Recently I was tasked with getting to the bottom of an issue in one part of a system we were developing for a client. It required quite a bit of detective work, some experimentation, and ultimately learning. My type of challenge!
The part of the system that we were having trouble with was responsible for loading some tab-separated (TSV) data into Apache Solr. It worked on my machine. Even better, it also worked on our CI servers. It just wasn’t performing well under production data volumes.
To load the data into Solr, we were using a RegexTransformer with the Solr Data Import Handler (DIH). RegexTransformers allow you to specify a regular expression (regex) that defines how to parse each row in your data.
Our data set consists of around 2.5 million rows of Irish postal address information, with each row comprising up to 32 columns. It looks like the following:
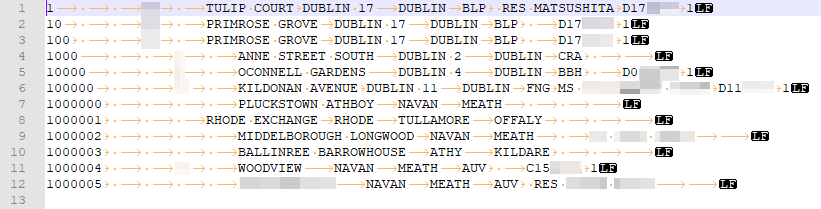
Tabs delimiters are shown as arrows, and each line ends with a line feed character.
The Solr DIH requires a mapping file, data-config-xml, to define how it should parse a given input file. The mapping file for our postal address input is shown below:
<dataConfig>
<dataSource name="fds" encoding="UTF-8" type="FileDataSource" />
<document>
<entity name="f" processor="FileListEntityProcessor"
baseDir="F:\dev\tools\solr-7.1.0\server\solr\input"
fileName=".*\.csv$"
recursive="false" rootEntity="false"onError="skip">
<entity name="input_data"
processor="LineEntityProcessor"
url="${f.fileAbsolutePath}"
format="text"
dataSource="fds"
transformer="RegexTransformer">
<field column="rawLine”
regex="^some_regexp$"
groupNames="column1_name,column2_name,column3_name,
column4_name,column5_name,column6_name,
column7_name,column8_name"/>
<field column="column1_name" name="solr_name1"/>
<field column="column2_name" name="solr_name2"/>
<field column="column3_name" name="solr_name3"/>
<field column="column4_name" name="solr_name4"/>
<field column="column5_name" name="solr_name5"/>
<field column="column6_name" name="solr_name6"/>
<field column="column7_name" name="solr_name7"/>
<field column="column8_name" name="solr_name8"/>
</entity>
</entity>
</document>
</dataConfig>
In the mapping file we describe each field (column) in the input file and its position. Note that the first XML element contains a “regex” attribute. The rest of this post discusses what value to give that attribute so that it parses address files correctly!
First Attempt: Naive Expression
Our first attempt looked like the following:
regex="^(.*)\t(.*)\t(.*)\t(.*)\t(.*)\t(.*)\t(.*)\t(.*)\t(.*)\t(.*)\t(.*)\t(.*)$"
This expression repeats the same capture group pattern (.*)\t the number of times required. Our test data only had 12 columns, so we replicated the capture group 12 times. No problem – it worked great. As our production data had 32 columns, we could simply replicate the capture group 32 times and we’d be good to go. Right? Wrong!
We were encountering a performance issue when processing larger (well wider) data sets – parsing slowed to the point where it seemed like the code was stuck in an infinite loop. Time to figure out what was going on.
Detective Work
As a Java developer I turned to my familiar toolbox. When faced with performance issues the first thing I go is to fire up a profiler such as Java VisualVM.
VisualVM connects to running Java processes using the Java Management Extensions (JMX) API. The Apache documentation explains how to use JMX with Solr. Once I’d done that, and restarted Solr, I was able to connect VisualVM to observe the behaviour of Solr while loading the TSV input file.
Here’s a step-by-step showing how to do this.
1. Start Java VisualVM
After a few seconds you’ll see the VisualVM window and in the “Applications” panel you’ll see the Solr JVM (“solr2” above). If it didn’t start automatically you can select “File | Add JMX Connection” and add Solr instance manually. In my case JMX connection properties were “service:jmx:rmi:///jndi/rmi://localhost:18983/jmxrmi”.
2. Start Solr Data Import
Next, start importing that 32-field input data file into Solr. Go to the Solr admin web page and “Execute” button as shown below.
Alternatively, you can run the the import from the command line:
$ curl http://localhost:8983/solr/<core_name>/dih?command=full-import
You can find full details on Solr import commands here in the Data Import Handler documentation.
3. Observe Solr in VisualVM
While the import is in progress switch to Java VisualVM, select the “Sampler” tab and then select “Thread CPU Time” tab. You will notice that one of the threads (“Thread-15” here) is consuming almost all CPU time.

Switch to the “CPU samples” tab you will see a summary table similar to the one below.

Here you’ll see that the RegexTransformer.readFromRegExp() method has the highest Self Time value.
4. Get a Thread Dump
Click the “Thread Dump” button to create a snapshot of the thread state. You can view this snapshot by clicking its name in the left panel. Search for “Thread-15” (or whatever your thread name was) and what you see will probably look very similar to the snippet below.
"Thread-15" - Thread t@52
java.lang.Thread.State: RUNNABLE
at java.util.regex.Pattern$CharProperty.match(Pattern.java:3778)
at java.util.regex.Pattern$Curly.match0(Pattern.java:4262)
at java.util.regex.Pattern$Curly.match(Pattern.java:4236)
at java.util.regex.Pattern$GroupHead.match(Pattern.java:4660)
at java.util.regex.Pattern$BmpCharProperty.match(Pattern.java:3800)
at java.util.regex.Pattern$GroupTail.match(Pattern.java:4719)
at java.util.regex.Pattern$Curly.match0(Pattern.java:4274)
at java.util.regex.Pattern$Curly.match(Pattern.java:4236)
at java.util.regex.Pattern$GroupHead.match(Pattern.java:4660)
at java.util.regex.Pattern$BmpCharProperty.match(Pattern.java:3800)
at java.util.regex.Pattern$GroupTail.match(Pattern.java:4719)
at java.util.regex.Pattern$Curly.match0(Pattern.java:4274)
at java.util.regex.Pattern$Curly.match(Pattern.java:4236)
at java.util.regex.Pattern$GroupHead.match(Pattern.java:4660)
at java.util.regex.Pattern$BmpCharProperty.match(Pattern.java:3800)
<snip - I deleted about 80 lines same like those above>
at java.util.regex.Pattern$Curly.match(Pattern.java:4236)
at java.util.regex.Pattern$GroupHead.match(Pattern.java:4660)
at java.util.regex.Pattern$Start.match(Pattern.java:3463)
at java.util.regex.Matcher.search(Matcher.java:1248)
at java.util.regex.Matcher.find(Matcher.java:637)
at org.apache.solr.handler.dataimport.RegexTransformer.readfromRegExp(RegexTransformer.java:147)
at org.apache.solr.handler.dataimport.RegexTransformer.process(RegexTransformer.java:127)
at org.apache.solr.handler.dataimport.RegexTransformer.transformRow(RegexTransformer.java:104)
at org.apache.solr.handler.dataimport.RegexTransformer.transformRow(RegexTransformer.java:42)
at org.apache.solr.handler.dataimport.EntityProcessorWrapper.applyTransformer(EntityProcessorWrapper.java:222)
at org.apache.solr.handler.dataimport.EntityProcessorWrapper.nextRow(EntityProcessorWrapper.java:280)
at org.apache.solr.handler.dataimport.DocBuilder.buildDocument(DocBuilder.java:476)
at org.apache.solr.handler.dataimport.DocBuilder.buildDocument(DocBuilder.java:517)
at org.apache.solr.handler.dataimport.DocBuilder.buildDocument(DocBuilder.java:415)
at org.apache.solr.handler.dataimport.DocBuilder.doFullDump(DocBuilder.java:330)
at org.apache.solr.handler.dataimport.DocBuilder.execute(DocBuilder.java:233)
at org.apache.solr.handler.dataimport.DataImporter.doFullImport(DataImporter.java:415)
at org.apache.solr.handler.dataimport.DataImporter.runCmd(DataImporter.java:474)
at org.apache.solr.handler.dataimport.DataImporter.lambda$runAsync$0(DataImporter.java:457)
at org.apache.solr.handler.dataimport.DataImporter$$Lambda$226/638797487.run(Unknown Source)
at java.lang.Thread.run(Thread.java:748)
Locked ownable synchronizers:
- locked <528a838d> (a java.util.concurrent.locks.ReentrantLock$NonfairSync)
Looking at the start of the stack trace it is clear that we are dealing with some kind of recursion or pseudo-infinite loop issue. Following the stack trace we can see that the regular expression processor is working very hard – there must be something wrong with the regex we’re using.
Now we know the location of the problem. Time to fix it!
The Solution
What was wrong with our regex pattern? In short, it was the asterisk "" character used in all of those capture groups. With regexes, more specific matching patterns are more performant than looser patterns. The more specific you are, the better. As a rule, you should always aim to replace the "." in "." with something more specific.
In our case, the ".*" scans to the end of an input row and will then backtracks to find the "\t" that follows the field. With 32 fields on each row it’s going to do that 32 times – for each row. This is known as a “Greedy” quantifier.
With this knowledge, we replaced each "(.)" capture group with "([^\t])". The result is:
regex="^([^\t]*)\t([^\t]*)\t([^\t]*)\t([^\t]*)\t…\t([^\t]*)$"
Instead of greedily consuming all input characters, this new capture group regex only consumes characters that are not tabs (the field delimiter). This means the parser does not need to backtrack, with the result that parsing performance is at least an order of magnitude faster.
If you’d like to learn more about greedy quantifiers have a look at RegEgg.

Oldest comments (0)