Introdução
Uma métrica que recebe bastante atenção no mundo do desenvolvimento é a porcentagem de cobertura dos testes, e quem está entrando na área de desenvolvimento e testes costuma não entender bem o que ela representa. "Nossa base de código está com 100% de cobertura de testes", "Não aceitamos pull requests que diminuam a taxa de código coberto" são frases ditas com orgulho quando alguém vai falar da cultura do seu time de desenvolvimento. E devem ser valorizadas mesmo, pois ter o código 100% coberto com testes é um grande feito na missão de ter uma base de código saudável, que faz o que foi especificado para ser feito e que dá confiança para ser modificado pelas pessoas que mexem nele. O que pretendo trazer nesse texto são algumas situações onde mostro que olhar apenas a porcentagem de cobertura de software não é uma boa ideia, ao mesmo tempo que tento jogar uma luz em como o código deve ser visualizado, entendido, pros comportamentos poderem ser entendidos plenamente, auxiliando na implementação dos testes. Na minha experiência ao ajudar pessoas júniors, uma das maiores dificuldades que elas têm é conseguir saber o que deve ser testado e como deve ser testado, e é o que vou tentar simplificar a seguir.
A armadilha dos 100%
A armadilha de ter 100% de cobertura é utilizar essa métrica como referência pra se confiar que o código está bem testado. Um código pode estar com os 100% de cobertura e não estar testado apropriadamente. Explico logo a seguir, mas antes quero deixar o aviso que tudo que vou falar aqui é na minha experiência de testes com Ruby (RSpec/Minitest/Sus) e o Simplecov (ferramenta para analisar a cobertura dos testes), e vou utilizá-los para exemplificar o que quero demonstrar, mas acredito que os mesmos conceitos se encaixam facilmente pra maioria das outras linguagens e ferramentas de testes, então vale a pena continuar lendo.
Vamos supor que uma aplicação tem o seguinte código:
class Products::Create
def call(attributes)
product = Product.new(attributes)
product.save!
Products::NotifyUsersJob.perform_later(product)
end
end
A classe acima é uma operação de criação de produto com um método #call, que recebe os atributos do produto, salva esse produto e depois envia notificação para os usuários sobre o lançamento daquele produto.
Um possível teste para essa operação seria:
RSpec.describe Products::Create do
it "creates new product" do
operation = Products::Create.new
expect do
operation.call({ title: "My product", price: 50.00 })
end.to change(Product, :count).by(1)
end
end
A estratégia do teste está sendo: Instanciar a operação, depois executá-la passando parâmetros válidos e verificar se a contagem de produtos aumentou em 1. O teste deverá passar com tranquilidade, mas pra nossa surpresa, a cobertura de teste ficará 100%.

Isso deveria ser uma surpresa pra quem não conhece o funcionamento de ferramentas como o Simplecov, pois o código utilizado como exemplo tem 2 funcionalidades: a criação de produto e envio de notificação aos usuários, mas o arquivo de testes está testando apenas o trecho da criação de produto, então na teoria não era pro código estar com 100% de cobertura, mas na prática foi isso que aconteceu. Pra entender melhor esse comportamento precisamos entender o funcionamento do Simplecov.
Como o Simplecov funciona?
O Simplecov (https://github.com/simplecov-ruby/simplecov) é uma gem que analisa a cobertura de código dos testes. Ao final da execução da bateria de testes da aplicação, o Simplecov fornece um relatório informando a porcentagem de linhas cobertas e uma visualização das linhas cobertas e não cobertas dos arquivos. Algo assim:
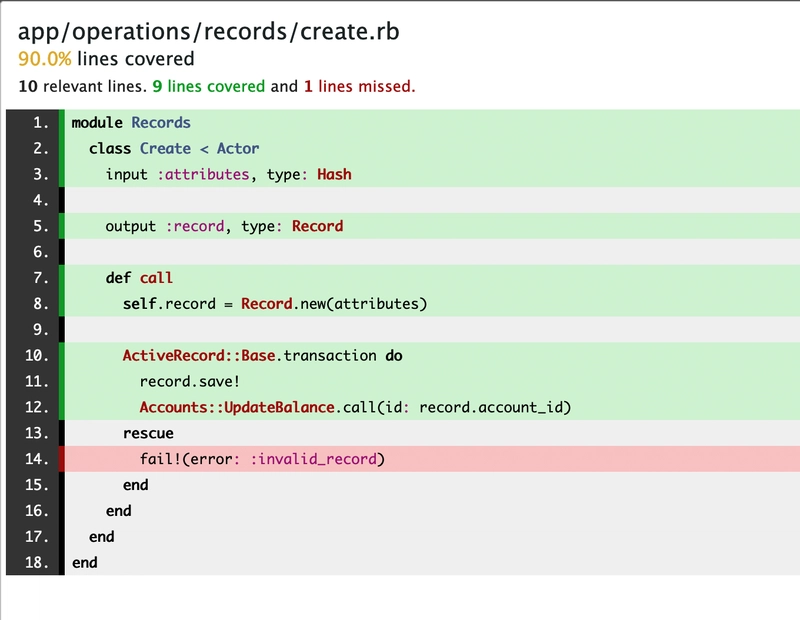
Na imagem acima, as linhas verdes são as linhas cobertas com testes, e a linha vermelha indica que não está coberta. Mas entender o que o Simplecov (e essas ferramentas de análise de cobertura) considera "coberto" e "não coberto" é a chave pra entender porque ele considerou aquele código anterior 100% coberto.
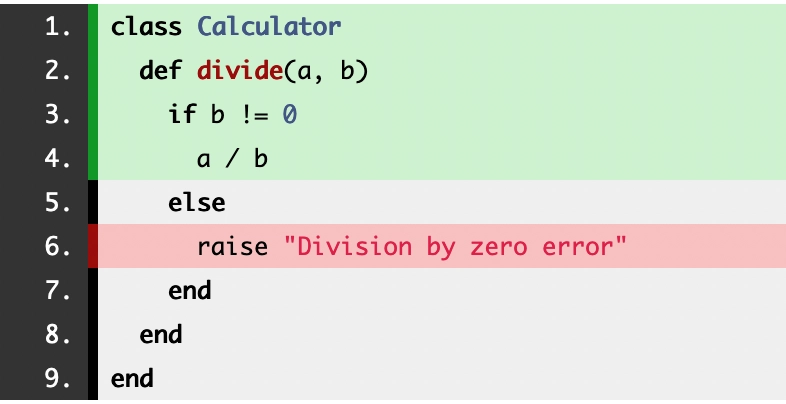
Pro Simplecov, uma linha de código está coberta quando um teste "passa" por ali, e não está coberta quando um teste "não passa" por ali. O "passar" entenda como executar o código em questão. Pra entender melhor vamos olhar para o código a seguir, é uma função de divisão que recebe 2 argumentos, a é o dividendo e b é o divisor, e que retorna o quociente. Mas caso o divisor seja 0, é lançado um erro. Também já tem logo na sequência o arquivo de teste, que está testando apenas a situação quando o divisor é diferente de zero:
class Calculator
def divide(a, b)
if b != 0
a / b
else
raise "Division by zero error"
end
end
end
# Arquivo de teste
RSpec.describe Calculator do
describe "#divide" do
it "returns the division of two numbers" do
calculator = Calculator.new
result = calculator.divide(10, 2)
expect(result).to eq 5
end
end
end
Testando apenas o caminho feliz, que é quando o divisor não é zero, ao executar os testes o Simplecov mostrou, corretamente, que a linha com raise "Division by zero error" não está coberta de testes. Isso está correto porque nos nossos testes, não criamos nenhum cenário onde o divisor era zero, e por isso o lançamento de erro nunca foi executado, ou seja, os testes "não passaram" por ali.
Então pra ter uma cobertura total do método de divisão, seria necessário criar esse cenário, esse contexto, onde o divisor seja zero e assim os testes consigam "passar" pelo lançamento de erro:
RSpec.describe Calculator do
describe "#divide" do
context "when b is different from zero" do
it "returns the division of two numbers" do
calculator = Calculator.new
result = calculator.divide(10, 2)
expect(result).to eq 5
end
end
# Novo contexto
context "when b is equal to zero" do
it "raises 'Division by zero error'" do
calculator = Calculator.new
expect do
calculator.divide(10, 0) # <= dividindo por 0
end.to raise_error("Division by zero error")
end
end
end
end

Então agora já entendemos que o Simplecov sabe se a linha de código está coberta verificando se aquela linha foi executada durante a bateria de testes. Isso explica porque ele considerou aquela operação de criação de produtos coberta 100%, pois ao fazer operation.call({ title: "My product", price: 50.0 }) dentro do teste, a linha Products::NotifyUsersJob.perform_later(product) foi executada, e consequentemente ficou marcada como coberta. E isso pode ser um grande problema.
O problema em se apoiar na % de cobertura
As ferramentas de cobertura se baseiam na execução das linhas de código e não se o comportamento foi testado
Como explicado, as ferramentas de cobertura se baseiam na execução das linhas de código e não se o comportamento foi testado. Então é possível ter 100% de cobertura sem ter algo testado apropriadamente. Aproveitando o exemplo já fornecido anteriormente mas alterando a implementação do teste:
class Products::Create
def call(attributes)
product = Product.new(attributes)
product.save!
Products::NotifyUsersJob.perform_later(product)
end
end
# Arquivo de teste
RSpec.describe Products::Create do
it "works" do
operation = Products::Create.new
operation.call({ title: "My product", price: 50.00 })
end
end
O teste deixou de verificar que era criado um produto, e agora só está executando o método sem fazer nenhuma verificação pra garantir o comportamento correto do método. Mesmo esse teste dessa forma, o relatório do Simplecov mostrará 100% de cobertura de testes.
Aí que mora o perigo de se confiar na métrica de cobertura de testes, pois como não é sobre os comportamentos testados, e sim sobre as linhas executadas, alguém pode remover uma linha por engano e ao executar a bateria de testes nenhum teste quebrará, e ainda assim a cobertura se manterá em 100%. No caso da operação de criação de produto, alguém pode refatorar o código, esquece de colocar de volta a linha que envia notificações aos usuários, e como não tem nenhum teste garantindo esse comportamento, estará tudo bem na bateria de testes, mas será um problema se esse código for pra produção, pois os usuários deixarão de receber os avisos de lançamento de produtos e, consequentemente, pode baixar a receita da empresa.
Pra corrigir essa falha de cobertura, é necessário testar também o envio de notificações aos usuários, e uma forma de testar poderia ser a seguinte:
RSpec.describe Products::Create do
it "creates new product" do
...
end
# Novo teste
it "notifies users" do
expect(Products::NotifyUsersJob).to receive(:perform_later).with(any_instance_of(Product))
operation = Products::Create.new
operation.call({ title: "My product", price: 50.00 })
end
end
O novo teste está verificando que o job de notificar usuários está sendo executado recebendo uma instância de produto. Talvez ainda não seja o teste ideal mas para a intenção do artigo já serve, pois o comportamento do envio de notificações. E se mesmo antes desse teste a cobertura estava 100%, com a adição do teste o cenário não mudou, continua 100%. Mas achou que finalmente a bateria de testes estava cobrindo todos os comportamentos do código? Achou errado, otário. É necessário enxergar os contextos implícitos.

Contextos implícitos
O exemplo do método #divide da calculadora tinha dois contextos bem claros, estava na cara: "Quando o divisor é zero" e "Quando o divisor não é zero". Isso é facilmente visível pela presença do if e else (o unless e elsif também ajudam a enxergar esses contextos). Pra facilitar a visualização desses contextos, podemos rascunhar um fluxograma, ficaria algo como:

Com o fluxograma conseguimos enxergar mais facilmente uma divisão de caminhos no comportamento desse método. Ao tomar uma decisão, que é verificar se o divisor é zero, o código segue por um caminho ou outro. Esses são os contextos. Quando sentir dificuldade de visualizar os contextos, você pode criar esses diagramas numa folha de papel, num programa ou mentalmente, todo código que você escreve é um processo e pode ser traduzido num fluxograma, e cada decisão que o código toma, pode ser entendido como um contexto, e esses contextos devem ser testados, ou pelo menos deveriam ser testados. Um exemplo mais complexo de código e seu fluxograma correspondente:
def shipping_label
if product.digital?
"Delivery via email"
elsif product.shipping_fee == 0
"Free shipping"
elsif current_user.premium?
"Free shipping (Premium subscriber)"
else
product.shipping_fee
end
end

Pelo fluxograma podemos enxergar que o código toma várias decisões e tem um fluxo bem ramificado. Então o teste desse código teria vários contextos, por exemplo: "Quando o produto é digital", "Quando o produto é físico e tem frete grátis", "Quando o produto é físico com taxa de frete e o usuário é assinante premium" e etc. Se os testes não refletirem esses cenários, grandes chances do código não estar testado apropriadamente.
Mas beleza, se esses contextos não eram fáceis de enxergar antes, com a explicação deve ter ficado um pouco mais claro. Mas tem os contextos que são "invisíveis", são implícitos, não tem um if/else ajudando a detectar. Por exemplo, começando por um fácil:
class User
def avatar_url
profile_picture_url || placeholder_avatar_picture_url
end
end
O código acima retorna a foto de perfil do usuário caso exista, e caso não exista será retornada uma url de uma placeholder pra não deixar o avatar vazio. Ao explicar o funcionamento do método já foi possível detectar dois contextos: "Quando o usuário tem foto de perfil" e "Quando o usuário não tem foto de perfil". Isso se deve porque o código anterior pode ser traduzido em:
def avatar_url
if profile_picture_url.present?
profile_picture_url
else
placeholder_avatar_picture_url
end
end
Os testes poderiam ser organizados assim:
describe "#avatar_url" do
context "when profile picture url is present" do
it "returns profile picture url" do
...
end
end
context "when profile picture url is blank" do
it "returns placeholder avatar picture url" do
"..."
end
end
end
Outro exemplo de um contexto implícito:
class User
def company_name
company&.name # ou company.try(:name)
end
end
O &. no Ruby é o safe navigation operator (no Rails pode ser utilizado o #try), serve pra executar o método apenas quando o objeto em questão estiver presente, evitando a chamada de um método numa referência nula. Então podemos entender que o #company_name tem 2 contextos: "Quando a empresa está presente" e "Quando a empresa não está presente". O código anterior poderia ser escrito também assim:
class User
def company_name
if company.present?
company.name
else
nil
end
end
end
E os testes em ambos os casos seriam:
describe "#company_name" do
context "when company is present" do
it "returns company name" do
...
end
end
context "when company is blank" do
it "returns nil" do
"..."
end
end
end
Agora contextos um pouco mais difíceis de enxergar:
class Posts::Publish
def call(id)
post = Post.find(id)
post.update(state: :published, published_at: Time.zone.now)
end
end
Um fluxograma mais descuidado poderia ser feito assim:

O fluxo acima está parcialmente correto porque está registrando apenas o caminho feliz da execução, mas caso a atualização do post falhe o que acontece? O fluxo não está considerando isso, e esse é um dos contextos implícitos. Vamos corrigir o fluxograma:

Agora o fluxo considera que a atualização pode falhar e assim tem dois contextos: "Quando a atualização é bem sucedida" e "Quando a atualização falha". Mas ainda tem outro contexto implícito que é: E se o post não existir na base de dados? Vamos atualizar o fluxograma pra incluir esse cenário:

Agora o fluxo está completo, e podemos perceber que mesmo o método tendo apenas 2 linhas, sem nenhuma condicional, é representado por um fluxo com 3 caminhos diferentes. Isso é devido aos contextos implícitos, que diferente dos if/else, você precisa entender o funcionamento interno dos métodos utilizados pra saber, por exemplo, se uma exceção será lançada e se o método retorna diferentes coisas dependendo da execução, que é o caso do find e do update, mas poderia ser qualquer outro método.
Com os contextos detectados, poderíamos escrever os testes pra esse método da seguinte forma:
RSpec.describe Posts::Publish do
context "when post with given id cannot be found" do
it "raises ActiveRecord::RecordNotFound error" ...
end
context "when update is successful" do
it "publishes post" ...
it "returns true" ...
end
context "when update fails" do
it "doesn't publish post" ...
it "returns false"
end
end
Se o fluxo não tivesse sido destrinchado e fossémos utilizar a primeira versão pra implementar nossos testes, teria ficado algo assim:
RSpec.describe Posts::Publish do
it "publishes post" ...
end
E no Simplecov, ambos os testes resultariam em 100% de cobertura do método. Mas qual você abordagem você acha que garante melhor o funcionamento do código? Pra mim é o teste com os três contextos. Por isso reforço que a % cobertura de teste por si só não é relevante pra medir a qualidade dos testes, é necessário um melhor entendimento do que está sendo testado por parte da pessoa que está escrevendo código e por parte das pessoas que vão revisar aquele código, assim os testes "meia boca" podem ser detectados e melhorados.
E ainda há outros tipos de contexto implícito, tipo esse:
def call
ActiveRecord::Base.transaction do
Customer.create!(...)
Store.find(...).update(...)
end
end
O código acima cria um cliente e depois atualiza a loja. O contexto implícito além do create!, que pode gerar uma exceção, é que caso ocorra uma falha na atualização da loja, a criação do cliente deve ser desfeita devido à criação e atualização estarem englobados numa transação do banco de dados. Então se isso for um requisito do código, o ideal é que haja um teste cobrindo esse comportamento, pois se alguém remover essa transaction, deve receber um aviso que está alterando o comportamento do código.
E vão ter outros contextos não tão implícitos assim mas que vale a pena citar rapidamente:
# um if inline continua tendo 2 contextos
button_class = "active" if post.featured?
# um if ternário continua tendo 2 contextos
submit_text = product.persisted? ? "Update" : "Create"
Em ambos os casos o Simplecov por padrão tratará a linha como coberta, mesmo se o teste não cobrir os diferentes cenários.
Então voltando pro nosso primeiro exemplo, da operação de publicação de produto, temos um contexto implícito lá, que é ao utilizar o #save!, caso os atributos sejam inválidos, uma exceção será lançada e a execução do método abortada. Então atualizando nossos testes pra considerar essa situação, seria algo como:
RSpec.describe Products::Create do
context "with valid attributes" do
it "creates new product" ...
it "notifies users" ...
end
# novo contexto
context "with invalid attributes" do
it "raises ActiveRecord::RecordInvalid error" ...
it "doesn't notify users" ... # <= maior segurança aqui
end
end
E agora podemos considerar que nossos testes estão suficientes, pois verifica se com os parâmetros válidos, o produto está sendo criado e as notificações disparadas, e com os parâmetros inválidos, verificamos o lançamento da exceção e que nenhum usuário foi notificado.
Paranóia
Gosto de dizer pras pessoas que ajudo a se desenvolver na programação que o objetivo dos testes é fazer o código ser à prova de sabotagem. O "sabotador" pode ser uma pessoa do time, uma pessoa nem entrou mas ainda vai entrar no time, ou até mesmo a própria pessoa que no futuro precisará voltar pra dar manutenção naquele código. O teste deve detectar se mesmo após as modificações realizadas no código, o código está fazendo o que foi especificado pra fazer. Utilizando ainda a operação de publicação de produto como exemplo:
class Products::Create
def call(attributes)
product = Product.new(attributes)
product.save!
Products::NotifyUsersJob.perform_later(product)
end
end
Se a pessoa ao dar manutenção no código, remover sem intenção a linha de disparo de notificações, o teste deve quebrar pois um requisito era enviar notificação aos usuários após a criação do produto. Se trocar o save! pelo save, o teste deve quebrar, pois sem isso o código disparará as notificações mesmo quando o produto estiver inválido, fazendo os usuários receberem notificações de produto que não existe. Geralmente esses erros acontecem por desatenção, por não conhecer a base de código, e o papel do teste é defender o funcionamento do código.
Há lendas de que na Netflix existe o Macaco do Caos, um serviço na infraestrutura que desliga um servidor da empresa propositalmente pra verificar se os sistemas continuam funcionando, se adaptando à situação sem intervenção manual e sem causar nenhum impacto ao usuário final. Depois isso evoluiu pra um exército de macacos que fazem diferentes tipos de sabotagem, como diminuir o tempo de resposta de um serviço, por exemplo. Então podemos assumir que os times de desenvolvimento são compostos por vários macacos do caos bem intencionados, ou seja, o propósito deles não é causar um problema intencionalmente, mas sim adicionar novas funcionalidades, corrigir problemas, mas devido à natureza do desenvolvimento de software, estão suscetíveis a adicionar problema no código, e a função dos testes é ser à prova de macacos do caos, aumentando as chances de códigos defeituosos serem detectados antes de chegarem em produção e causarem efeitos colaterais aos usuários da aplicação.
Então a mentalidade ao escrever testes deve ser:
- Primeiro entender o que o código faz
- Identificar os contextos explícitos e explícitos
- Definir o que é essencial no funcionamento do código
- Garantir, com testes, que o código está fazendo o que é pra fazer
Dessa forma, quando alguém alterar o código e quebrar algo, será avisado que sua alteração mudou o comportamento da aplicação, se for algo intencional, os testes devem ser alterados pra refletirem o novo comportamento, ou o código deve ser corrigido pra manter o comportamento original.
Dependendo do nível de paranóia de quem está implementando os testes, proteger o código com testes pode ser bem trabalhoso. Vamos utilizar uma método de soma como exemplo:
class Calculator
def sum(a, b)
a + b
end
end
# Arquivo de teste
RSpec.describe Calculator do
describe "#sum" do
it "returns the sum of two numbers" do
calculator = Calculator.new
result = calculator.sum(5, 2)
expect(result).to eq 7
end
end
end
O teste está bem direto, verifica que chamando o #sum com 5 e 2, retorna 7. Isso já garante que a soma está funcionando como deveria. Mas seguindo a ideia de que tem vários macacos do caos no time, algum deles no futuro poderia alterar o método #sum pra algo assim:
class Calculator
def sum(a, b)
7
end
end
Os testes não quebrariam mesmo com o código claramente errado. Então pra se proteger dos macacos do caos os testes poderiam ser ajustados:
RSpec.describe Calculator do
describe "#sum" do
it "returns the sum of two numbers" do
calculator = Calculator.new
expect(calculator.sum(5, 2)).to eq 7
expect(calculator.sum(59, 5)).to eq 64
expect(calculator.sum(-2, 2)).to eq 0
# ou
a = rand(100)
b = rand(100)
expect(calculator.sum(a, b)).to eq a + b
end
end
end
Pronto, agora já está evitando que seja colocado um número fixo no retorno do método, e o agora teste avisará ao macaco do caos que aqui ele não se cria. Mas toda vez que cria uma defesa pra esses casos, podem surgir vários outros, exemplo:
class Calculator
def sum(a, b)
if a == 5 && b == 2
return 7
elsif a == 59 && b == 5
return 64
elsif a == -2 && b == 2
return 0
else
User.delete_all
a + b
end
end
end
O macaco do caos, que parece estar bem mal intencionado agora, conseguiu burlar sua proteção, e ainda colocou algo mais perigoso, colocou um código que destrói toda sua base de usuários, e o teste está passando sem problemas. Claro, tudo isso é ficção, esse tipo de coisa não vai acontecer em times saudáveis, mas serve pra mostrar que não é possível defender seu código de todas as possíveis alterações que podem ser feitas, principalmente garantir que coisas não esperadas não foram feitas, e que é improdutivo se tentar alcançar esse nível de defesa. Mas de toda forma, é possível colocar algumas garantias em contextos relevantes que são mais propícios de acontecer, por exemplo, garantir que um e-mail não foi enviado caso o produto esteja inválido, garantir que o item de pagamento mudou o status para reembolsado ao chamar com sucesso o endpoint de reembolso da API de gateway, e etc.
Conclusão
No fim, testar código é uma arte, uma habilidade que pode e precisa ser desenvolvida, é um jogo onde você sempre está negociando clareza e legibilidade contra segurança e rigidez. Testes são códigos da aplicação e também recebem manutenção, também são lidos, e é necessário ver até onde faz sentido degradar a legibilidade e manutenibilidade pra garantir um teste, às vezes desnecessariamente, mais seguro. Há pontos cruciais da aplicação que você precisa cobrir todos os contextos e todos os retornos pois se algo ali mudar, pode dar problema sério, geralmente são os pontos que geram dinheiro pra empresa, como o login, checkout de pagamento, ou que podem fazer a empresa perder muito dinheiro, como uma falha de segurança ou vazamento de dados. E tem outros códigos que são menos críticos e que você pode só testar que funciona sem quebrar pois se eles um dia deixarem de funcionar, o estrago será pequeno, sendo corrigido facilmente, não há nada de errado em ter testes frágeis nesses casos. Também há outros mecanismos que auxiliam a evitar problemas maiores, mais cedo, antes de um eventual problema se tornar um problema crítico, como na revisão de código dos pull requests, QA manual/automático, ambiente de staging/homologação, feature flags na liberação de novas funcionalidades antes de liberar para o público geral e etc, então o desafio é sempre encontrar um modelo de desenvolvimento sustentável da base de código.

Top comments (0)