
While going through the Eleventy’s docs recently I discovered an interesting feature, Linters. This feature lets you define custom rules you want to apply to your logic such that you can throw warnings during the editing and publishing process. The docs have an example of this in action but I wanted to expand a bit on it and see if I can add in textlint support. textlint is a customizable text linting program built with Node.
I first blogged about textlint back at the end of 2018 and described how I connected it to my GitHub commit process. I decided to take a look at how I could integrate it with Eleventy.
First, a quick note about their linter API. First, this will not allow you to throw errors. I mean you could throw an error in your code, a manual Exception I mean. Instead you use this feature as a way to log out messages to the console during development.
You are passed three arguments: content, inputPath, and outputPath. Let’s discuss the second two first. As you can guess, inputPath is the file being processed, like foo.liquid, and outputPath is the destination path which follows Eleventy’s rules for such things. Using foo.liquid as input, it may be foo/index.html for output. These paths are relative, so keep that in mind if you need to do anything that requires the full path.
The content argument is the parsed HTML output of the template, which is very cool. It means you can lint the text the public will see. Well that’s mostly cool. In my testing, I noticed that one of the plugins I used for text linting did not like HTML, so I removed it. But in general I think it’s very good that you get the “final” content instead of content with embedded variables and things in it from the template language.
Alright, so with all that, how does this all work? Let’s consider their default example:
eleventyConfig.addLinter("inclusive-language", function(content, inputPath, outputPath) {
let words = "simply,obviously,basically,of course,clearly,just,everyone knows,however,easy".split(",");
if( inputPath.endsWith(".md") ) {
for( let word of words) {
let regexp = new RegExp("\\b(" + word + ")\\b", "gi");
if(content.match(regexp)) {
console.warn(`Inclusive Language Linter (${inputPath}) Found: ${word}`);
}
}
}
});
They begin by defining a set of source words they want to check for. Next they see if the input file was markdown. I think, in general, this is a good thing to do since a content site will probably be largely markdown with other ancillary files being Liquid or some other template language. So for example, my blog uses markdown for 100% of the blog content, but pages like my “About” and “Speaking” pages are Liquid. In theory I’d like to lint them too, but I’d be ok with just the markdown being check. When run, this is how it looks (assuming you have a few issues in your content):
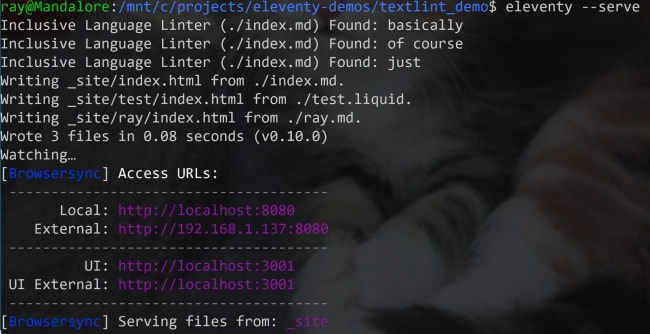
You can see the messages sent out immediately after I started the server. The messages will be repeated every time I edit so the feature gives you good, constant, feedback in the console as you work.
That’s the out of the box example, how about an example with the textlint project? First off, note that textlint has a large number of rules. Each rule is it’s own project and must be npm installed. Each rule also has it’s own configuration. In my testing (both now and the previous times I’ve worked with it), I’ve found mixed results from different rules. For example, I never could get spell check working well. Also, things like the alex rule, which looks for gender favouring or insensitive language, didn’t work with HTML. I don’t think that was documented at all. Basically this is my way of saying that while overall textlint is a cool project I think, you should expect a bit of roughness around the edges.
For my testing I decided to use some of the same rules I used in my previous test.
- alex which covers insensitive language
- no-start-duplicated-conjunction which attempts to find multiple sentences starting with words like “but” or “so” - I never got this test to work though.
- terminology which looks for the right spelling of certain technology-related words, like iOS versus ios.
I made a new Eleventy project (which is just a folder) and npm installed textlint and then the three rule plugins. Here’s my .eleventy.js:
const chalk = require('chalk');
const TextLintEngine = require('textlint').TextLintEngine;
const options = {
rules: ["alex", "no-start-duplicated-conjunction", "terminology"]
};
const engine = new TextLintEngine(options);
module.exports = function(eleventyConfig) {
eleventyConfig.addLinter("textlinter", async function(content, inputPath, outputPath) {
// Some rules don't like the HTML
content = content.replace(/<.*?>/g, '');
let results = await engine.executeOnText(content);
//console.log(JSON.stringify(results));
for(let i=0; i<results.length; i++) {
for(let x=0; x<results[i].messages.length; x++) {
let msg = `[${inputPath}] `+results[i].messages[x].message
console.log(chalk.yellow(msg));
}
}
});
};
Alright, so on top, I started off adding Chalk, a cool utility that makes console.log messages stand out a bit. I then instantiated my instance of textlint.
In the addLinter block, I then pass the content of the file being parsed to the engine and take the result. The results an array where each instance of the array contains an array of messages. So I loop inside a loop and output the result. You can do more with the results, like provide alternatives and the like, but you’ll need to check what’s provided on a rule by rule basis.
For each message, I use chalk.yellow to make the message stand out a bit. Red may be better, but it’s up to you!
As I mentioned earlier, the alex rule didn’t like HTML. It didn’t throw an error, it simply ignored the entire input. That was frustrating, but quick to fix with the regex you see.
Here’s the output based on some test files I created.

As I said, this is not a perfect solution. So for example, for terminology I had used javascript in my test and it wasn’t picked up. Why? I had this as input:
Hi world I'm the mailman for today.
I love me some javascript, don't you?
I've got an android browser.
How about ios testing?
See the comma after javascript? That was enough to “break” the rule. When I removed it the linter rule found it. It’s an open source project so this could be patched of course, just remember what I said - each rule has it’s own quirks you’ll need to figure out.
I hope this helps, and you can find the complete demo repository here: https://github.com/cfjedimaster/eleventy-demos/tree/master/textlint_demo

Top comments (0)