etc. (Simple setup) - Cortex for more advanced setup, e.g., switching models between different engines & providers such as Llama.cpp, OpenAI, and Claude.
- Curl
Install
First thing first, let's install the plugin:
Example with Lazy
-- Minimal configuration
{
"David-Kunz/gen.nvim",
opts = {
model = "mistral", -- The default model to use.
}
}
Voila! You now have the code gen plugin installed. You can now run the Ollama Mistral model on your machine to see how it works.
Select a block of code that you want to ask, then do :Gen.
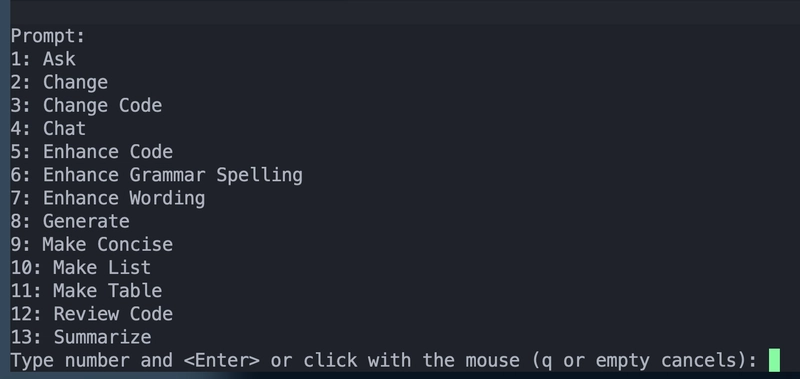
Generate text using LLMs with customizable prompts
The author also published a YouTube video that explains it better, please check it out.
Let's do a more advanced setup.
It's cool, right? But that's not my current productive setup. Sometimes my low-spec machine does not have enough VRAM to run bigger models, so I have to switch to remote endpoints.
Let's customize the plugin configuration to connect to other endpoints, such as OpenAI.
{
"David-Kunz/gen.nvim",
opts = {
model = "gpt-4o", -- The default model to use.
host = "api.openai.com",
port = "443",
command = function(options)
local body = { model = options.model, stream = true }
return "curl --silent --no-buffer -X POST https://"
.. options.host
.. ":"
.. options.port
.. "/v1/chat/completions -d $body"
.. " -H 'Content-Type: application/json'"
.. " -H 'Authorization: Bearer sk-xxxx'" -- OpenAI API Key
end,
}
}
Let's try chatting with the model again and see how it works. This prompt is just to ensure we are making requests to the OpenAI endpoint instead of Ollama.
Prompt:

Result:

All good.
Switching between configurations is tough though...
Sometimes I like to try out new models. They can be run locally or just remotely. How can I switch between those options without reconfiguring everything again and again?
This is the one you are looking for. https://github.com/janhq/cortex
I consider this a very good candidate for my use cases, since it supports multiple engines, both local and remote.
Now for the installation, I chose the npm option since I'm more familiar with the JS ecosystem. (It turned out that I can install this package inside my JS applications as well.)
npm install -g cortexso
Let's run the server! 🚀
cortex

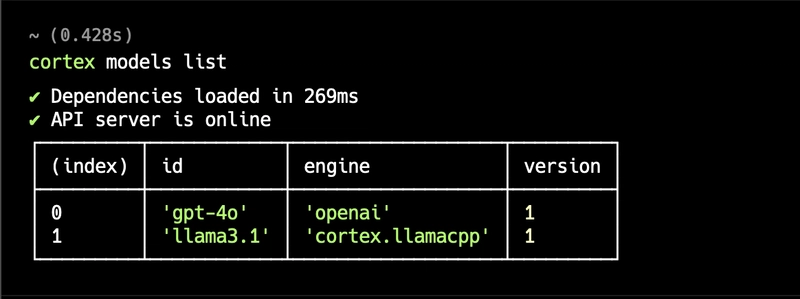
The server is ready! Now pull any models from the Cortex Hugging Face Repository. There are so many models that have been republished, as well as remote providers that you will want to try out.
cortex pull llama3.1
cortex pull gpt-4o
You can also pull any of your favorite HuggingFace models. E.g.
cortex pull google/gemma-7b-GGUF.
Voila, now I have two models pulled.
But, isn't OpenAI's models required to run with an API Key? Here is how to set it.
cortex engines openai set apiKey sk-your_api_key_here
You forgot something, huh? We need to run the models the same way Ollama does.
cortex run llama3.1
Only local models require this run step.
Time to update our gen.nvim configurations 🚀
{
"David-Kunz/gen.nvim",
opts = {
model = "gpt-4o", -- The default model to use.
host = "localhost", -- The cortex server host address.
port = "1337", -- The cortex server port number.
command = function(options)
local body = { model = options.model, stream = true }
return "curl --silent --no-buffer -X POST http://"
.. options.host
.. ":"
.. options.port
.. "/v1/chat/completions -d $body"
.. " -H 'Content-Type: application/json'"
end,
}
}
Let's chat with our new friend ;)

Hold on, how to switch between models? 🤔
How do you switch between models from different engines that are installed?
gen.nvim supports a model selection function to switch between models. Let's map a key for it.
map("n", "<A-m>", function()
require("gen").select_model()
end, { desc = "Select gen.nvim model" })
But it does not work yet, since it makes requests to Ollama by default. Now we customize it to fetch models from the Cortex server.
{
"David-Kunz/gen.nvim",
opts = {
model = "llama3.1",
host = "localhost",
port = "1337",
debug = false,
command = function(options)
local body = { model = options.model, stream = true }
return "curl --silent --no-buffer -X POST http://"
.. options.host
.. ":"
.. options.port
.. "/v1/chat/completions -d $body"
.. " -H 'Content-Type: application/json'"
end,
list_models = function(options)
local response =
vim.fn.systemlist("curl --silent --no-buffer http://" .. options.host .. ":" .. options.port .. "/v1/models")
local list = vim.fn.json_decode(response)
local models = {}
for key, _ in pairs(list.data) do
table.insert(models, list.data[key].name)
end
table.sort(models)
return models
end,
}
}
Let's try Alt + m

🤘🤘🤘 Cool, right? Seamlessly switching between models, from local to remote models and between different providers.
Conclusion
This setup allows you to leverage both local and cloud-based AI models, enhancing your coding workflow with intelligent assistance.
As you become more comfortable with this setup, consider:
- Creating custom prompts for your specific development needs
- Exploring different models to find the best fit for various tasks
- All of the linked projects are open-source, please don't forget to drop a star and help contribute. Please try different models, create custom prompts, and adapt the configuration to your unique workflow. Happy coding!

Top comments (0)