Let's Query Kafka with Hive
I can hop into beeline and build an external Hive table to access my Cloudera CDF Kafka cluster whether it is in the public cloud in CDP DataHub, on-premise in HDF or CDF or in CDP-DC.
I just have to set my KafkaStorageHandler, Kafka Topic Name and my bootstrap servers (usually port 9092). Now I can use that table to do ELT/ELT for populating Hive tables or populating Kafka topics from Hive tables. This is a nice and easy way to do data engineering on the quick and easy.
This is a good item to augment CDP Data Engineering with Spark, CDP DataHub with NiFi, CDP DataHub with Kafka and KafkaStreams and various SQOOP or Python utilities you may have in your environment.
For real-time continuous queries on Kafka with SQL, you can use Flink SQL. https://www.datainmotion.dev/2020/05/flank-low-code-streaming-populating.html

Example Table Create
CREATE EXTERNAL TABLE <tableName>
(uuid STRING, systemtime STRING , temperaturef STRING , pressure DOUBLE,humidity DOUBLE, lux DOUBLE, proximity int, oxidising DOUBLE , reducing DOUBLE, nh3 DOUBLE , gasko STRING,current INT, voltage INT ,power INT, total INT,fanstatus STRING)
STORED BY 'org.apache.hadoop.hive.kafka.KafkaStorageHandler'
TBLPROPERTIES
("kafka.topic" = "<TopicName>",
"kafka.bootstrap.servers"="<ServerName>:9092");
show tables;
describe extended kafka_table;
select *
from kafka_table;
I can browse my Kafka topics with Cloudera SMM to see what the data is and why I want to load or need to load.
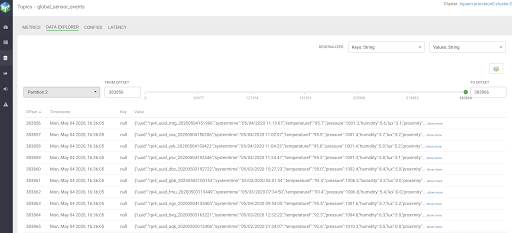
For more information take a look at the documentation for Integrating Hive and Kafka at Cloudera below:
- https://docs.cloudera.com/HDPDocuments/HDP3/HDP-3.1.5/integrating-hive/content/hive_kafka_query_table.html
- https://docs.cloudera.com/runtime/7.0.3/integrating-hive-and-bi/topics/hive-kafka-integration.html
- https://docs.cloudera.com/runtime/7.1.0/integrating-hive-and-bi/topics/hive-kafka-integration.html
- https://docs.cloudera.com/runtime/7.1.0/integrating-hive-and-bi/topics/hive\_ingest\_kafka\_data\_into\_hive.html

Top comments (0)