Introducing Mm FLaNK...
An Apache Flink Stack for Rapid Streaming Development From Edge 2 AI

Source : https://github.com/tspannhw/MmFLaNK
Stateless NiFi: https://www.datainmotion.dev/2019/11/exploring-apache-nifi-110-parameters.html
To show an example of using the Mm FLaNK stack we have an Apache NiFi flow that reads IoT data (JSON) and send it to Apache Kafka. An Apache Flink streaming application running in YARN reads it, validates the data and send it to another Kafka topic. We monitor and check the data with SMM. The data from that second topic is read by Apache NiFi and pushed to Apache Kudu tables.
Mm FLaNK Stack (MXNet, MiNiFi, Flink, NiFi, Kafka, Kudu)
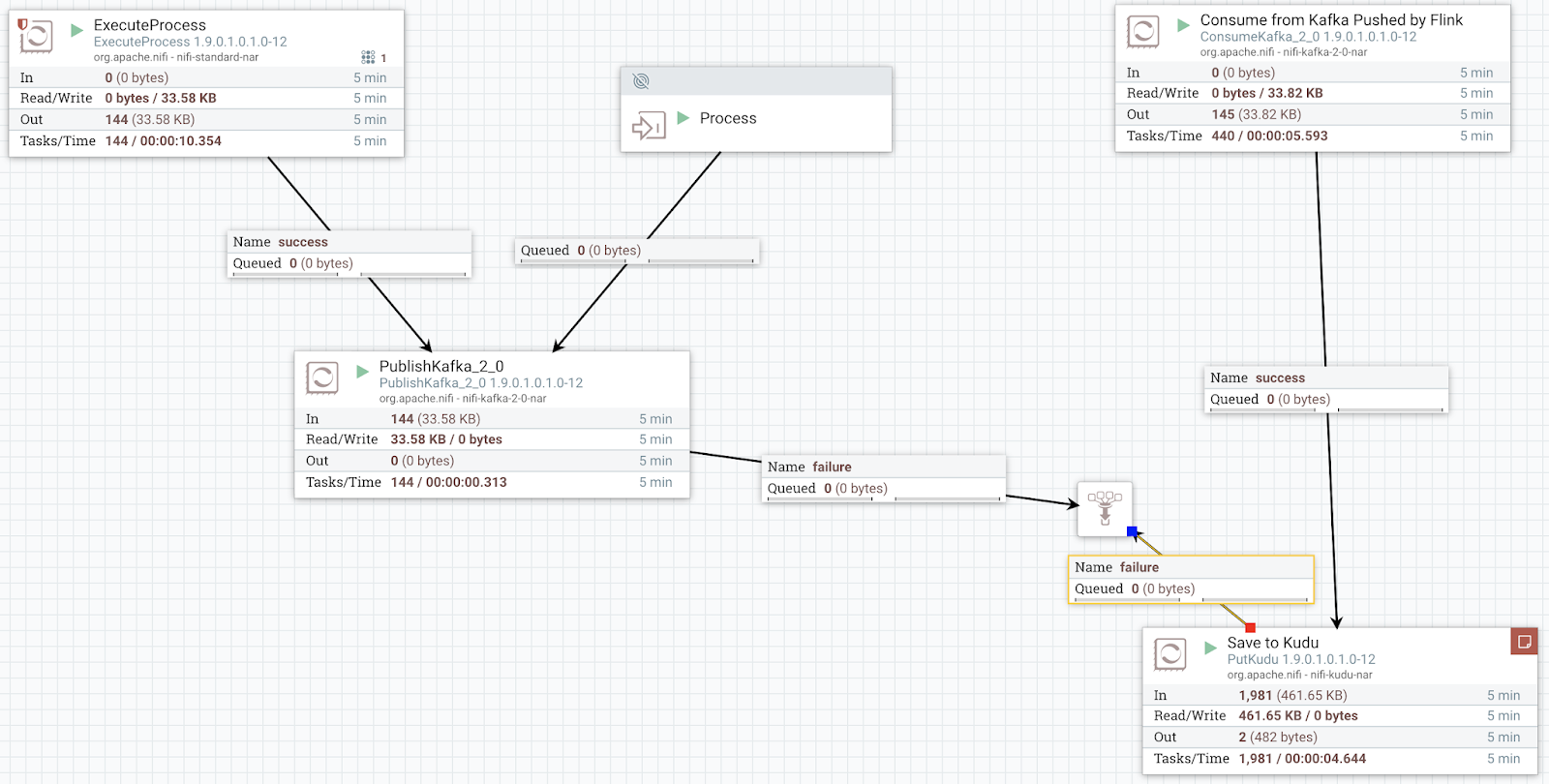
First, we rapidly ingest, route, transform, convert, query and process data with Apache NiFi. Once we have transformed it into a client, schema-validated known data type we can stream it to Kafka for additional processing.

Second, we read from that Kafka topic, iot , with a Java Apache Flink application. We then filter out empty records and then push it to another Kafka topic, iot-result.

public static class NotNullFilter implements FilterFunction { @Override public boolean filter(String string) throws Exception { if ( string == null || string.isEmpty() || string.trim().length() <=0) { return false;}
return true; } }
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "cloudera:9092");
properties.setProperty("group.id","flinkKafkaGroup");
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
FlinkKafkaConsumer consumer = new FlinkKafkaConsumer<>("iot", new SimpleStringSchema(), properties);
DataStream source = env. addSource (consumer).name("Flink IoT Kafka Source");
source.print();
source. filter (new NotNullFilter());
source. addSink (new FlinkKafkaProducer<>("cloudera:9092", "iot-result",
new SimpleStringSchema())).name("Flink Kafka IoT Result Sink");

We compile our Java application with maven and build a big JAR that we will use the Flink Client to push to YARN on our CDH 6.3 cluster.
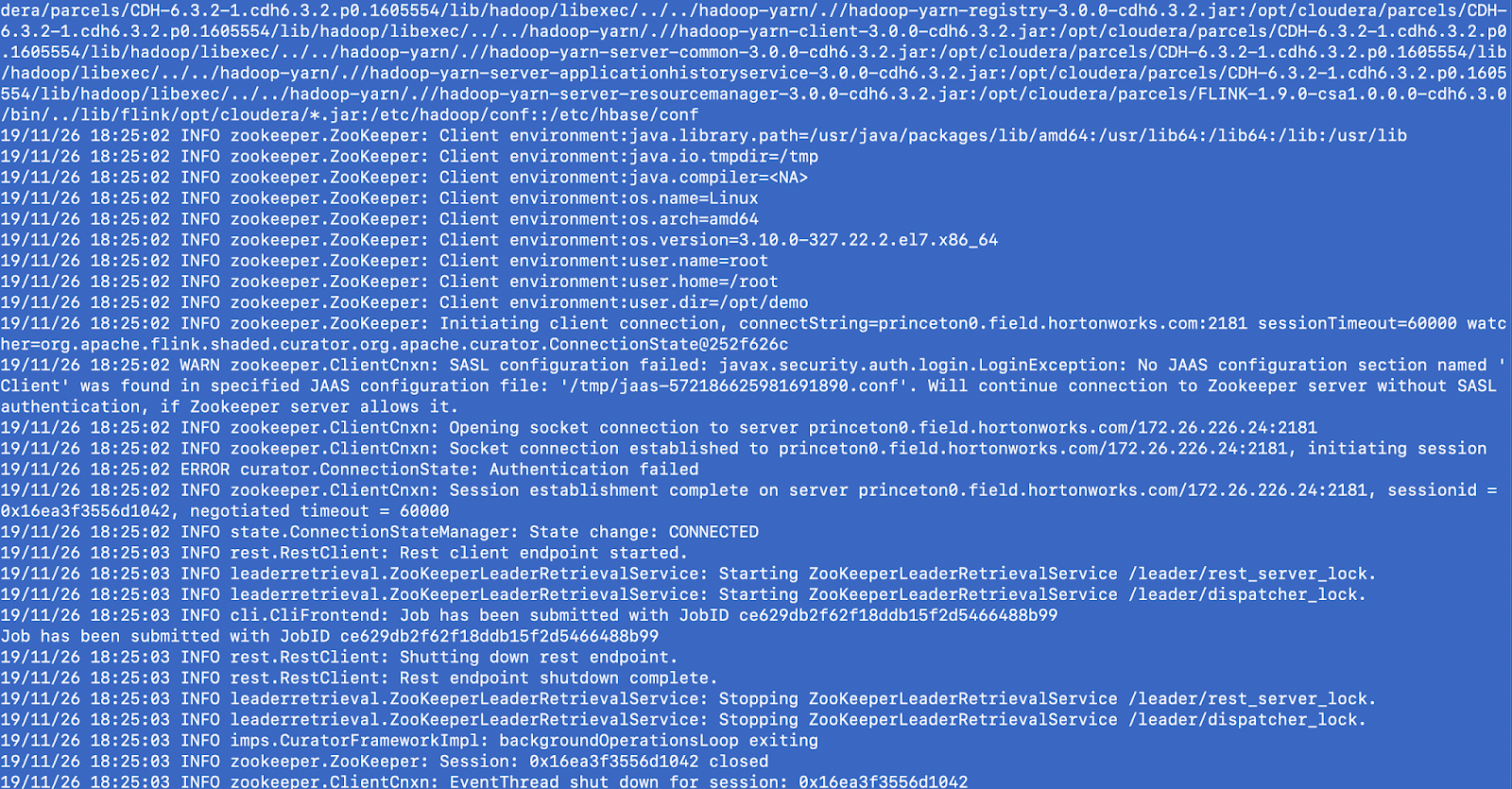
Once the Flink application is running we can see a lot of metrics, logs and information on our streaming service. We can browse the logs via YARN UI and Flink UI.
From the Hadoop YARN UI, you can Link to this application's Flink Dashboard.

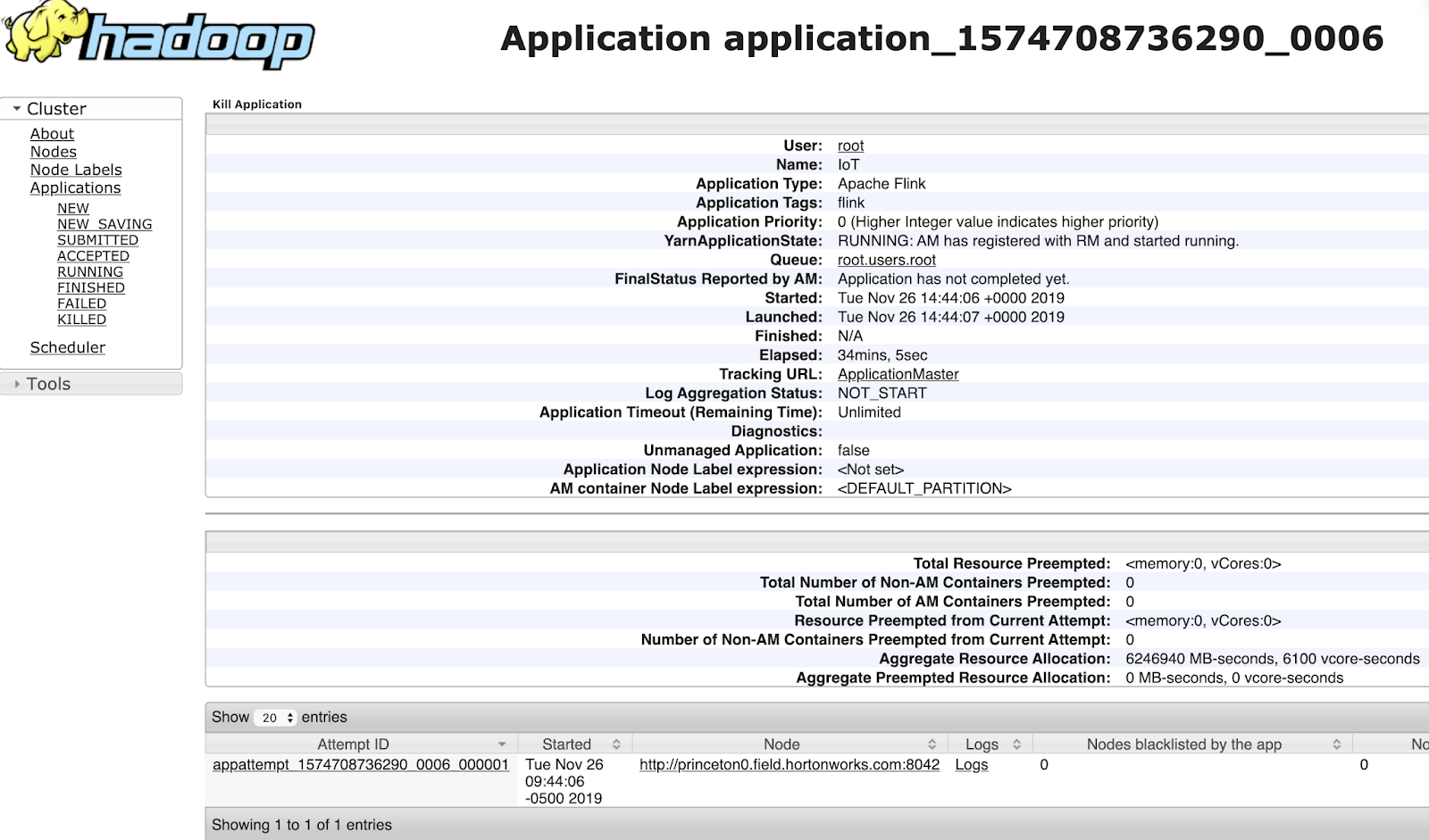
You can easily see logs from various components, your application, containers and various systems.

The Apache Flink Dashboard is a very rich easy to navigate to interface for all the information related to your running job.
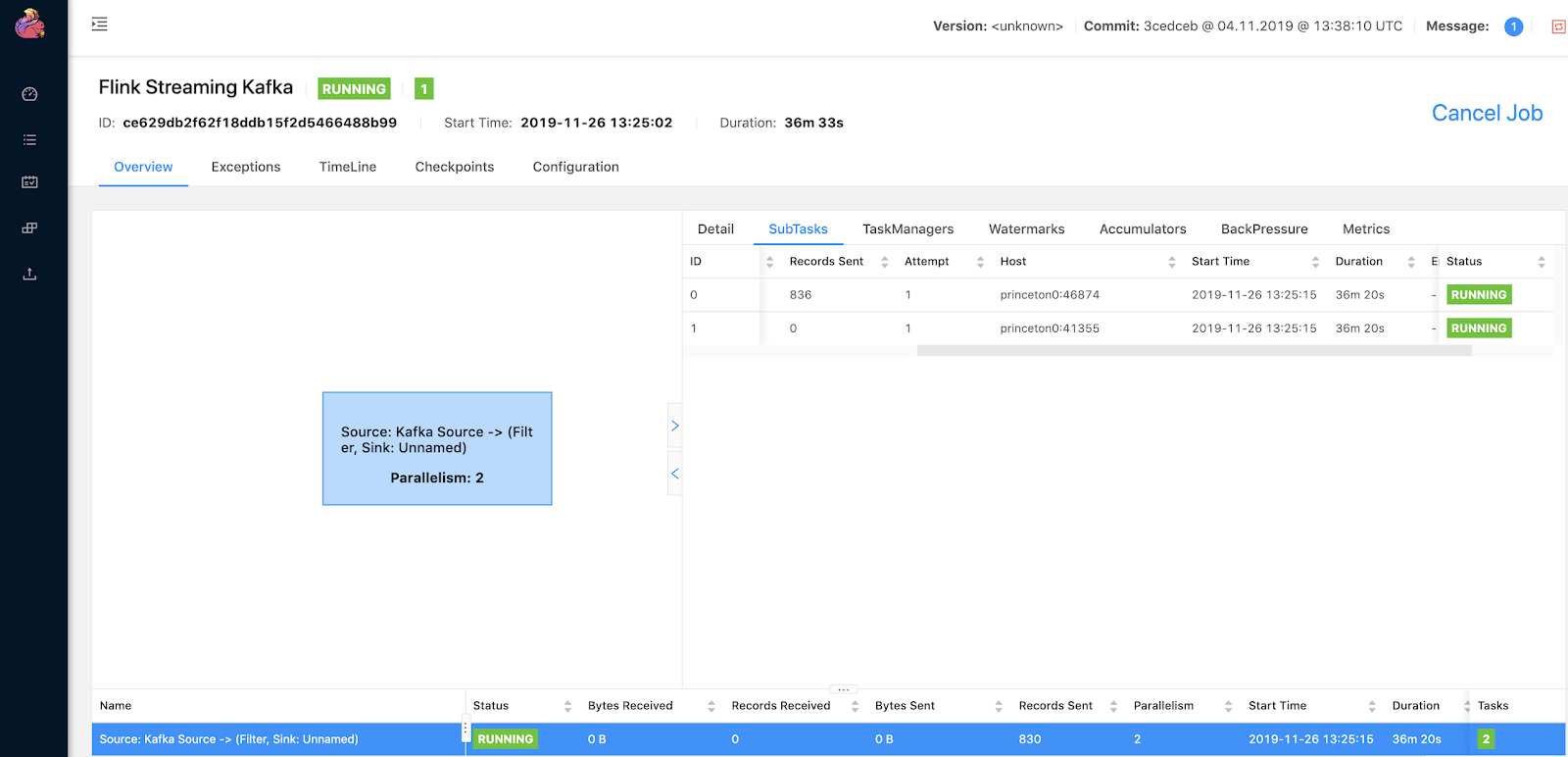
You can see and add charts to view various metrics about sources, sinks and a large number of other interesting real-time attributes.
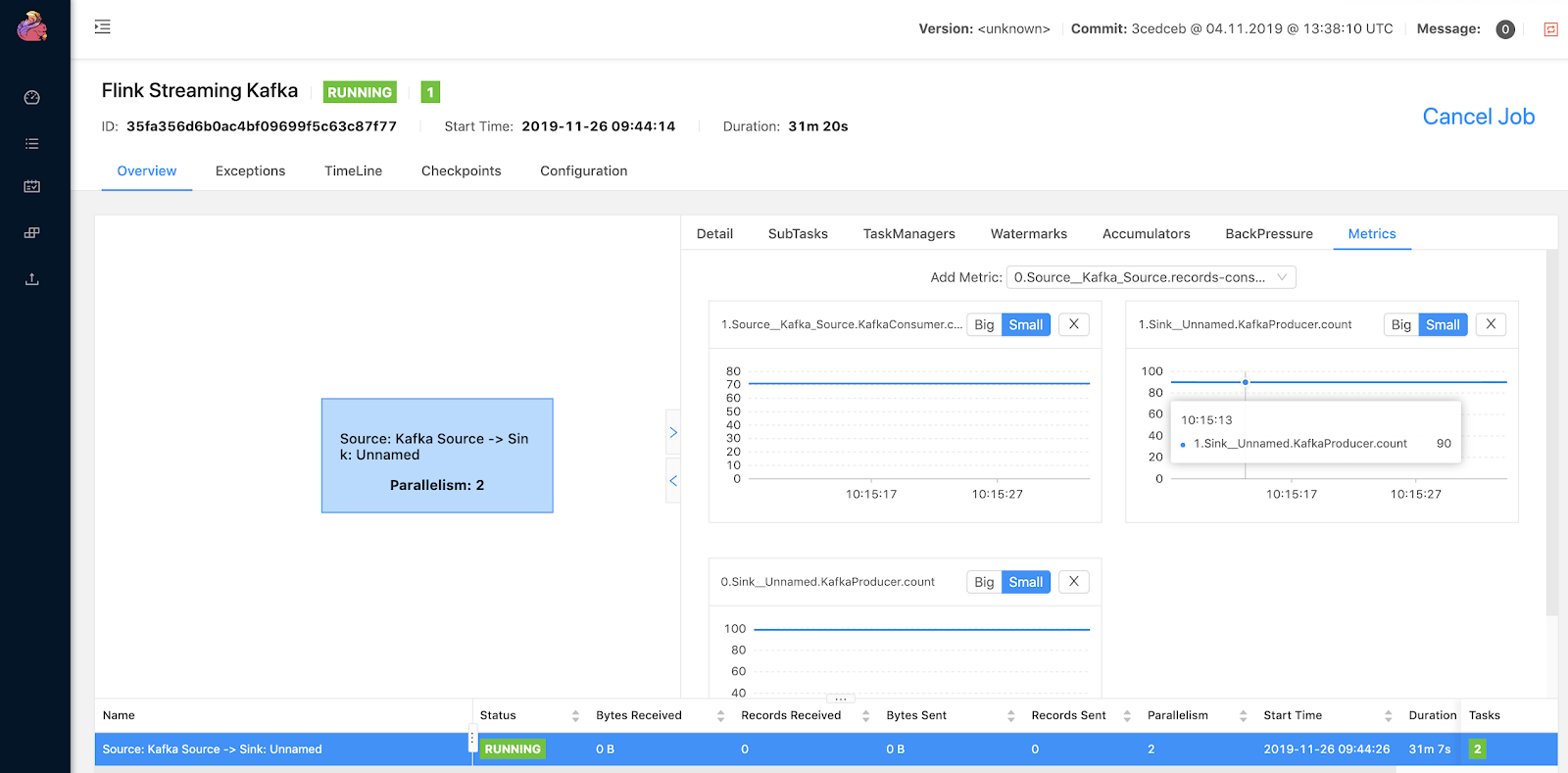
There is also an older view that is still available to show a less dynamic interface.
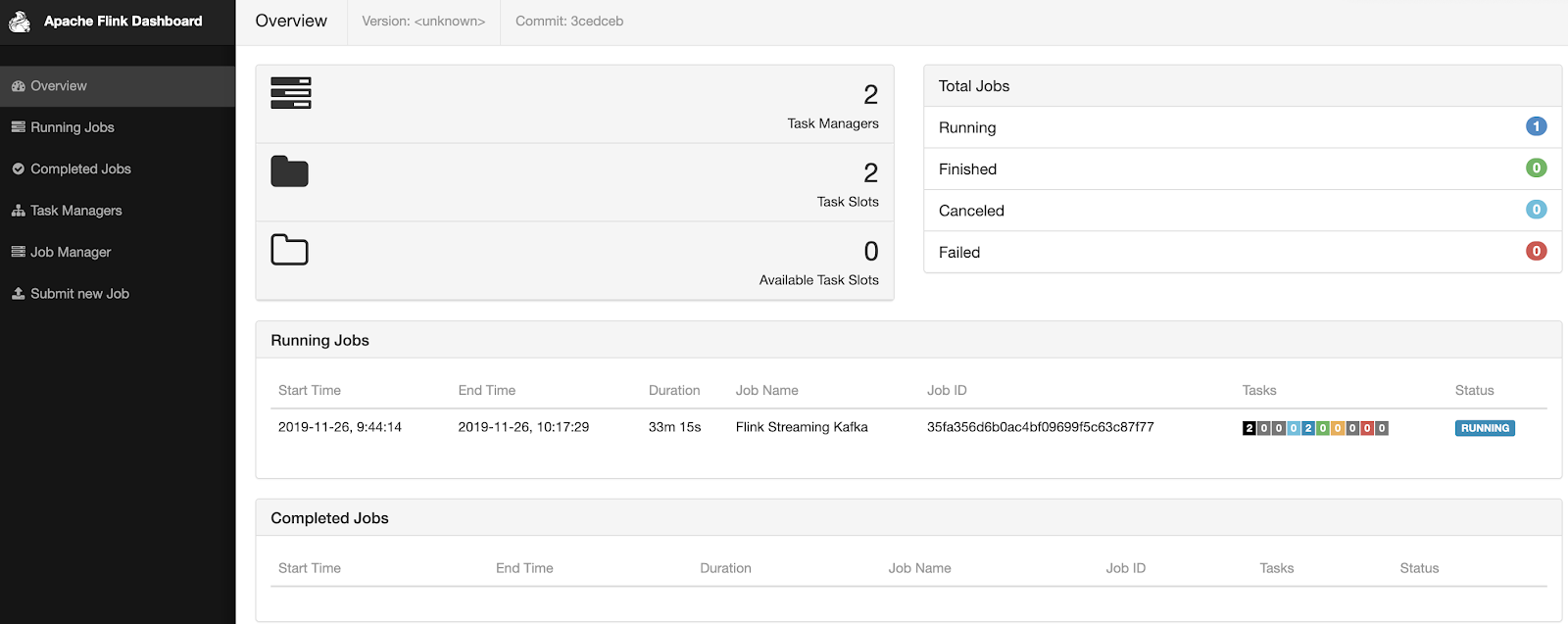
You can also dive down into individual task managers with their attributes.

Logs are easily accessible:
Another Apache NiFi flow reads from the iot-result topic and does additional processing, could do machine learning / deep learning and then stores to a data store such as Apache Kudu. ** If you have attended any of the **CDF Workshops, you will notice we could integrate machine learning via a LookupRecord processor calling CDSW Python Machine Learning application via REST. Data read from Kafka is streaming in with helpful metadata into our provenance data stream including kafka offset, partition, topic and a unique id on the data.

Since we are using Apache Kafka 2.x for a lot of streams, we really need to see what is going on in there. Fortunately Cloudera Streams Messaging Manager gives us full insight into everything. We can browse brokers, topics, consumers and producers. We can also setup alerts to notify someone via various methods (email, rest, etc...) if something happens such as consumer lag. From the below screen we can see that these two consumers are lagging. This is because I have stopped them so they cannot process the message in their respective topics.

I restart my consumers and quickly the lag is gone. Flink and NiFi process Kafka topics quickly!
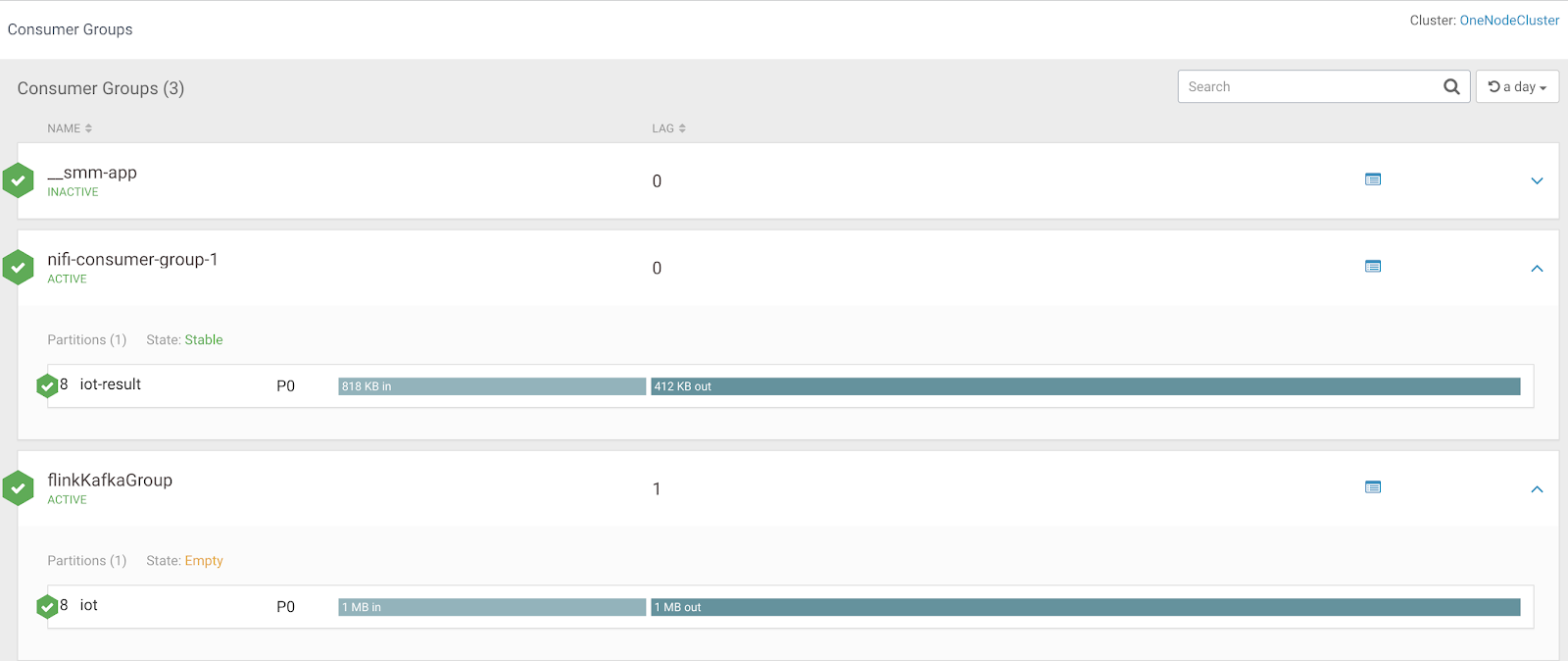
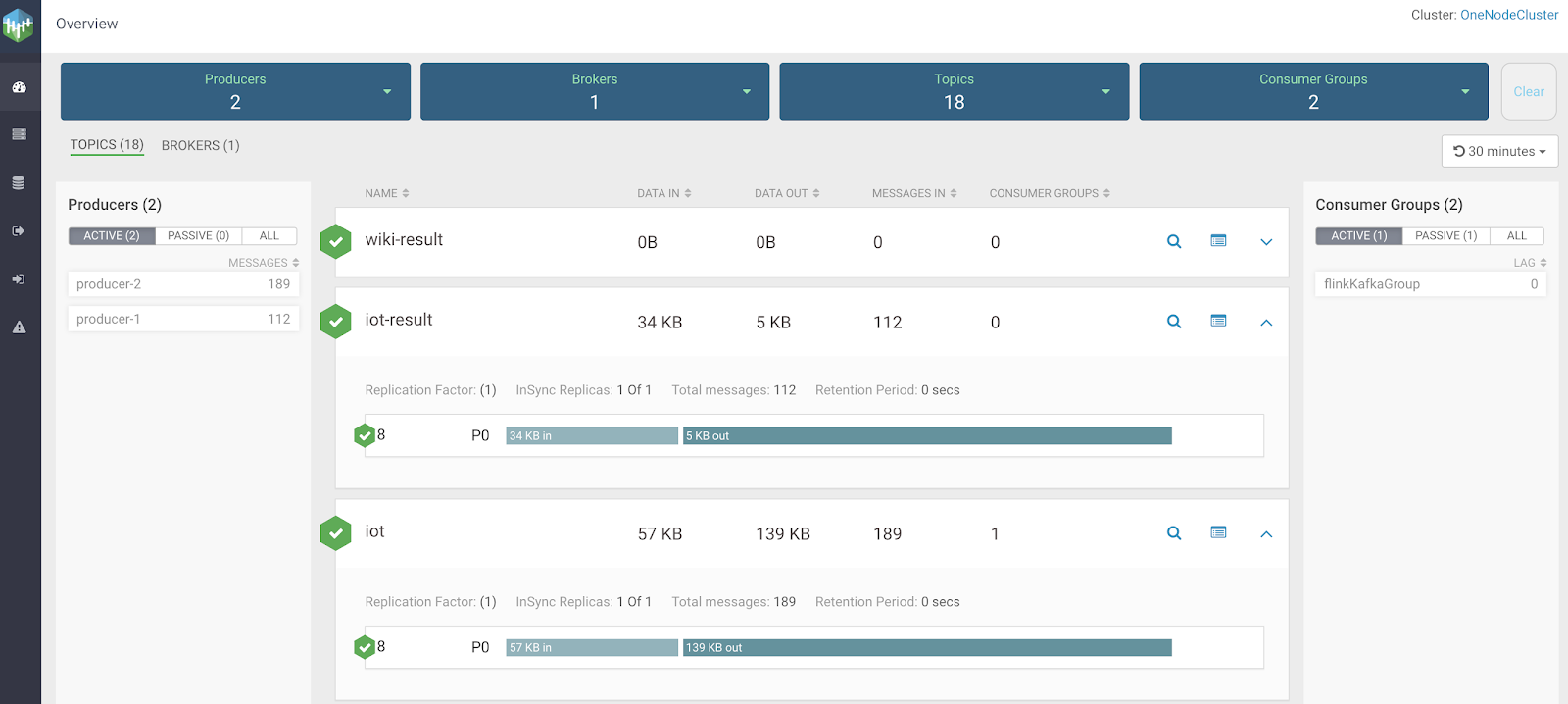
We can see a nice overview of my FLaNK application via this screen. I see my current stats on the source and sink Kafka topics I am working with from NiFi and Flink.
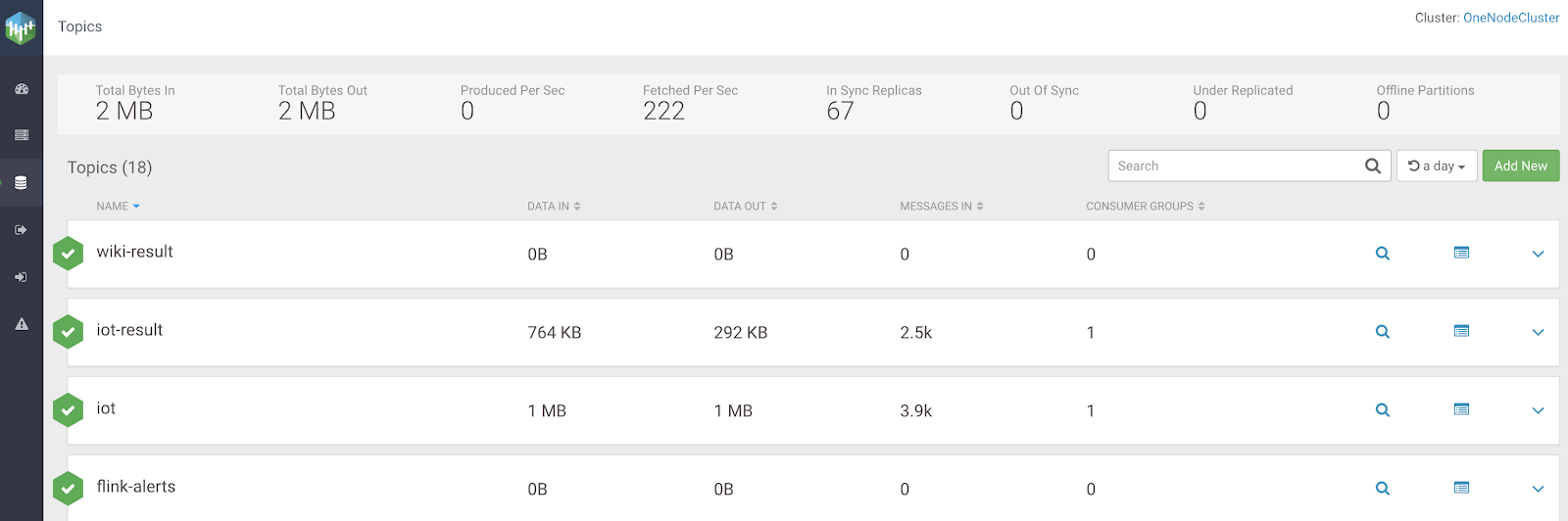
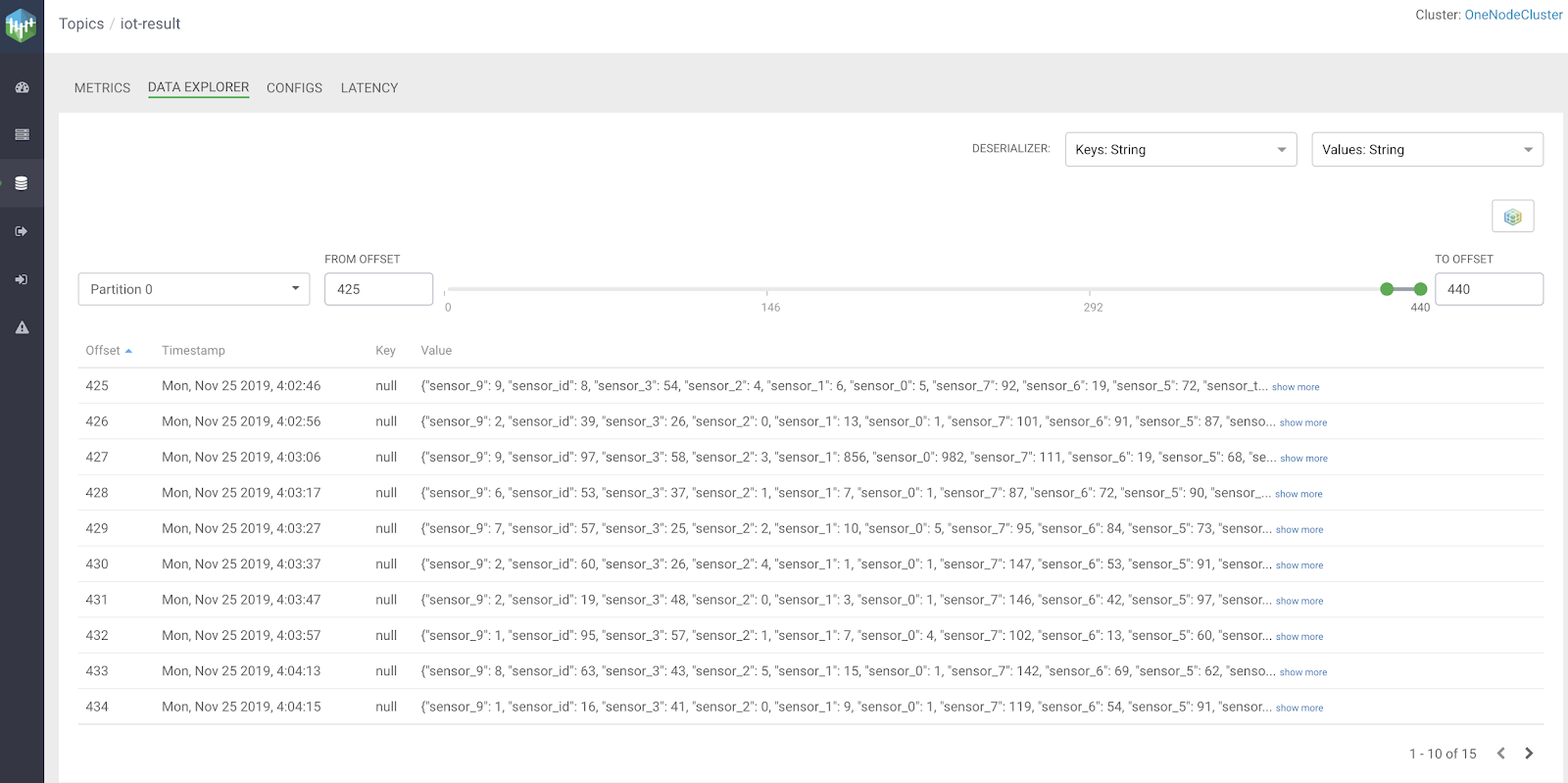
I can also dive into a topic (if I have permissions) and see the content of the data. There's also a link to the Schema Registry for this particular topic and the ability to view various types of Kafka data including Strings and Avro. As you can see our payloads are JSON IoT data.
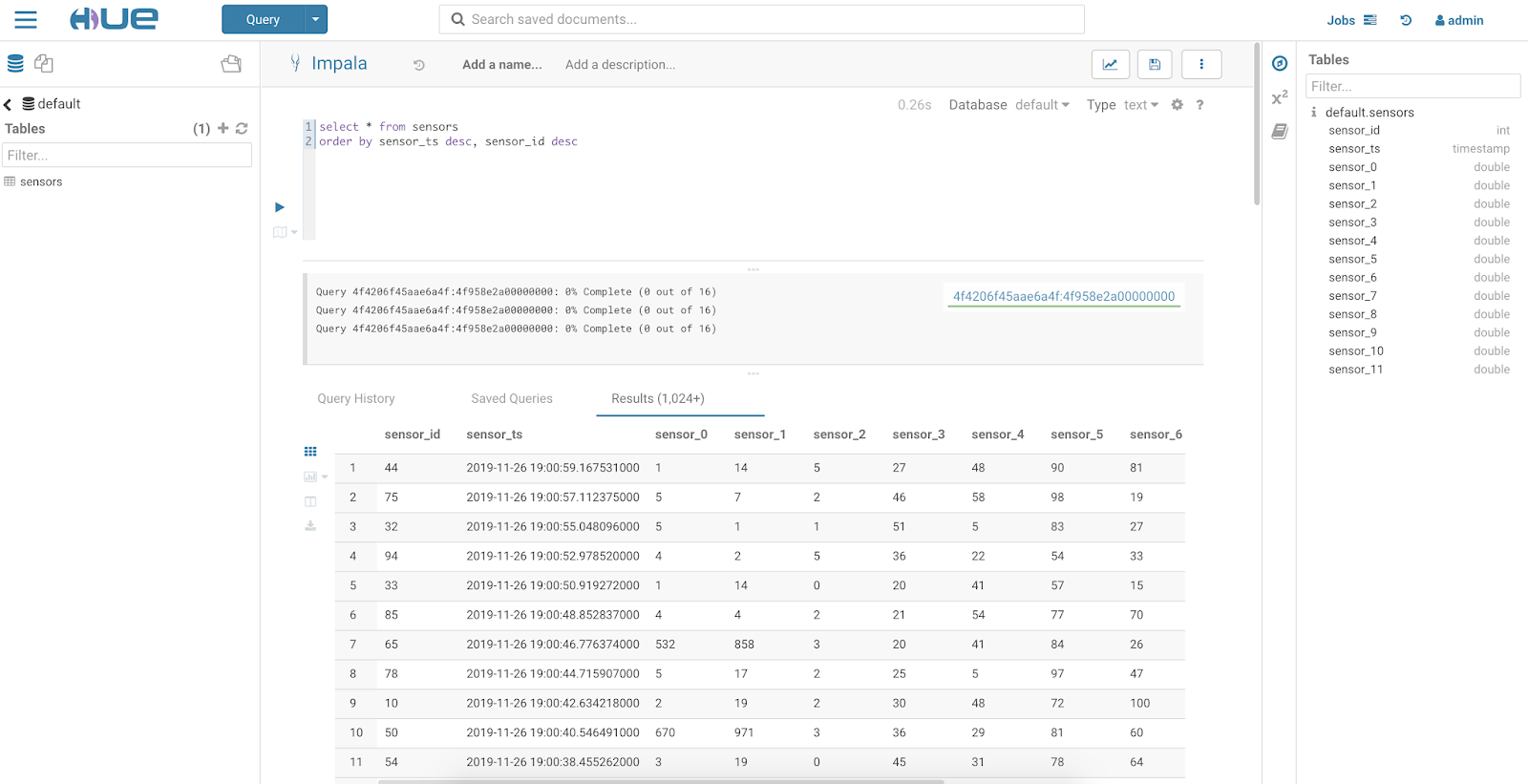
Once our NiFi Kafka Consumer has acquired the data we use our PutKudu processor to auto infer the schema of the JSON data and write to an existing Kudu table. We can query the data via an interface such as Apache Hue. We run a quick Apache Impala SQL query to get back data as it arrives. Apache NiFi is inserting data as we stream it through Apache Kafka from our Apache Flink application.

That was easy! Next up we will expand our Edge piece by utilizing MiNiFi deployed by Cloudera Edge Flow Manager as well as add our second M with Apache MXNet with my Apache MXNet NiFi processor as well as some Python GluonCV , GluonTS and more via Cloudera Data Science Workbench. We will also use Stateless Apache NiFi 1.10 for some FaaS Kafka consuming and producing.
More FLaNK to come!
Upcoming : GluonTS for Forecasting Time Series https://gluon-ts.mxnet.io/examples/basic_forecasting_tutorial/tutorial.html
References :
- https://dataworkssummit.com/berlin-2018/session/iot-with-apache-mxnet-and-apache-nifi-and-minifi/
- https://github.com/tspannhw/nifi-mxnetinference-processor
- https://community.cloudera.com/t5/Community-Articles/Apache-NiFi-Processor-for-Apache-MXNet-SSD-Single-Shot/ta-p/249240
- https://www.youtube.com/watch?v=5w6rV7562xM
- https://mxnet.apache.org/
- https://www.datainmotion.dev/2019/11/learning-apache-flink-19.html
- https://mvnrepository.com/artifact/org.apache.nifi
- https://github.com/apache/nifi
- https://apachenifi.slack.com/join/shared_invite
- https://hub.docker.com/r/apache/nifi/
- https://www.cloudera.com/products/data-science-and-engineering/data-science-workbench.html
- https://www.cloudera.com/products/cdf/cem.html
- https://blog.cloudera.com/smm-1-2-released-with-powerful-new-alerting-and-topic-lifecycle-management-features-with-schema-registry-integration/

Top comments (0)