Points from the course: AI Workflow: Feature Engineering and Bias Detection
Summary:
The data-transformations part of the AI workflow is the first point in the overall process that explicitly encourages iteration. This stage encompasses all possible transformations of the data, such as dimensionality reduction, outlier detection, clustering and other forms of unsupervised learning. Combining these activities into a single process is done mainly because selecting a suitable transformation or tuning a given transformation takes the same form. That form builds on the three interfaces of scikit-learn and the container class pipelines.
Transformer interface
Used to convert data from one form to another
Estimator interface
Used to build and fit models
Predictor interface
Used to making predictions
It is worth noting that these interfaces in combinations with pipelines have had such an impact on the data science workflow that Apache Spark now has similar ML pipelines.
Class imbalance, data bias:
Imbalanced classes are common especially in specific application scenarios like fraud detection and and customer retention. The first guideline is to ensure that you do not use accuracy as the
metric as the results can be misleading. Accuracy is the number of correct calls divided by all of the calls.
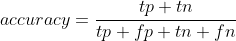
If our positive class is only a small percentage of the overall data you can see that the model
will be optimized for the negative class. The ability of a model to resolve true positives will not be well-represented in the metric because it will be overwhelmed by the influence of the
majority class. Metrics based on precision and recall will be more specific to the problem because TN (true negatives) is not part of the numerator.
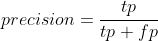
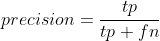
The most common approaches to address imbalanced classes are sampling based. Between over-sampling and under-sampling, under-sampling is conceptually simpler. Given a minority class or classes that are noticeably underrepresented, you may randomly drop some of those observations from the training data so that the proportions are more closely matched across classes. A major caveat to under-sampling is that we are not using all of the data.
Over-sampling techniques come in several forms, from random or naive versions to classes of algorithms like the Synthetic Minority Oversampling Technique (SMOTE) [1] and the Adaptive
Synthetic (ADASYN) [2] sampling method. There are a number of variants of these over-sampling algorithms that can be compared.
All of the sampling techniques that we discussed are implemented in the imbalanced-learn Python package. This package is convenient because it allows for the implementation of multiple sampling techniques as pipelines. Additionally, it interfaces with TensorFlow and Keras in a convenient way as well, which is important because neural networks are generally sensitive to class imbalance.
Support Vector Machines (SVM) are an example of a machine learning algorithm that is less sensitive to imbalanced classes. SVMs can be tuned to accommodate situations with unbalanced class proportions making them a reasonable tool for outlier detection as well
Dimentionality Reduction:
Applications of data science that often require dimensionality reduction for visualization or for modeling purposes are: image analysis, text analysis, signal processing, astronomy, and medicine.
Discussed three main categories of dimensionality reduction techniques: matrix decomposition, manifold learning, and topic models. The techniques developed for topic models generally fall
under one of the first two categories, but the application is natural language processing. The principal reasons for considering dimensionality reduction in your workflow are:
* visualization
* remove multicolinearity
* remove redundant features
* deal with the curse of dimensionality
* identify structure for supervised learning
* high-dimensional data
These materials review principal components analysis (PCA), Non-negative matrix factorization (NMF) and singular value
decomposition (SVD) as examples of matrix decomposition algorithms. A major drawback to using PCA is that non-linear or curved surfaces tend to not be well-explained by the approach. An
alternative approach uses manifold learning for dimensionality reduction. Specifically,
Discussed tSNE family of
approaches.
NMF and Latent Dirichlet Allocation (LDA) are used as methods to carry out topic modeling. The embedding approach tSNE is often used to visualize the results of topic model representations in lower dimensional space to both tune the model as well as gather insight into the data. The package pyLDAvis is specifically purposed with visualizing the results of these models.
IBM ai360:
The AI Fairness 360 toolkit is an extensible open-source library containing techniques developed by the research community to help detect and mitigate bias in machine learning models throughout the AI application lifecycle. The AI Fairness 360 Python package includes metrics to test for biases and algorithms to mitigate bias.
A bias detection and/or mitigation tool needs to be tailored to the particular bias of interest. More specifically, it needs to know the attribute or attributes, called protected attributes, that are of interest: race is one example of a protected attribute, another is age.
Handling outliers:
Outlier detection algorithms:
Isolation forest
- One efficient way of performing outlier detection in high-dimensional datasets is to use random forests. This method isolates observations by randomly selecting a feature and then randomly selecting a split value between the maximum and minimum values of the selected feature.
Elliptic envelope
- One common way of performing outlier detection is to assume that data are Gaussian distributed. From this assumption, we can try to define the general shape of the data, which leads to a threshold-approach to calling an observation an outlier.
OneClassSVM
- Use a single class version of a support vector machine to identify an optimal hyperplane that can be used to call an observation an outlier.
For high-dimensional data it is sometimes necessary to pipe the data through a dimension reduction algorithm before applying the outlier detection algorithm. In addition to how you scale the data, there is the choice of dimension reduction algorithm and the choice of outlier detection algorithms. Moreover, there are generally parameters that modify these outlier detection algorithms, such as an assumed level of contamination. Given the number of tunable components, grid-searching and iteratively comparing pipelines to decide on a suitable outlier detection pipeline can be time consuming.
Unsupervised learning:
Machine learning models that are used to predict the values of response variables generally fall into the domain of supervised learning models. By contrast, unsupervised learning deals with the discovery of patterns derived from the feature matrix itself. We have already seen how useful derived patterns are in the example of visualizing high-dimensional data and outliers. The domain of unsupervised learning has many families of models. Clustering analysis is one of the main subject areas of unsupervised learning and it is used to partition the observations in a feature matrix into groups. Some models use probabilistic or ‘soft’ assignments.
Clustering algorithms
Mixture modeling
There are a number of other clustering algorithms available.
Model selection:
- PROS: very flexible and can be visualized through a silhouette plot CONS: generally higher for convex clusters than other clusters such as density based clusters
- PROS: The computation of Davies-Bouldin is simpler than that of Silhouette scores.
- CONS: generally higher for convex clusters than other clusters, such as density based cluster. It is also limited to the distance metrics in Euclidean space.
Calinski-Harabasz Index
- PROS: The score is higher when clusters are dense and well separated, which relates to a standard concept of a cluster
- CONS: generally higher for convex clusters than other clusters such as density based clusters

Top comments (0)