
Introduction
Today I am going to run you through a few different types of vectorizers and encoders that I have found very helpful for changing your text based data into numerical data. To be specific I would like to cover One Hot Encoders, Count Vectorizers and TF-IDF Vectorizers.
One Hot Encoder
One Hot Encoder is fairly simple and used for categorial variables. What it does is that it changes all of the distinct values from your text data into columns and add 1's or 0's to show if that value is present or not. For Example let's create a data frame of some different colors try it out:
import pandas as pd
categor_data = ['blue','purple','orange','purple']
colors_df = pd.DataFrame(categor_data, columns=['Colors'])
Now lets run the One Hot Encoder:
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder()
transformed = pd.DataFrame(ohe.fit_transform(colors_df).toarray(),columns=ohe.categories_)
transformed.set_index(pd.Index(categor_data))
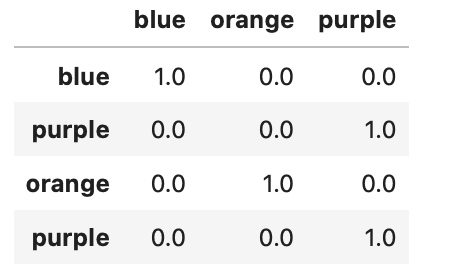
So as you can see we now have the distinct values as the columns and whether they are present or not in each row.
Count Vectorizer
Count Vectorizer is similar to One Hot Encoder except that instead it being used to just adding a 1 or 0 into a column if a word is present, it will count the number of times the word is present in a collection of words and create a sparse matrix of the counts of the appearances in the respective row. So instead of using this technique on categorial data, it would be used for natural language processing on text documents.
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'sam sam is super happy',
'sam sam is very sad',
'sam sam is scary angry',
]
vectorizer = CountVectorizer()
transformed = pd.DataFrame(vectorizer.fit_transform(corpus).toarray(),columns=vectorizer.get_feature_names())
transformed
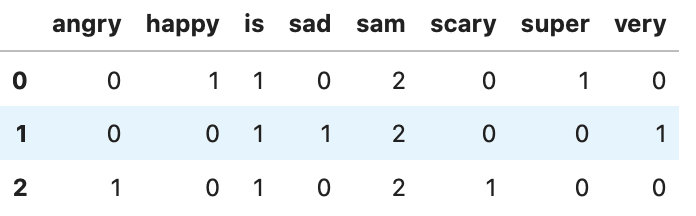
In this example we can see that we again have the different words as the columns but we have the count of how many times a word appeared in each document.
TF-IDF Vectorizer
The count vectorizer can now help us understand the TF-IDF Vectorizer, but first lets talk about what TF-IDF stands for. TF-IDF or Term Frequency - Inverse Document Frequency is a algorithm to transform text into a meaningful representation of numbers. The equation is:

Which is telling us that the algorithm is returning the number of times that a term appeared in a document and multiplying it by the log of the number of documents over the the number of documents that term appeared in. This gives us an idea of the importance how important certain words are to their documents and give less importance to words being used a lot between all of the documents, helping your machine learning algorithm's prediction to focus on the differences between the documents.
So let's use the same data we used in the Count Vectorizer example so we can see the difference.
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer()
transformed = pd.DataFrame(vectorizer.fit_transform(corpus).toarray(),columns=vectorizer.get_feature_names())
transformed

Take a look at how the algorithm is working by first comparing the columns 'is' and 'sam' since they both both appear is each document. From the word 'is' we are getting a value of .305 and from 'sam' we are getting .610, this is because the the inverse document frequency is the same for both words but we are seeing the term 'sam' twice as much in each document than we are 'is'. If we look at the rest of the words now, we can see that they only appear once in each document but they are not repeated in any of the other documents, therefore the term frequency is the same as the word 'is' in each document but the inverse document frequency will be a larger number since they are not repeated between the documents. So the words that are unique to each document will be greater than words appearing in each document that have the same frequency.
Conclusion
When I was starting to learn about Natural Language Processing it took me awhile to understand the differences and uses for these different tools. So I hope this helps with understanding the uses and differences of these techniques.

Top comments (0)