When .NET 8 arrived in November last year, I wanted to try some of the new C# language features and the new tooling features like Native AOT. At that moment I didn’t have a .NET related work project, so I decided to create my own personal project to discover about .NET 8, but also to try new architectural things. Now, I’ve created a kind of reference implementation or starting solution for building .NET 8 services. In this blog I’ll explain the journey I had into building this and the reasoning behind the architectural choices I’ve made. For me, this repository is a good reference and starting point for creating both monolithic applications as building microservices. And I’m also sharing this solution to the community, as it could be maybe interesting for others, I think.
The repository with the solution and example can be found here at Github. This one is based on a simple monolith with three domains.
It contains a README file that holds instructions how the build and run the solution. Also unit- and integration tests are included, which is interesting because I’ve made use of Testcontainers to make sure that a local PostgreSQL database is available when running the tests.
Goals when creating this project
As I started this project, I wanted to explore some of the new C# (version 12) language features. Things like primary constructors and collection expressions had my interest, and it was satisfying to use them!
But besides to play around with the new features I wanted to create an up-to-date starting point for creating new API (micro)services that run inside containers on Kubernetes or Azure Container Apps or something similar. For me, this could be useful for customers where I’m located doing freelance work in the future. This starter kit has batteries included, so it already had some setup like logging, configuration, validation, etc.
When I’m performing my professional job, I already have encountered moments where a new green field project is started, and it must be built with modern development practices, but it also had a short time window to deliver the first version to a production environment. I’m a fan of the microservices architecture and working in an environment full of individual services that communicate with each other, but sometimes it is maybe not a good idea to start building a big amount of microservices at the start of a new green field project. It could… but sometimes it is better to build a monolithic service first that holds many business domains.
And as the development progresses, it may become apparent that the monolithic service should be divided into smaller services because the service has to many concerns, became too complex and/or more and more development teams are working with the same service so that imposes all kinds of deployment issues and complexity. But extracting functionality from a service and move that functionality to a different service could be painful. Therefore, I thought of an architectural pattern to make sure that domains should not be intertwined, and it should be theoretically easy to slice a monolithic service into multiple (micro)services.
The service architecture explained

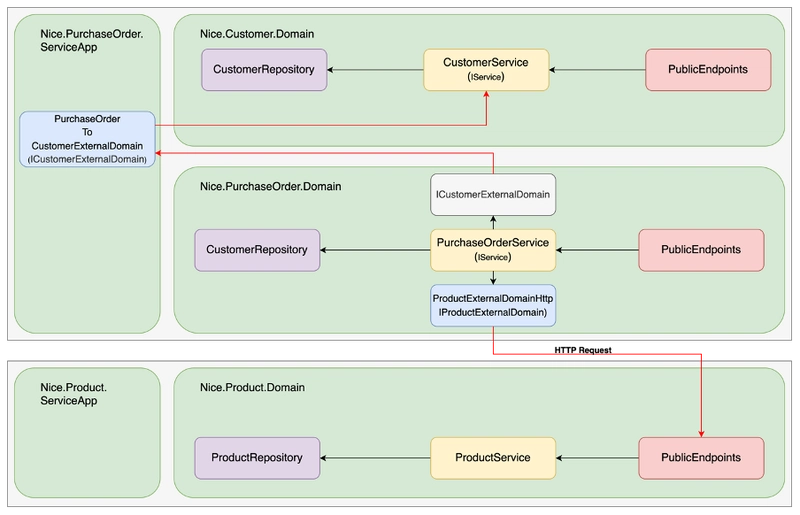
A typical service in this solution consists of one or more business domains and an application layer which spans all domains. The application layer makes sure that the service can be started, and all business domains are in play. The business domains all contain an endpoint layer, a service layer, and a repository layer. These three layers are mostly in tandem with each other and there could be combination of all 3 for each subdomain within the business domain if needed. When this happens, I tend to make sure of subdirectories for each of the sub domains and put the layers in these subdirectories.
The application layer is a simple project which contains a startup file (Program.cs) that starts the service and binds all business domains. The real magic for the service lies in the Nice.Core project, which contains the typical .NET console app setup with a HTTP server, logging (Serilog), configuration management using environment variables that bind to classes, dependency injection container setup, OpenAPI stuff and some more. Typically, you want to publish this Nice.Core project to a Nuget repository so that all services can reference this project. This ensures that services (if you have many) contain the same foundation and new foundation features can be applied to all services by upgrading the Core dependency, instead of per service finding out how to implement the foundation feature because each service has its own setup.
As written, each business domain contains at least 3 layers. These are:
Endpoints: This layer is an abstraction on the Minimal API implementation of .NET services that can be created today. It is the entry point of all HTTP requests that are made to the service. The abstraction makes sure that public and internal endpoints are separated and that the endpoints are grouped in their own domain. The Nice.Core library has some convenience to bind all endpoints in each business domain together. The separation between public and internal endpoints is made, so that internal endpoints don’t have to be publicly available when using a gateway such as Azure Application Gateway or a Kubernetes Ingress Controller (like nginx). By using rewriting rules on the gateway or ingress controller, incoming requests can be rewritten as /public/[path], so it never reaches the private endpoints, which start with /internal/[path]. The internal endpoints are useful for internal communication such as health checks, but also between two services when service busses or event systems are not a good option for specific scenarios.
Service: The services layer is the heart of the system because they contain the business logic that drives the business where the system is used. The simple rule should be that all logic should be in this layer and not in the endpoint or repository layer. This layer is referenced mostly from the endpoint layer for incoming HTTP requests, but sometimes this layer could also be trigged based on timers or other ingestion methods such as service busses. The service layer itself holds its own data models, as it never shares them with the endpoint or repository layer. This means that mapping between the models in the different layer occur, but Mapperly is used for that to make that easy to do. The reason to separate the models between layers, is that each layer has/needs its own information and structure. Sometimes the data you get from the database is not the same as you want to return as response on an API request. Maybe data must be grouped, or some parts of data should be obfuscated or removed. If the same models are used on all layers, this could lead to unwanted side effects, that a new field in the repository automatically also is added to the response on the API request without any failsafe measures.
Repository: In this layer all calls to a (relational) database system are made for retrieving and storing data. Using a relational database doesn’t stop you from using document structures as PostgreSQL (and SQL Server) allow for storing complete JSON structures into columns and search through them. It allows for an interesting mix between relational table structures and flat tables with complex objects in it. My preference is using the complex objects and keep the table structure flat. It is very important that also in this layer you keep the separation between the domains. So, no joins between tables from different business domains. If data from multiple business is needed, then there are different methods such as making multiple calls (could have performance impact, so this not always a good idea!) or snapshotting of data from the other domain into the complex objects of this domain so it can be retrieved in one call.
Beside these layers, there is a special kind of interface that it is best positioned in the Service layer. It allows services from two different business domains to communicate with each other. Therefore, an interface in the business domain project is the initiator for the communication between the two domains, is created with the I…..ExternalDomain naming convention. The implementation of this interface is created in the application layer (ServiceApp) as it references all business domain projects. In the implementation, the call is made to the other service in the other domain and then the result is mapped to the data model that is defined in the initiator project. By using this structure, a direct reference between the two business domains is not needed.
There is no direct coupling between the two business domain projects, which makes it easier to extract a business domain into its own service later when moving from a monolithic application to microservices or when splitting a big microservice into separate smaller microservices. In these situations, the most straightforward refactoring is that the implementations of IExternalDomain should then be replaced by implementations that make a HTTP call to the other service.
Making it Native AOT compatible
Ah yes, there was also another goal I wanted to pursue in this reference project and that was making use of another new .NET feature: Native AOT Compilation. Although it already was introduced in .NET 7, now in .NET 8 is it improved, and it is now good enough to be used in serious implementations. This is also backed by the fact that many popular libraries are building support for it.
But what can we do with Native AOT compilation and why is it useful for this reference project? The Microsoft site documentation gives an insight in what it can do, but also what the limitations are.
The things that I find useful is using this in a Kubernetes environment where containers should be small in both memory as container size and most be started very fast.
But making a solution compatible with Native AOT is hard and has mostly to do with the fact that in some scenarios you make use of ‘reflection’ as not everything is known at compilation, especially when you try to create some generic reusable constructs. But also, many libraries lean on the use of reflection, such as popular libraries as Dapper and Swashbuckle (for OpenAPI definitions). I found out that at this moment libraries are starting to make their libraries compatible for the use with Native AOT compilation, mostly by the use of source generators. These are parts of code that are generated at compilation by examining the source code that is there and therefore can be used to replace reflection. Some of the libraries that I use in my solution that are Native AOT friendly by using source generators are:
- DapperAOT: The small ORM framework which allows me to execute queries on PostgreSQL and map them to .NET records.
- Mapperly :Object to object mapping to allow data move between layers and domains without having an shared domain model that everyone is dependent on.
- Injectio: To mark the implemention of classes that should be in the DI container without scanning the assembly.
I think in .NET 9 more work will be done to make the use of Native AOT even better, but this is a nice start. For now, I have a nice starter project for services that could start large as a monolith but become microservices by extracting parts of the service without overhauling the whole application.

Top comments (0)