What is Web Scraping?
Web scraping allows you to unlock a treasure trove of data from the internet. It involves using software or programming code to access and gather data from web pages, which can then be processed, analyzed, or stored for various purposes. It allows users to retrieve specific pieces of information from websites in a structured and organized manner.
Heed of Warning
Before moving on, it's important to note that websites implement various protections to deter web scrapers and ensure fair and responsible use of their resources. A couple ways to ensure you're scraping the web ethically is by reading the robots.txt file that most websites have. Here is an example of https://www.apple.com/robots.txt:

Another way of keeping unwanted web scrapers out of one's website is with the well-known CAPTCHA verification that most people are familiar with.
Getting Started
import requests
from bs4 import BeautifulSoup
Beautiful Soup is a Python library used for web scraping purposes to pull the data out of HTML and XML files.
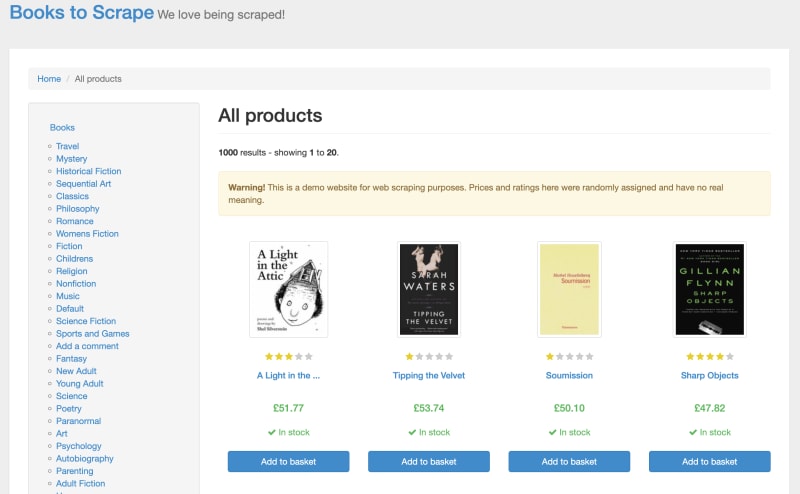
url = "http://books.toscrape.com/"
response = requests.get(url)
There's a variety of websites on the internet thats sole purpose is to act as practice for web scraping. I'm using toscrape.com that mimics an online store to capture the prices of the products stored on the website. The method requests.get() sends a request to the website.
soup = BeautifulSoup(response.text, "html.parser")
After sending your request, you'll need to create a BeautifulSoup object to parse the HTML of the website.
prices = soup.find_all("p", class_="price_color")
titles = soup.find_all('article')
title_list = []
price_list = []
title_text_list = []
for price in prices:
price_list.append(price.text)
for title in titles:
title_list.append(title.find_all('h3'))
for book_title in title_list:
title_text_list.append(book_title[0].text)
all_books = dict(zip(title_text_list, price_list))
for title, cost in all_books.items():
print(title, cost)
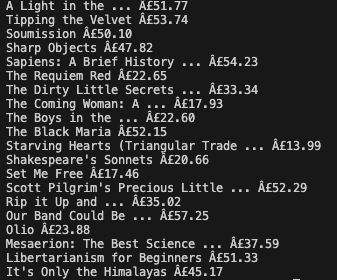

Lastly, in order to find the elements that we need, we'll need to refer to the DOM of the page we're scraping. If we want to find the the titles of the books as well as the prices, we can use the find_all() method for the 'p' element and 'article' element since that is where our information lives on the page. We then loop through all of the elements and save the texts of the elements in a list using .text().
From there, I was able to create a dictionary with the names of the books as the key and the price as the value.
Conclusion
Web scraping with Python and Beautiful Soup is a valuable skill for any software engineer. It opens the door to a wealth of data that can be harnessed for various purposes. As you explore this world, remember to respect websites' terms of service and robots.txt files, and always scrape responsibly and ethically.
Resources
https://www.geeksforgeeks.org/what-is-web-scraping-and-how-to-use-it/

Top comments (0)