
Hey there,
When training a Machine Learning model, you always need to split your data set into at least two different partitions,
- The data you use for training
- The data you use for testing
As you recall,
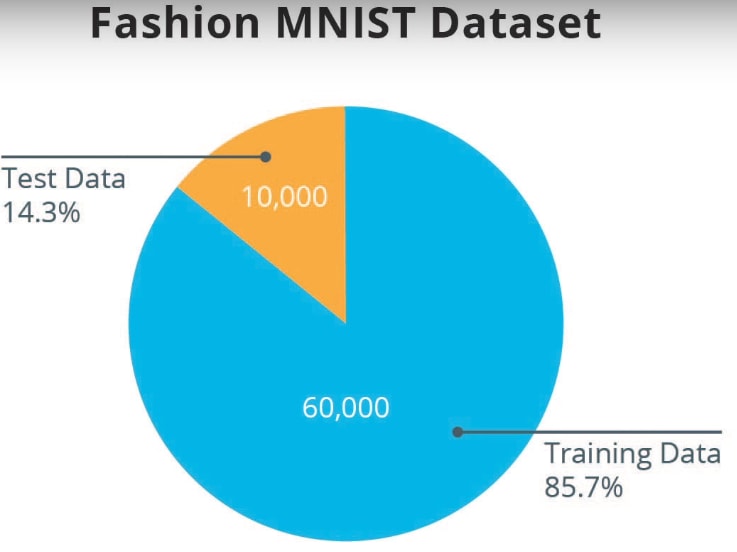
We had a total of 70,000 examples in the Fashion MNIST Dataset. We split this into
- 60,000 examples to use for training
- 10,000 to use for tests
The reason is that once a neural network has been trained, on the training data set, we want to test it on data that it hasn't seen before, to see how well it performs.

Actually, it is kind of like taking an exam in school. Before you take the exam, you usually train yourself on the task, by studying examples
Here are two exercises we might do to learn how to perform addition.

However, the test should not be on exactly the same exercises we studied. If that was the case, our strategy could be to memorize the exercises, instead of understanding how to perform addition in general. That's why the exam will have problems that you have never seen before.

In this way, it can be tested, if you have learned the general way of doing addition or not. The same happens with Machine Learning.
When you train a Machine Learning Algorithm, you show it some data that is representative of the problem you're trying to solve.
For Fashion MNIST, we want our neural network to be able to recognize 10 types of articles of clothing, such as sandals, t-shirts, and ankle boots, etc.
We therefore train it with 60,000 images containing such items.
Once the training is complete though, we want to test its performance on images he has never seen before. So we'll reserve 10,000 images for this purpose. If we did not do this, we wouldn't know if the neural network has decided to memorize the images it saw during training, or if it has truly been able to understand the difference between these items of clothing.
This is the reason why we always have a training set and a test set, when we do Machine Learning.
TensorFlow Datasets provides a collection of datasets ready to use with TensorFlow.
Datasets are typically split into different subsets to be used at various stages of training and evaluation of the neural network. In this section we talked about:
-
Training Set: The data used for training the neural network. -
Test set: The data used for testing the final performance of our neural network.
The test dataset was used to try the network on data it has never seen before. This enables us to see how the model generalizes beyond what it has seen during training, and that it has not simply memorized the training examples.
In the same way, it is common to use what is called a Validation dataset.This dataset is not used for training. Instead, it it used to test the model during training. This is done after some set number of training steps, and gives us an indication of how the training is progressing. For example, if the loss is being reduced during training, but accuracy deteriorates on the validation set, that is an indication that the model is memorizing the test set.
The validation set is used again when training is complete to measure the final accuracy of the model.
You can read more about all this in the Training and Test Sets lesson of Google’s Machine Learning Crash Course.
We will see the difference between "Celsius" and "Fashion Mnist" in the next one.

Top comments (0)