If you read the internet, you'll soon realise that a large number of software developers don't understand what CI is and why it's important.
It's important to state that continuous integration is not a server.
Like the word DevOps, people seem to think these important principals of software engineering are about tools and products. Perhaps misinformed managers think if they buy the right magic box they can finally deliver their projects on time.
Continuous integration is continuous integration
Read the words.
It's about making sure that when you are working on code is the most up to date version of the code as a team.
In an ideal world if you could somehow all work on same computer at the same time comfortably, that would be pure CI.
If you've ever used VS-code's Live Share plugin, that's as pure a CI experience you can get in a remote environment. If you've not used it, it allows you to connect to a colleague's VS code and edit the code together as if you're working on the same computer. The changes you make are reflected (or integrated) to everyone else in the session - the feedback is immediate.
A much simpler experience of CI is mobbing. Everyone is working from the same version of the code together.
How do you know if you're not practicing CI well?
One obvious sign is developers wasting lots of time resolving large merge conflicts. Merge conflicts are a direct result of you working on a version of the code that isn't up to date. Your team are not integrating their changes continuously and therefore as they make changes the risk of making invalid changes increases.
The time wasted on merge conflicts has compounding effects as it increases the delays of integrating your own changes to the system.
One might argue you can resolve this by structuring work differently to avoid conflicts, even going as far as to re-architect your system to avoid merge conflicts. An often touted reason to go for microservices is it allows teams to work independently.
Reader, I have worked on a team with 20 odd developers, shipping frequently on a monolith and very rarely did we have merge conflicts. We also didn't do pull requests, we committed to master.
If you don't practice CI you are not working with your team as well as you could
Changes to the system are invisibly stored on your colleague's computers where they are of no use to you.
You could be imagining some great abstraction given the code in front of you but unfortunately the code in front of you is not the source of truth because unknown to you another developer merges a gigantic change after spending a week on a feature.
People become reluctant to refactor parts of the code because someone is working on a branch that is vaguely near the code you want to change so you wait a few days and then forget about it.
How do you CI well?
The simplest way is for everyone to commit to master, frequently. It really is that obvious!
To be good at continuous integration, you should continuously integrate your changes to master. That way everyone will be working with the same version of code for the most part.
It's important that you respect your colleagues and run your tests before pushing. If the build is broken the team should stop committing unless it's to directly fix the problem. If people keep committing whilst the build is broken it will become very difficult to diagnose what the problem is and the new commits may compound the issue.
The process, in full
git pull -r- Make a positive change to the system
git commit -am "added blockchain terraform machine-learning module 2.0"git pull -r./build.sh && git push
This practice is simple to follow, doesn't require elaborate review systems, branch strategies etc, and forces good habits.
- In order to push frequently, you need to pull changes frequently
- You can only push frequently if you work on small tasks, iteratively. There are many, many reasons why this is a wonderful, less risky and easier way of working. (see TDD, XP, any decent agile book, etc etc)
It wont entirely stop merge conflicts occurring, but they should be very infrequent and because you're doing small changes they're typically trivial to resolve.
But what about code review?
The industry seems to have conflated reviewing code with a very specific, relatively new process of looking at code when a pull request is submitted; usually too late once all the code is written.
Did you know that you can talk about code, at any time during the day?
Did you also know that the correct abstractions and patterns may not be apparent when the code is "done" and you'd be better off encouraging an environment where people are free to refactor code when they want to, rather than having to go through a laborious process every time they want to change the code. I've worked on and observed projects that practice code review very strictly and yet the code is still not great.
Relying on a process of checking code before it is merged is not going to result in a healthy codebase alone.
With this way of working I strongly encourage pair programming because people rightly assert that as a lone developer it is very easy to do something wrong if you don't gather feedback. Pair programming facilitates a constant feedback loop on what you are writing.
What if someone commits something wrong/broken?
First of all, no process in the world can prevent this. Stuff does go wrong, and you would be better asking yourself:
How can we detect and recover from problems easier?
Secondly, this approach does require a healthy and collaborative team that talk to each other regularly about what they are working on. They should be talking to each other when they start a bit of work about what they are going to do, how they will release it safely, what kind of tests, etc. Couple that with working on small things iteratively the risk of pushing something catastrophic are very low.
If someone does push some code that maybe works (so the tests pass, monitoring is all good, etc) but is actually "bad". Well so what? We can refactor it if we don't like it.
What if I, a tech lead want to check every change before merging
I don't want to work with gatekeepers.
I want to work on a team that trusts one-another.
Perfect is the enemy of good.
So is a system of pull requests bad?
Not at all, they're perfect for open source projects where you want to welcome contributions from other people but dont have implicit trust. In that case you will want to review changes that go into your precious project.
For a team where you trust the developers all it adds is overhead.
Liberation
We should be removing the barriers to changing software, not adding walls and walls of bureaucracy.
In this kind of environment people fix code when they see it needs fixing.
This way of working tightens feedback loops and increases actual meaningful agility.
CI is not just about the code
- It's important to integrate knowledge of domain, work etc. (so important not to have silos of work with just the BAs/UXD etc)
- Who is working on what (standups, kick-offs, etc)
Gaming it
I feel very strongly about working this way over a pull request approach when you are working on a team you trust.
Most of my team until recently were very unfamiliar with this way of working so I made a silly dashboard on one of the TVs which showed who committed to master most over a given week. It penalises you points if you push a change which breaks the build.
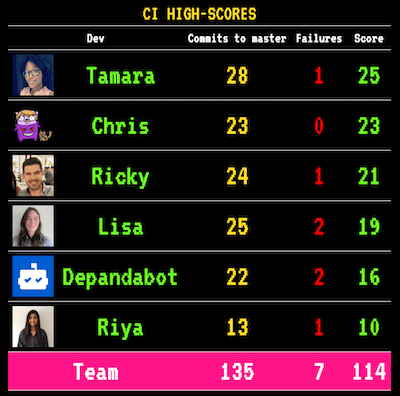
After just a few weeks this slight nudging has improved the team's approach to CI, we've had significantly less merge conflicts, people are refactoring more often and the number of failed builds has also dropped.
And if you have docker, you can run it with
$ docker run -p 8000:8000 quii/ci-league
If you want it to look at a private repo you'll need to supply a github personal access token as an environment variable
$ docker run -p 8000:8000 -e GITHUB_TOKEN=supersecret quii/ci-league
It doesn't do any fancy auto-refreshing but most browsers have extensions to auto refresh a tab, we set it to update every 10 minutes here.
Wrapping up
As usual in software, we seem to suffer as an industry of remembering the why of all of these fancy terms.
If you appreciate the why of CI you may not fall in to the trap of blinding applying best practices that work in a different context to the one you are working in. As I said pull-requests in an open source project make total sense and work great. In a different context it adds overhead.
You should instead focus on what your environment your team is working in, the constraints you have and use principles like CI to guide what process best fits.

Top comments (15)
I completly agree with most but hate the gameification, rating developpers of your company on a leaderboard on such insignificant factors as commit count... yikes.
This is opening the door for really shitty behaviour, like "oh let's create a commit for each letter I type so I will have a better score"
Granted that this is an extreme example but still, also having a pressure of not being commiting enough when maybe you work on a way more complex part of the project that require more research and planning...
Just don't do that, once you give a score, your back to school.
I think it depends on how healthy your team is. My team understands that it's not at all a rating system, it's just a bit of fun and makes people aware of how frequently (or not) that they are integrating their changes.
I am not at all worried about my team doing shitty behaviour because I don't have a shitty team.
I think this is great and hope you can keep it on like that because I somehow agree with @Clement that this might cause some troubles along the way
I know his examples are a bit extreme and that you trust your team a lot, but it's just that society (especially western society) has taught us to be overly competitive over every single thing that even when we can rationalize that it's just a fun game it can cause some fights inside the team
I don't think you have to throw away all the gamification aspect though, just maybe drop the ranking part? or make it more like you're fighting yourself? I think those things could help to prevent anything from getting out of control in the future
I do like the idea of "fighting yourself", might play around with that idea a bit.
TBH the one metric i'm actually looking at is the team score, if the team is improving at integrating changes then it's doing its job.
Maybe that could be another metric, that would make it more collaborative rather than competitive ;)
How do you handle unfinished features?
Normally I would create a feature branch an merge it as soon as I'm completely done, while doing a lot of pushes to my feature branch on gitlab to prevent data loss in the case my local environment breaks...
Where would I push my unfinished changes while using the "ci way of doing it"?
Except for this question I'm very curious about actually trying these principles ! Seems to be a nice way of working!
Feature flags are a good way of accomplishing this. Has the added advantage that you can try it out in production for real without effecting real users (if you can control them via cookies for instance)
It depends on the feature and does sometimes take some creative thinking and experience, but it's worth the effort.
A recent example in our team is developing a new react component in isolation (e.g not actually integrating on the page per-se) but allowing us to work on it together.
Hmm seems legit for a new feature/replacement...
But what about database migrations/changes...
What if a new feature requires a database change which would break the previous logic? In this case Feature flags are worthless and the only way of handling it would be a second (or even one for every feature) database...
Or do I get it wrong and there is also a nice solution to this?
I've found it is usually possible with some creative coding to keep db changes backward compatible and this is usually a much safer way of working anyway - irrespective of how you work
e.g keep the old field, introduce new field, code feature toggles against using both and then once you're happy with the new one you can safely delete.
Sometimes though, maybe something doesn't fit into small iterative changes. I would contest this is rare but if it does... well take the hit. Acknowledge it isn't great in this case. One pair works on the awful thing that is perhaps on a branch for a week. They have to contest with merging things etc. You get through it and move on.
I totally agree with you, mostly people trying to make the code perfect! from the beginnings, they don't care about delivering valuable business as much as they care about that string value should be extracted to a separate file because it might be used in different place in the future. Thanks Chris, gonna share the article and hopefully it changes their minds :D
I love this idea of CI gamification. We need to be careful with peer scoring though... it can have bad unintended consequences (I've been there myself).
I think code reviews are a pain too! With a good retrospective, we can use this pain to guide a team into pair programming. That's how we did it in a previous team (Full story here philippe.bourgau.net/from-zero-to-...).
We also had success spreading TDD and XP practices with regular team Coding Dojos. Without these practices, it's indeed very difficult to achieve true CI and small commits.
Thanks!
I think this is pretty spot on
Thanks Ben! I want to see photos of ci-league running at Dev.To asap ;)
I'm curious: have you had any issues where people commit too often to inflate their ranking? Or do you enforce a squash workflow where a given feature must be squashed down to a single commit?
The ranking is just a bit of fun and not at all serious. I have a healthy happy team who wouldn't do silly things really, we have some honour :)