FLaNK: Flink SQL Preview
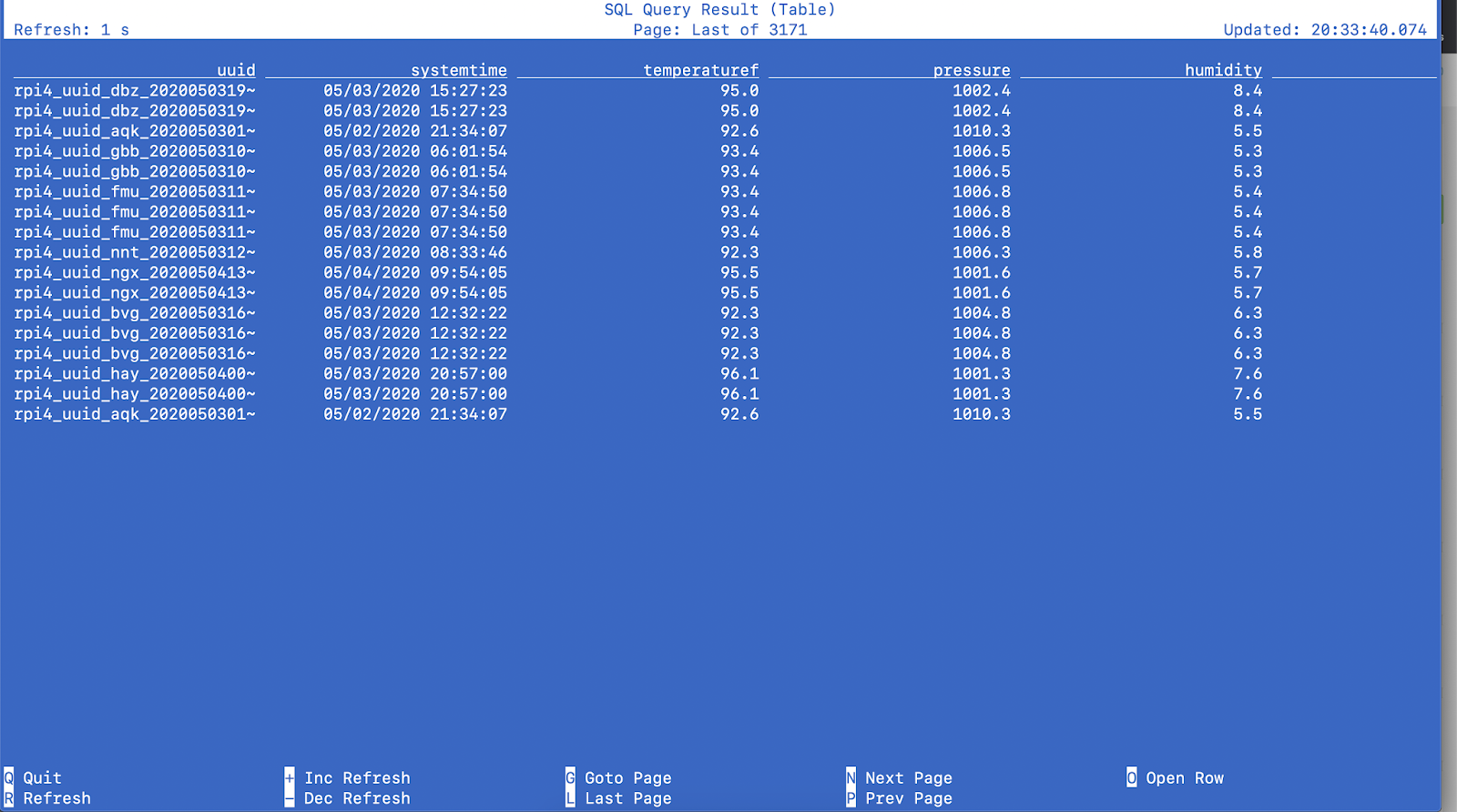
From our Web Flink Dashboard, we can see how our insert is doing and view the joins and records passing quickly through our tiny cluster.
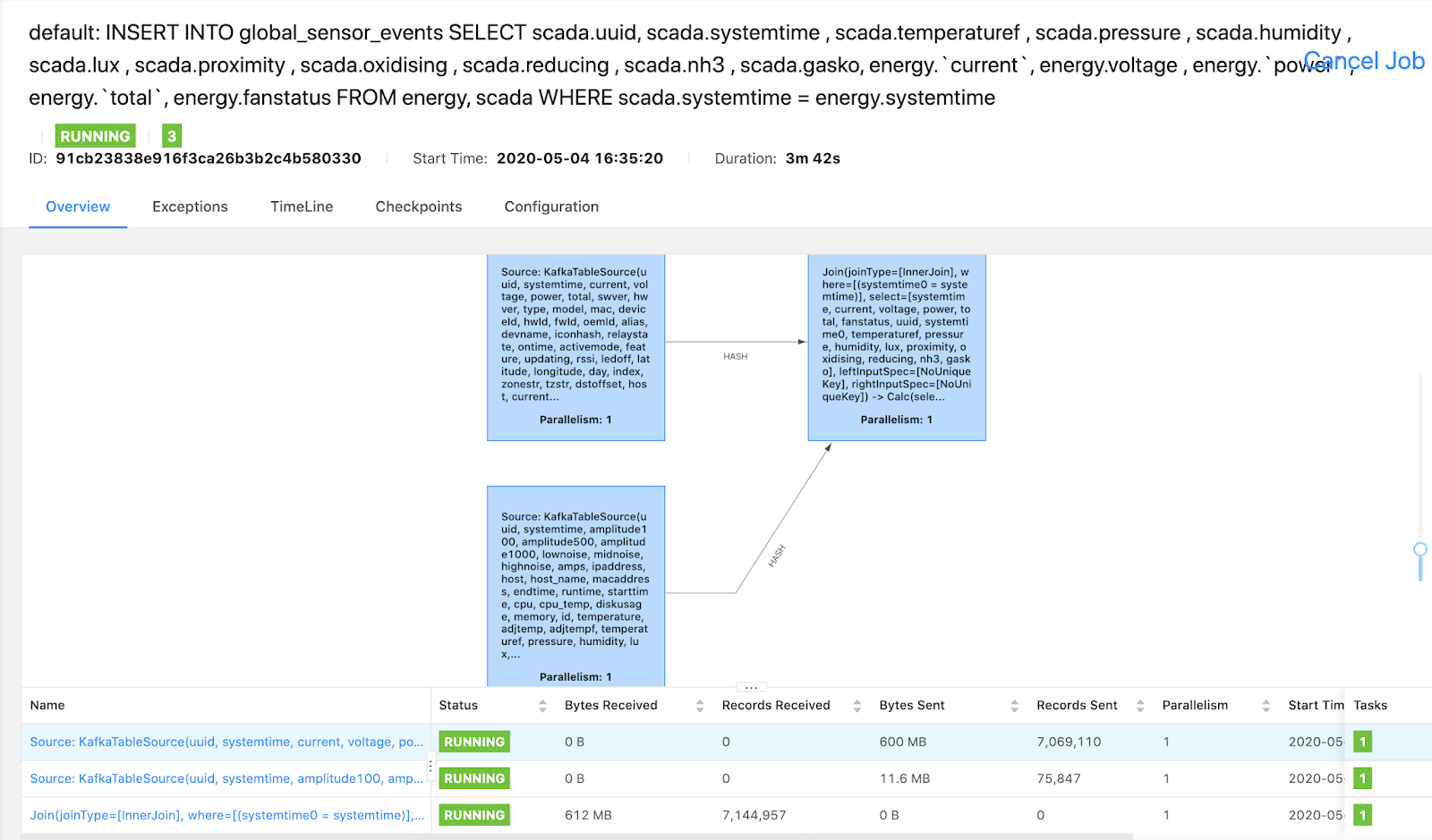
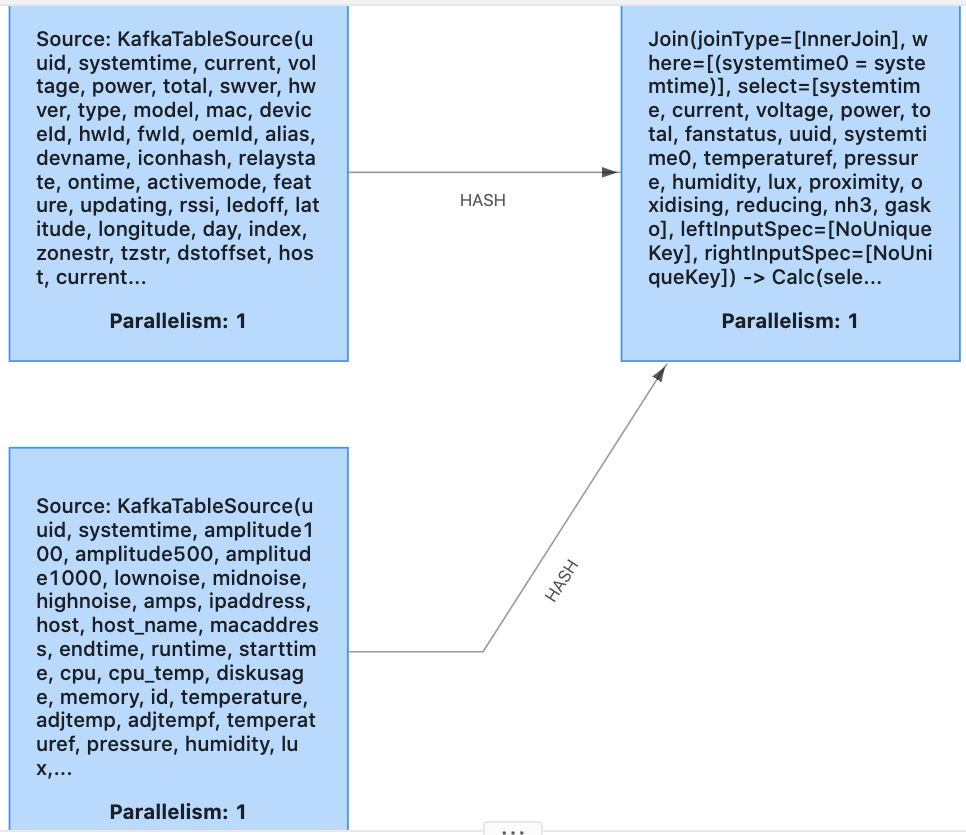
See: https://github.com/tspannhw/meetup-sensors/blob/master/flink-sql/test2.ddl
As part of the May 7th, 2020 Virtual Meetup, I was doing some work with Flink SQL to show for a quick demo as the introduction to the meetup and I found out how easy it was to do some cool stuff. This was inspired by my Streaming Hero, Abdelkrim, who wrote this amazing article on Flink SQL use cases: https://towardsdatascience.com/event-driven-supply-chain-for-crisis-with-flinksql-be80cb3ad4f9
As part of our time series meetup, I have a few streams of data coming from one device from a MiNiFi Java agent to NiFi for some transformation, routing and processing and then sent to Apache Flink for final processing. I decided to join Kafka topics with Flink SQL.
The sensor data: https://www.datainmotion.dev/2020/04/predicting-sensor-readings-with-time.html
Let's create Flink Tables:
This table will be used to insert the joined events from both source Kafka topics.
CREATE TABLE global_sensor_events (
uuid STRING,
systemtime STRING ,
temperaturef STRING ,
pressure DOUBLE,
humidity DOUBLE,
lux DOUBLE,
proximity int,
oxidising DOUBLE ,
reducing DOUBLE,
nh3 DOUBLE ,
gasko STRING,
current INT,
voltage INT ,
power INT,
total INT,
fanstatus STRING
) WITH (
'connector.type' = 'kafka',
'connector.version' = 'universal',
'connector.topic' = 'global_sensor_events',
'connector.startup-mode' = 'earliest-offset',
'connector.properties.bootstrap.servers' = 'tspann-princeton0-cluster-0.general.fuse.l42.cloudera.com:9092',
'connector.properties.group.id' = 'flink-sql-global-sensor_join',
'format.type' = 'json'
);
This table will hold Kafka topic messages from our energy reader.
CREATE TABLE energy (
uuid STRING,
systemtime STRING,
`current` INT,
voltage INT,
power INT,
total INT,
swver STRING,
hwver STRING,
type STRING,
model STRING,
mac STRING,
deviceId STRING,
hwId STRING,
fwId STRING,
oemId STRING,
alias STRING,
devname STRING,
iconhash STRING,
relaystate INT,
ontime INT,
activemode STRING,
feature STRING,
updating INT,
rssi INT,
ledoff INT,
latitude INT,
longitude INT,
day INT,
index INT,
zonestr STRING,
tzstr STRING,
dstoffset INT,
host STRING,
currentconsumption INT,
devicetime STRING,
ledon STRING,
fanstatus STRING,
end STRING,
te STRING,
cpu INT,
memory INT,
diskusage STRING
) WITH (
'connector.type' = 'kafka',
'connector.version' = 'universal',
'connector.topic' = 'energy',
'connector.startup-mode' = 'earliest-offset',
'connector.properties.bootstrap.servers' = 'tspann-princeton0-cluster-0.general.fuse.l42.cloudera.com:9092',
'connector.properties.group.id' = 'flink-sql-energy-consumer',
'format.type' = 'json'
);
The scada table holds events from our sensors.
CREATE TABLE scada (
uuid STRING,
systemtime STRING,
amplitude100 DOUBLE,
amplitude500 DOUBLE,
amplitude1000 DOUBLE,
lownoise DOUBLE,
midnoise DOUBLE,
highnoise DOUBLE,
amps DOUBLE,
ipaddress STRING,
host STRING,
host_name STRING,
macaddress STRING,
endtime STRING,
runtime STRING,
starttime STRING,
cpu DOUBLE,
cpu_temp STRING,
diskusage STRING,
memory DOUBLE,
id STRING,
temperature STRING,
adjtemp STRING,
adjtempf STRING,
temperaturef STRING,
pressure DOUBLE,
humidity DOUBLE,
lux DOUBLE,
proximity INT,
oxidising DOUBLE,
reducing DOUBLE,
nh3 DOUBLE,
gasko STRING
) WITH (
'connector.type' = 'kafka',
'connector.version' = 'universal',
'connector.topic' = 'scada',
'connector.startup-mode' = 'earliest-offset',
'connector.properties.bootstrap.servers' = 'tspann-princeton0-cluster-0.general.fuse.l42.cloudera.com:9092',
'connector.properties.group.id' = 'flink-sql-scada-consumer',
'format.type' = 'json'
);

This is the magic part:
INSERT INTO global_sensor_events
SELECT
scada.uuid,
scada.systemtime ,
scada.temperaturef ,
scada.pressure ,
scada.humidity ,
scada.lux ,
scada.proximity ,
scada.oxidising ,
scada.reducing ,
scada.nh3 ,
scada.gasko,
energy.current,
energy.voltage ,
energy.power ,
energy.total,
energy.fanstatus
FROM energy,
scada
WHERE
** scada.systemtime = energy.systemtime;**
So we join two Kafka topics and use some of their fields to populate a third Kafka topic that we defined above.
With Cloudera, it is so easy to monitor our streaming Kafka events with SMM.

For context, this is where the data comes from:


Top comments (0)