
Hey there,
Let's continue without furthur ado.
In order to understand how CNN's work with color images, we need to dive a little deeper into how CNN's work. So let's start by taking a quick recap.
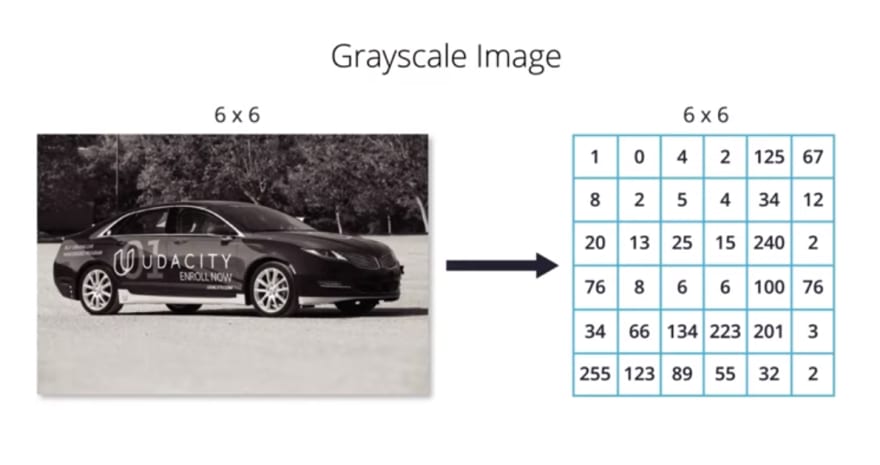
We saw in one of our previous lessons that computer interpret gray scale images as 2D arrays. This 2D arrays contain the corresponding pixel values of the gray scale images. The width and height of the 2D array will be determined by the size of the image. For example, let's assume for simplicity that this gray scale image is 6 pixels in width and 6 pixels in height. Therefore, the corresponding 2D array will also be 6 pixels in width and 6 pixels in height. In a similar manner, computers interpret color images as 3D arrays.

The width and height of the 3D array will be determined by the height and width of the image, and the depth will be determined by the number of color channels. Most color images can be represented by three color channels namely red, green and blue.
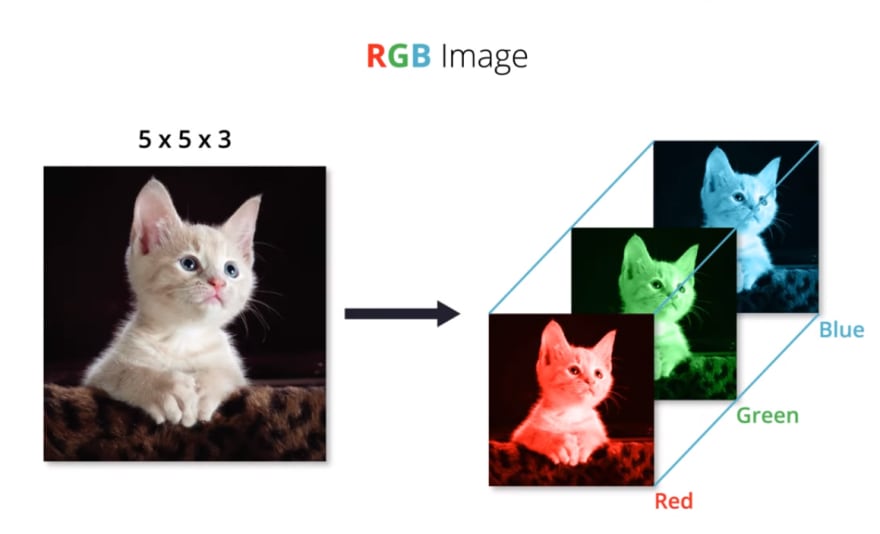
Images that contain red, green and blue color channels are known as RGB images. Altogether, these three channels combine to create a single color image. In RGB images, each color channel is represented by its own 2D array.
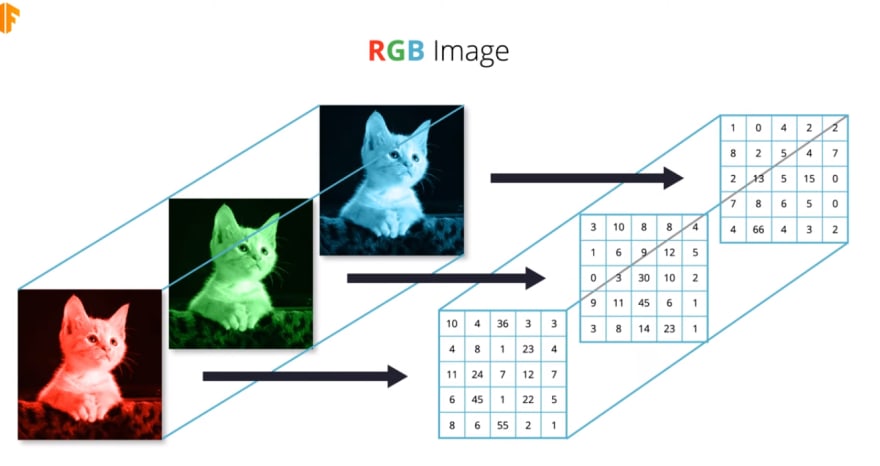
Since we have three color channels, we end up with 3 2D arrays. Therefore, in the case of RGB images, the depth of the 3D array is just the stack of these three 2D arrays corresponding to the red, green and blue color channels.
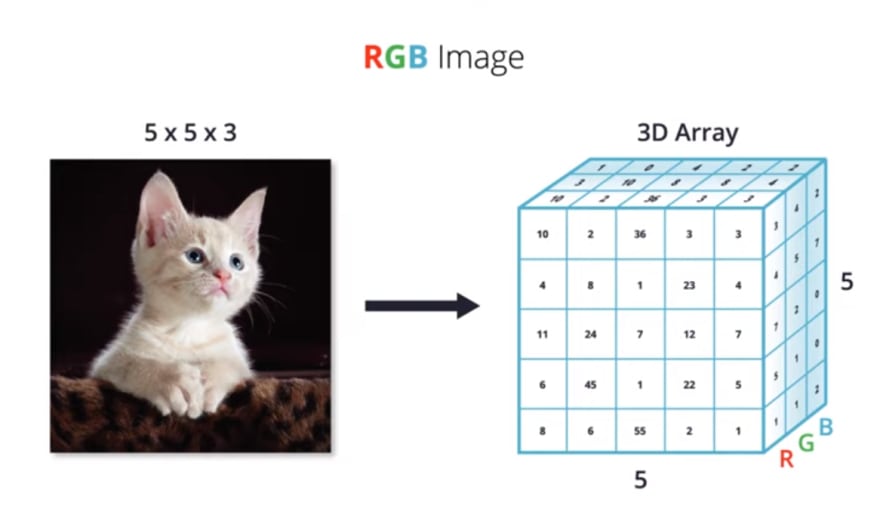
So in this particular example, where we have a five by five RGB image, the corresponding 3D array will be five pixels in height, five pixels in width and we'll have a depth of three
Now, since our input image is going to be 3D, we have to modify our code accordingly.
If we look at the code we used using in our previous lesson, we had an input shape of 28 by 28 by 1.

- The first two numbers in the input shape parameter refer to the height and width of the input image. In the Fashion MNIST dataset, the images were 28 pixels high, and 28 pixels wide.
- So the first two numbers are 28 and 28. The third number in the input shape parameter refers to the number of color channels.
- In the Fashion MNIST dataset, the images were grayscale which means they only have one color channel. Consequently, the last number here is a 1. But now, our dogs and cats dataset contains RGB images of different sizes.

- As mentioned earlier, we will resize all our images to be 150 pixels in height, and 150 pixels in width. Therefore, the first two numbers in the input shape parameter will now be 150 and 150.
- Since our images now are RGB, that means they have three color channels, which means we have to change the last number in the input shape parameter to three.
In the next post, we will learn how to perform convolutions on RGB images.

Top comments (1)
nice article. Could you say something of the source of those images? Did you create them? I need to know because I want to use that in one of my paper.