[FLaNK]: Running Apache Flink SQL Against Kafka Using a Schema Registry Catalog
There are a few things you can do when you are sending data from Apache NiFi to Apache Kafka to maximize it's availability to Flink SQL queries through the catalogs.
AvroWriter
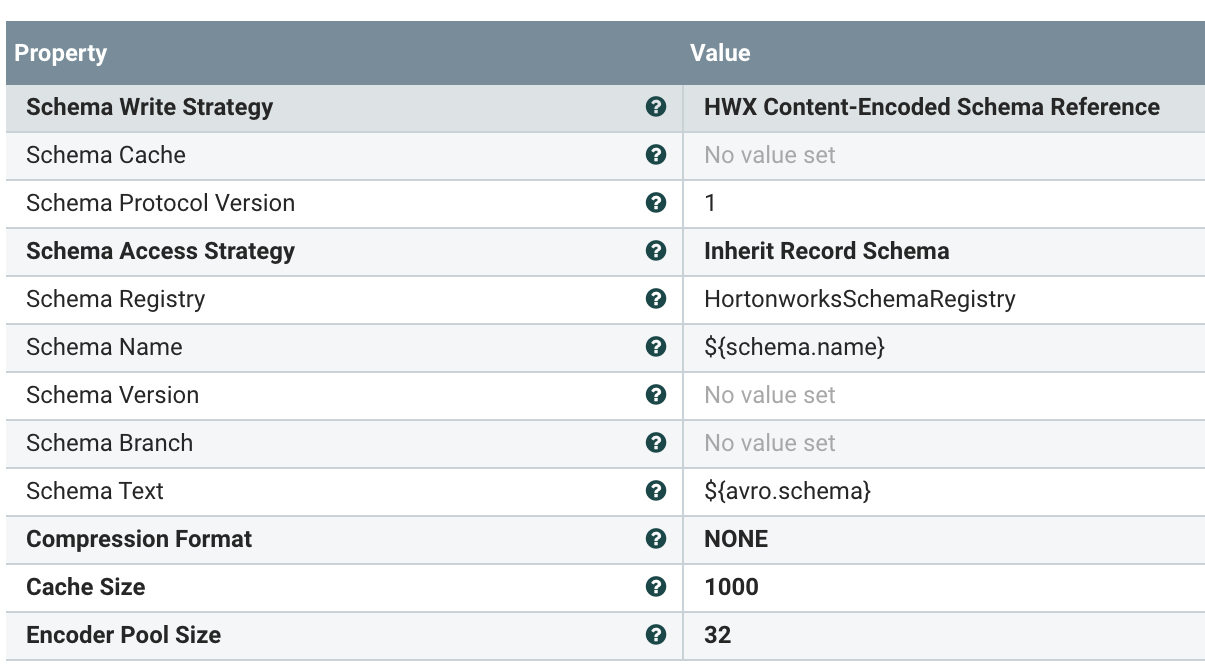
JSONReader
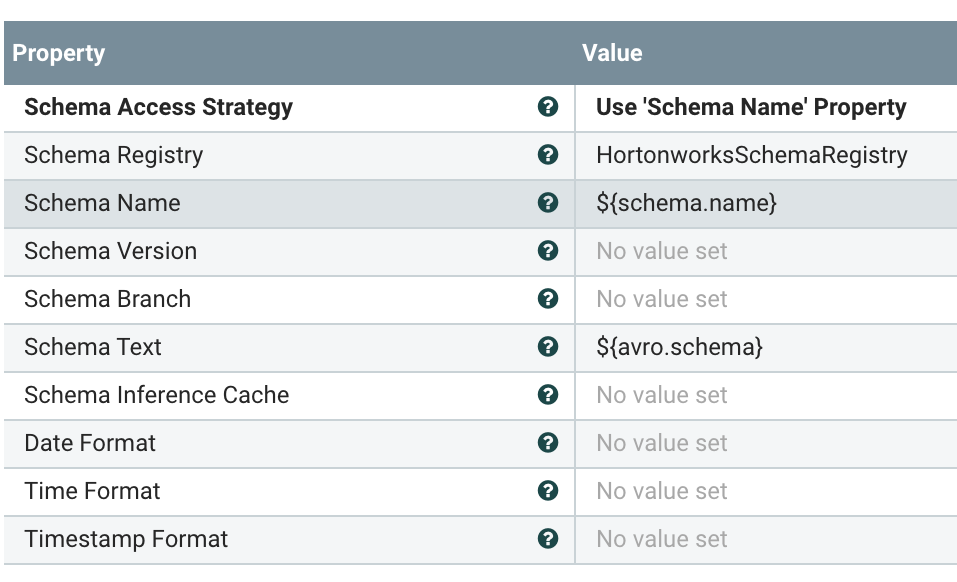
Producing Kafka Messages
Make sure you set AvroRecordSetWriter and set a Message Key Field.
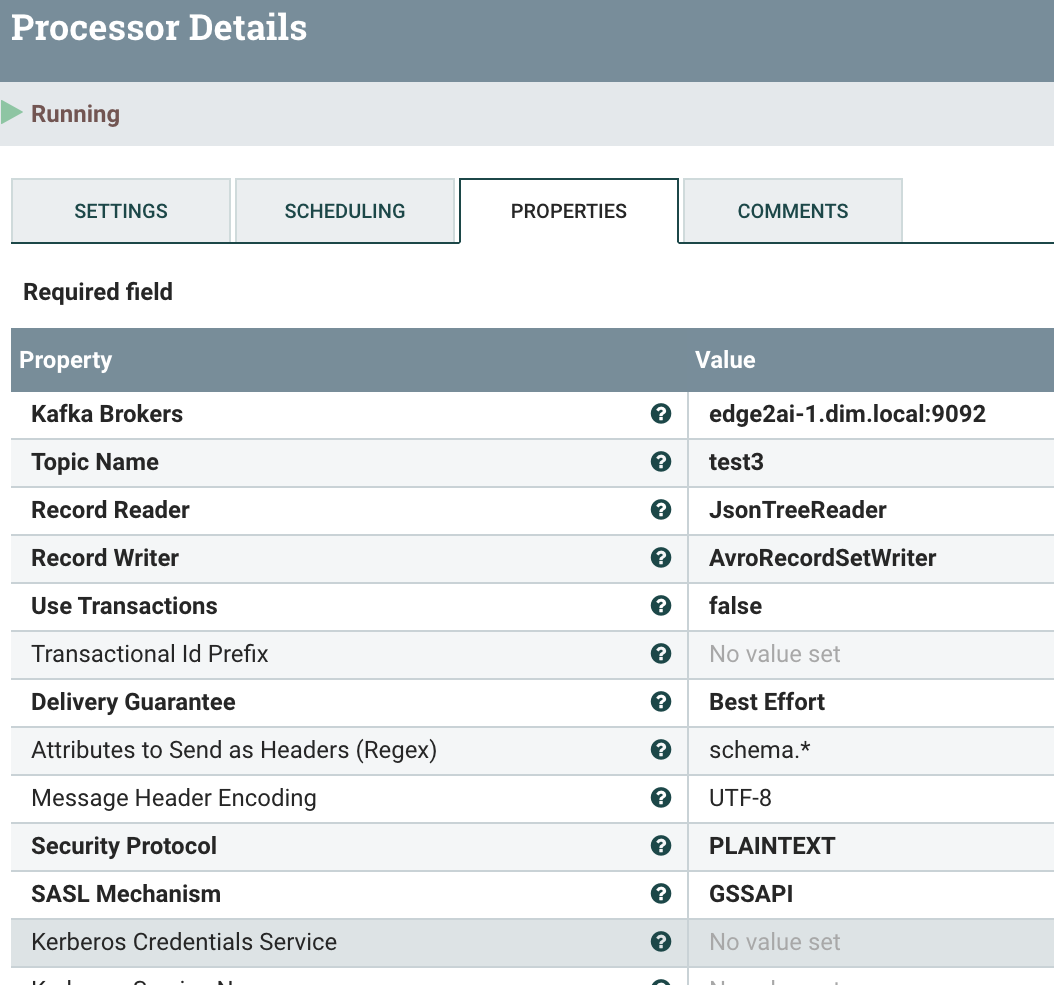
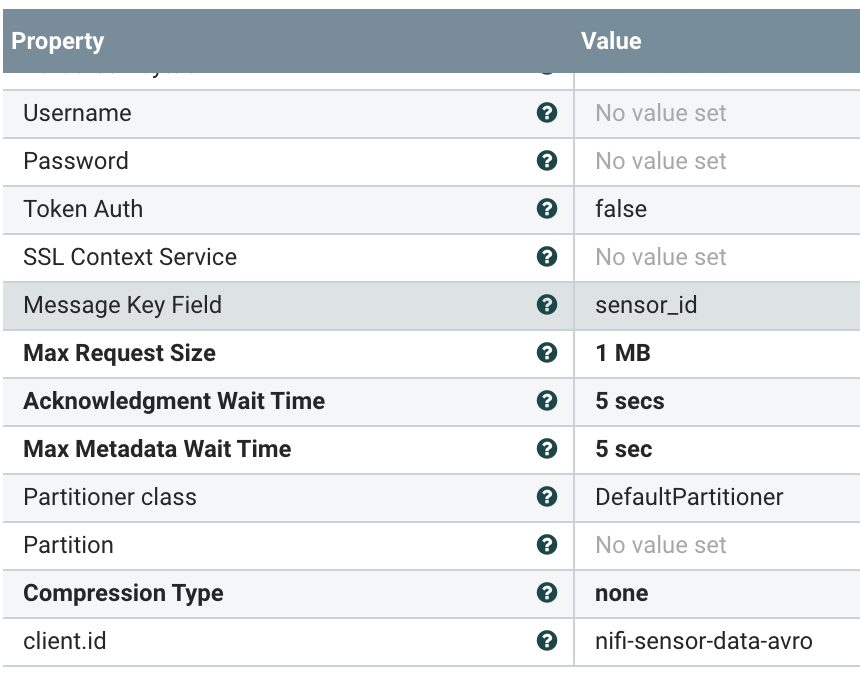
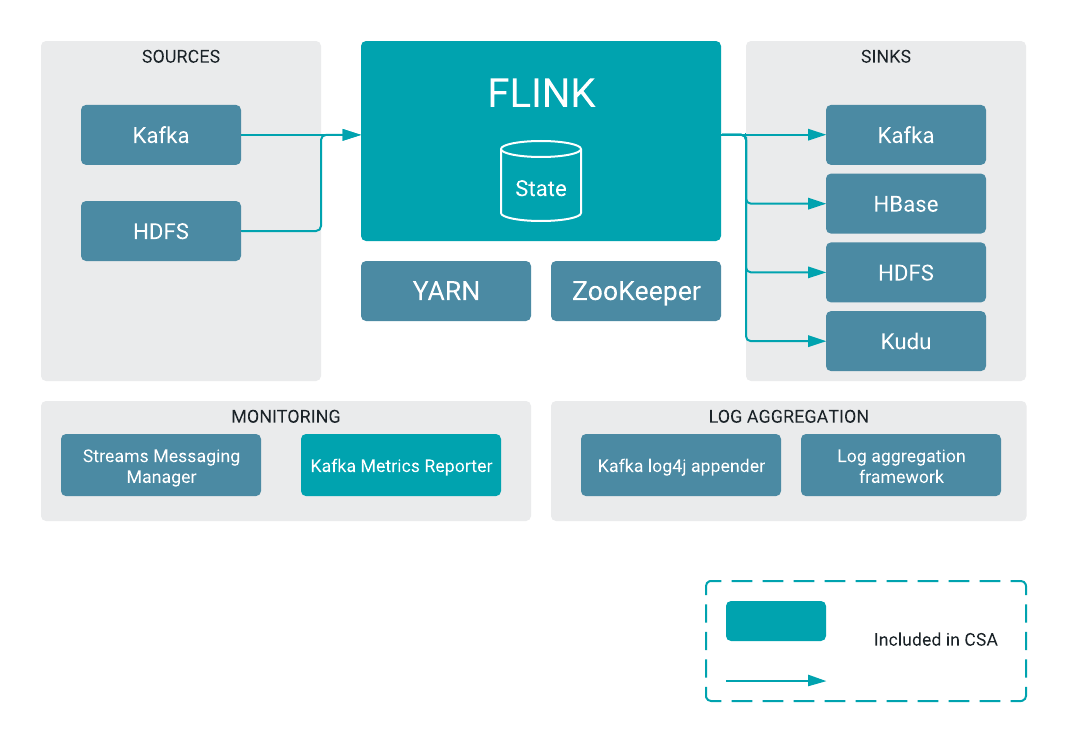
A great way to work with Flink SQL is to connect to the Cloudera Schema Registry. It let's you define your schema once them use it in Apache NiFi, Apache Kafka Connect, Apache Spark, Java Microservices
Setup
See: https://docs.cloudera.com/csa/1.2.0/sql-client/topics/csa-sql-client-config.html
See: https://docs.cloudera.com/csa/1.2.0/installation/topics/csa-hdfs-home-install.html
Make sure you setup your HDFS directory for use by Flink which keeps history and other important information in HDFS.
HADOOP_USER_NAME=hdfs hdfs dfs -mkdir /user/root
HADOOP_USER_NAME=hdfs hdfs dfs -chown root:root /user/root
SQL-ENV.YAML:
| configuration: |
| | execution.target: yarn-session |
| | |
| | catalogs: |
| | - name: registry |
| | type: cloudera-registry |
| | # Registry Client standard properties |
| | registry.properties.schema.registry.url: http://edge2ai-1.dim.local:7788/api/v1 |
| | # registry.properties.key: |
| | # Registry Client SSL properties |
| | # Kafka Connector properties |
| | connector.properties.bootstrap.servers: edge2ai-1.dim.local:9092 |
| | connector.startup-mode: earliest-offset |
| | - name: kudu |
| | type: kudu |
| | kudu.masters: edge2ai-1.dim.local:7051 |
CLI:
flink-sql-client embedded -e sql-env.yaml
We now have access to Kudu and Schema Registry catalogs of tables. This let's use start querying, joining and filtering any of these multiple tables without having to recreate or redefine them.
SELECT * FROM events
Code:
- https://github.com/tspannhw/FlinkSQLWithCatalogsDemo
- https://github.com/tspannhw/ApacheConAtHome2020/tree/main/schemas
- https://docs.cloudera.com/csa/1.2.0/overview/topics/csa-overview.html
- https://docs.cloudera.com/csa/1.2.0/flink-sql-table-api/topics/csa-schemaregistry-catalog.html
- https://github.com/tspannhw/FlinkForwardGlobal2020

Top comments (0)