The original article is here
Today, let’s discuss resiliency in microservices architecture. In general, services could communicate with each other via a synchronous or asynchronous way. We assume that dividing a big monolithic system into smaller chunks will help to decouple service’s responsibility. In reality, it may be harder to manage inter-service communication. There are two well-known concepts you may hear about it: circuit breaker and retry.
Circuit breaker
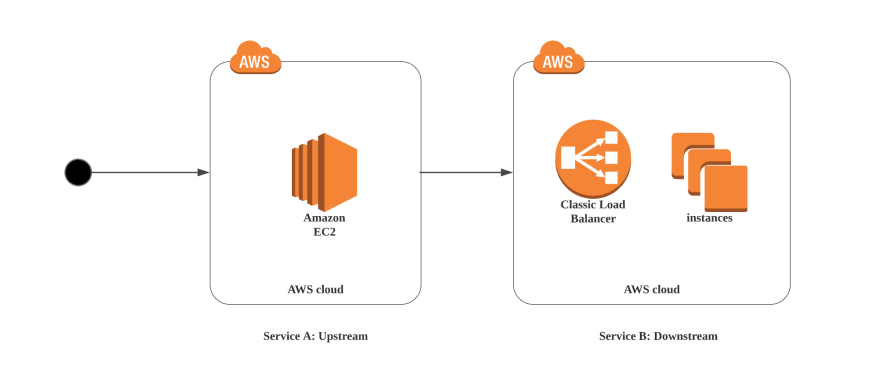
Imagine a simple scenario where requests from users call service A and subsequently call another service. We could call B as a dependent service of A or downstream service. A request coming to service B will go through a load balancer before propagating to different instances.
System fault in backend services could happen due to many reasons. For example, slow database, network blip or memory contention. In this scenario, if a response to service A is either timeout or server error, it may make our user try again. What we could do to protect downstream services in chaos situations.
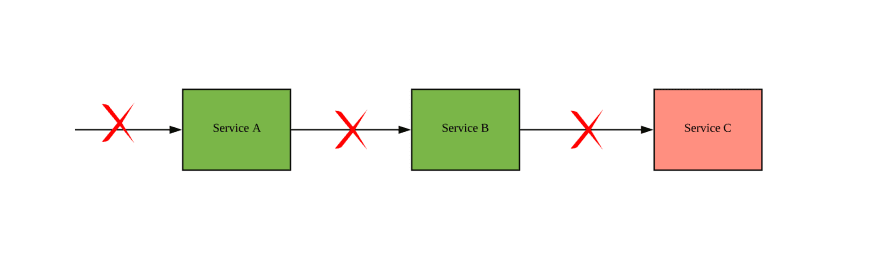
Circuit breaker provides more control over failure rate and resources. The design of circuit breaker handles the error quickly and gracefully without waiting for TCP connection timeout. This fail-fast mechanism will protect downstream layer. The most important part of this mechanism is that we’re immediately returning some response to the calling service. No thread pools filling up with pending requests, no timeouts, and hopefully fewer annoyed end-consumers. Also, it gives enough time for downstream service to recover. It is hard to prevent fault completely, but it is possible to reduce the damage of failures.
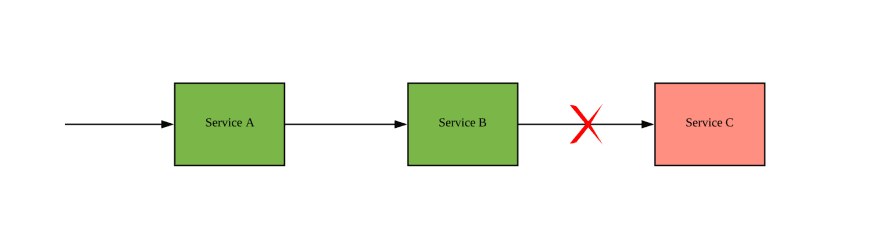
By using hystrix circuit breaker, we could add a fall back behaviour in upstream service. For example, service B could access a replica service or cache instead of calling service C. Introducing this fallback approach requires integrating testing as we may not encounter this network pattern in a happy path.
States
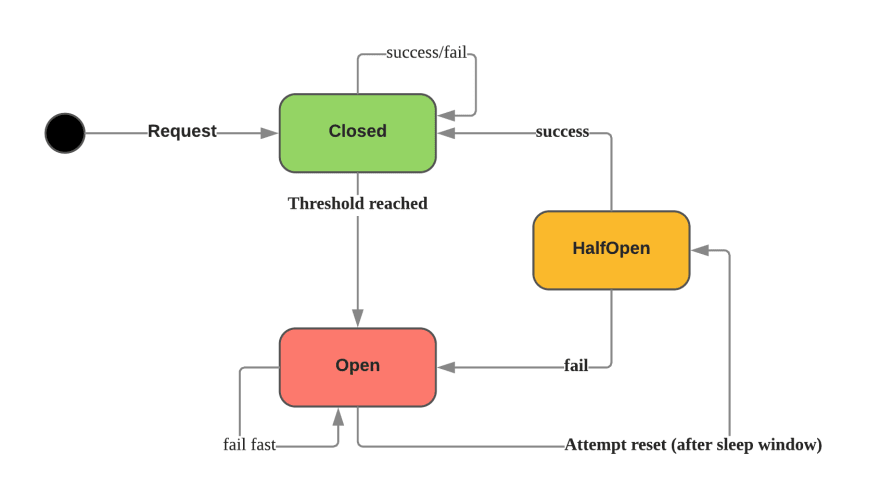
There are 3 main states in circuit breaker:
- Closed: default state which let requests go through. If a request is successful/failed but under a threshold, the state remains the same. Possible errors are Max Concurrency and Timeout errors.
- Open: all the requests will be marked as failed with error Circuit Open. This is a fail-fast mechanism without waiting for timeout time to finish.
- Half Open: periodically, an attempt to make a request to check the system has recovered. If yes, circuit breaker will switch to Closed state or remain at Open state.
Circuit breaker In Theory
Here are 5 main parameters to control circuit setting.
Threshold's value could be derived from SLA agreement between 2 services. These values should be fine tune while testing on staging by putting other dependencies into context
A good circuit breaker name should pinpoint the right service connection has trouble. In reality, you may have many API endpoints to connect with one service. It is reasonable to attach each endpoint with a separate circuit breaker.
Circuit breaker In Production
A circuit breaker is usually placed in integration points. Even circuit breaker provides a fail-fast mechanism, we still need to verify the alternative fallback is working. It is a waste of effort if we don't ever test the fallback solution as we may assume it is a rare case. In the simplest dry run, we also need to make sure the threshold is valid too. In my personal experience, printing out the config of parameters in the log will help to debug easier.
Demo
This sample code use hystrix-go library, which is an implementation of hystrix Netflix library in Golang.
To run the demo, you can see 2 experiments with the circuit closed and open:
Retry problem
From the circuit breaker model above, what will happen when service B downsize its number of instances. Many existing requests from A probably get 5xx errors. It could cause a false alarm to open the circuit breaker. That is why we need retry to avoid intermittent network hiccups.
A simple code for retry can be like this:
Retry patterns
To achieve optimistic concurrency control, we could orchestrate different services to retry at different times. Retrying immediately may not be used as it creates a burst number of requests upon dependent services. Adding a backoff time will help to ease this stressful situation. Some other patterns randomize backoff time (or jitter in waiting period).
Let's consider those following algorithms:
- Exponential: base * 2^attempt
- Full Jitter: sleep = rand(0 , base* 2^attempt)
- Equal Jitter: temp = base * 2^attempt; sleep = temp/2+rand(0 , temp/2)
- De-correlated Jitter: sleep = rand(base, sleep*3);
There is a correlation between the number of clients vs the total number of workloads and completion time. To determine what is suitable best for your system, it is worth to benchmark when the number of clients increases. The detailed experiment can be found in this article. My recommendation is between decorrelated jitter and full jitter.
Combination of both tools
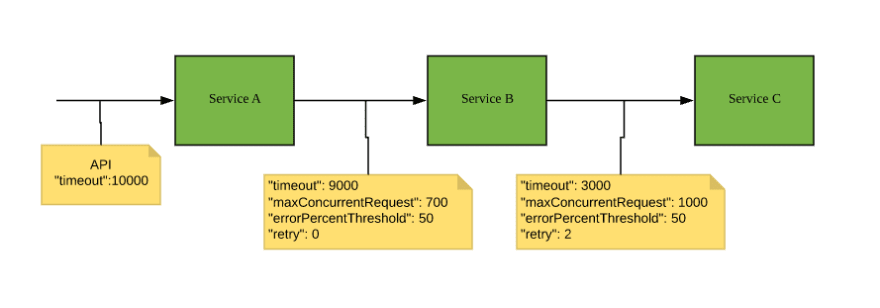
Circuit breaker is commonly used in stateless online transaction systems, especially at the integration points. Retry should use for scheduling jobs or workers which are not constraint by timeout. We can use both at the same time with careful consideration. In a large system, service mesh will be an ideal architecture to better orchestrate different configurations at scale.

Oldest comments (0)