Using GrovePi with Raspberry Pi and MiNiFi Agents for Data Ingest
*Source Code: * https://github.com/tspannhw/minifi-grove-sensors
Acquiring sensor data from Grove sensors is easy using a GrovePi Hat and some compatible sensors.

Just before my talk at the Future of Data Meetup @ Bell Works in Holmdel, NJ, I thought I should ingest some data from a grove sensor interface.
It's so easy a sleeping cat could do it.


So what does this device look like?

I have a temperature and humidity sensor on there.

The distance sonic sensor is in there too, that's for the next article.


Let's do this with minimal RAM.

That's a 64GB hard drive underneath in the white case with the RPI.

I need more data and BACON.

We design our MiNiFi Agent Flow in CEM/EFM. Grab JSON data stream and run sensors.
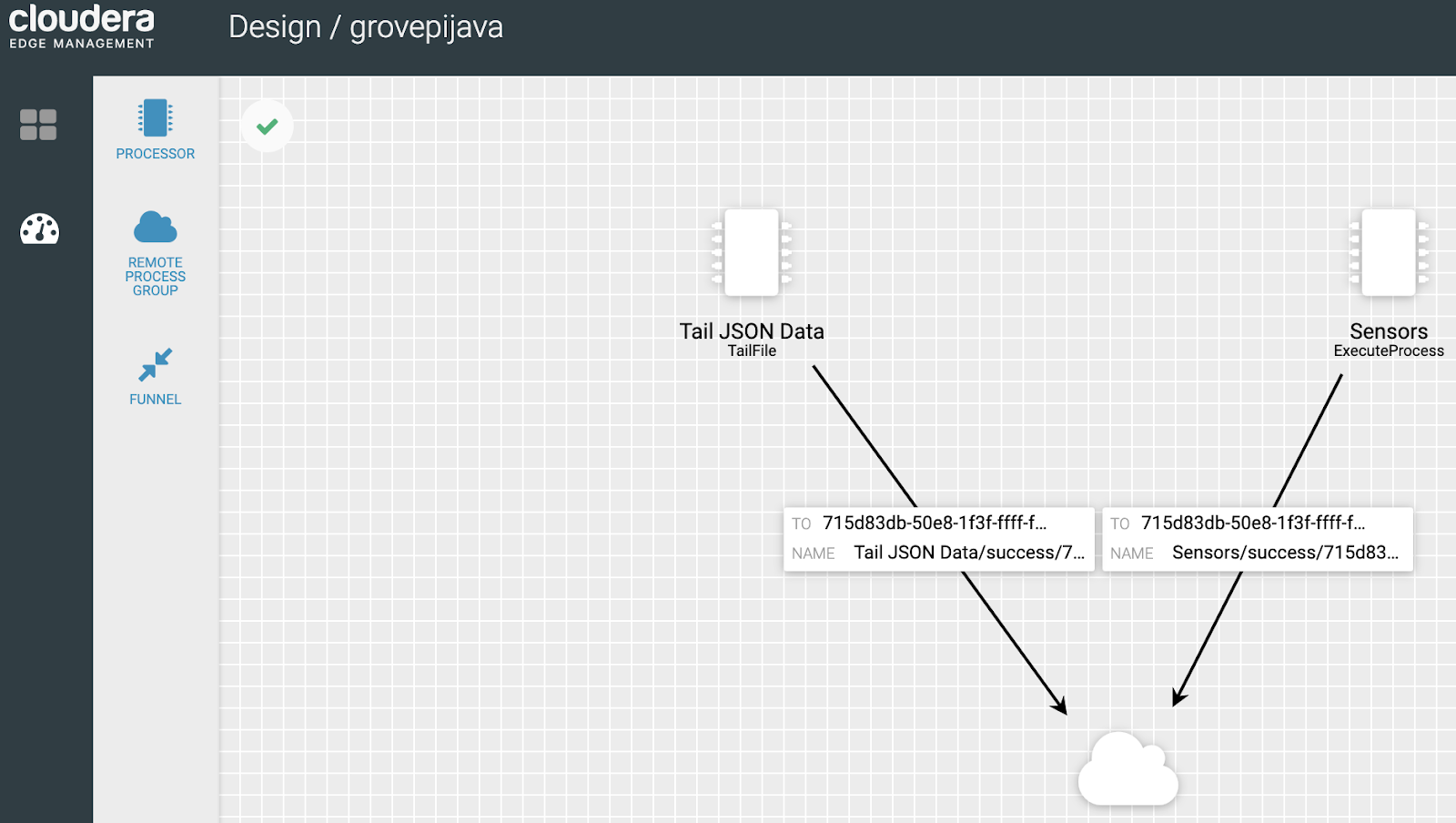
Apache NiFi 1.9.2 / CFM 1.0 Received HTTPS S2S Events From MiNiFi Agent

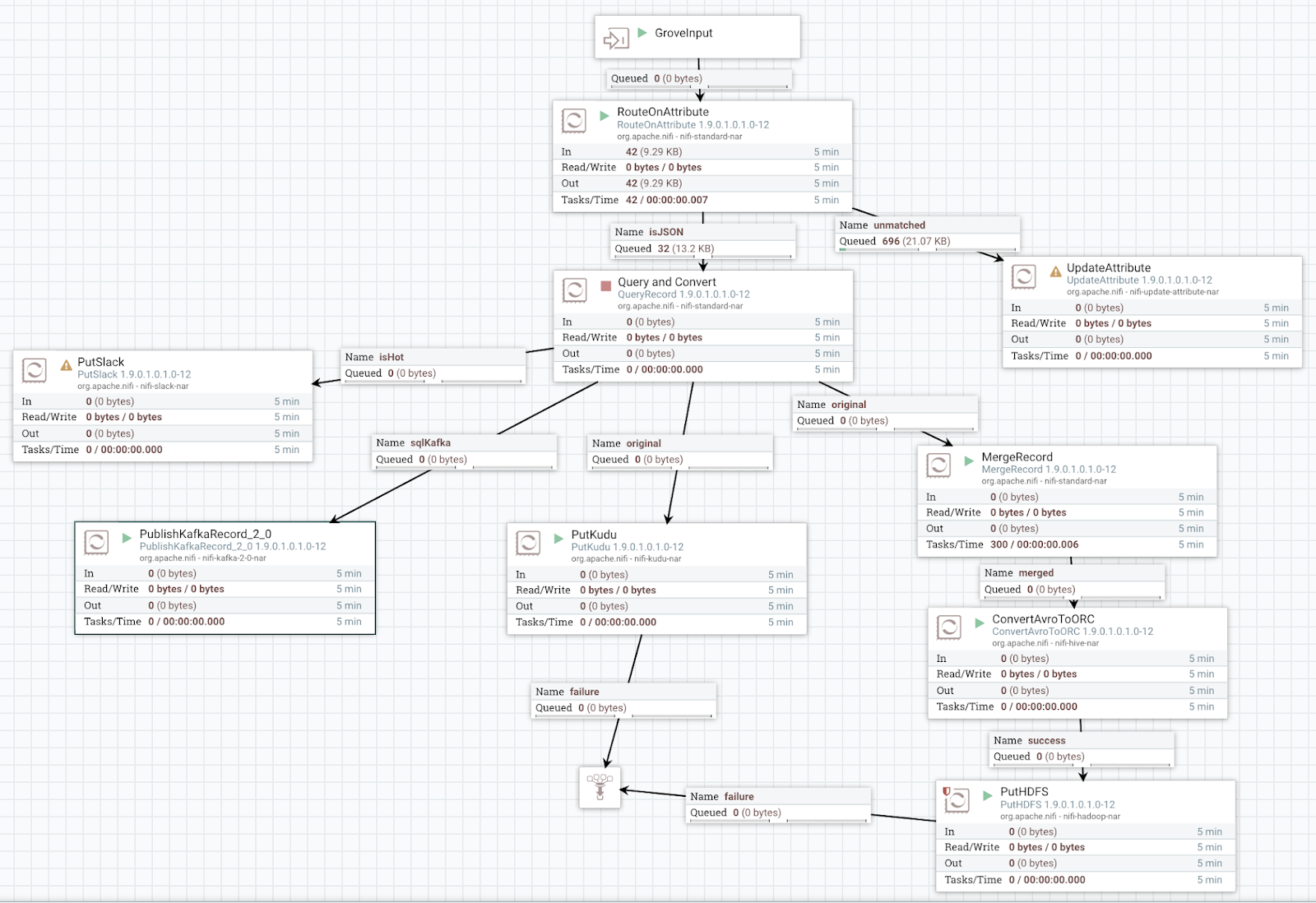
A simple flow to query and convert our JSON data, then store it to Kudu and HDFS (ORC) as well as push it to Kafka with a schema.
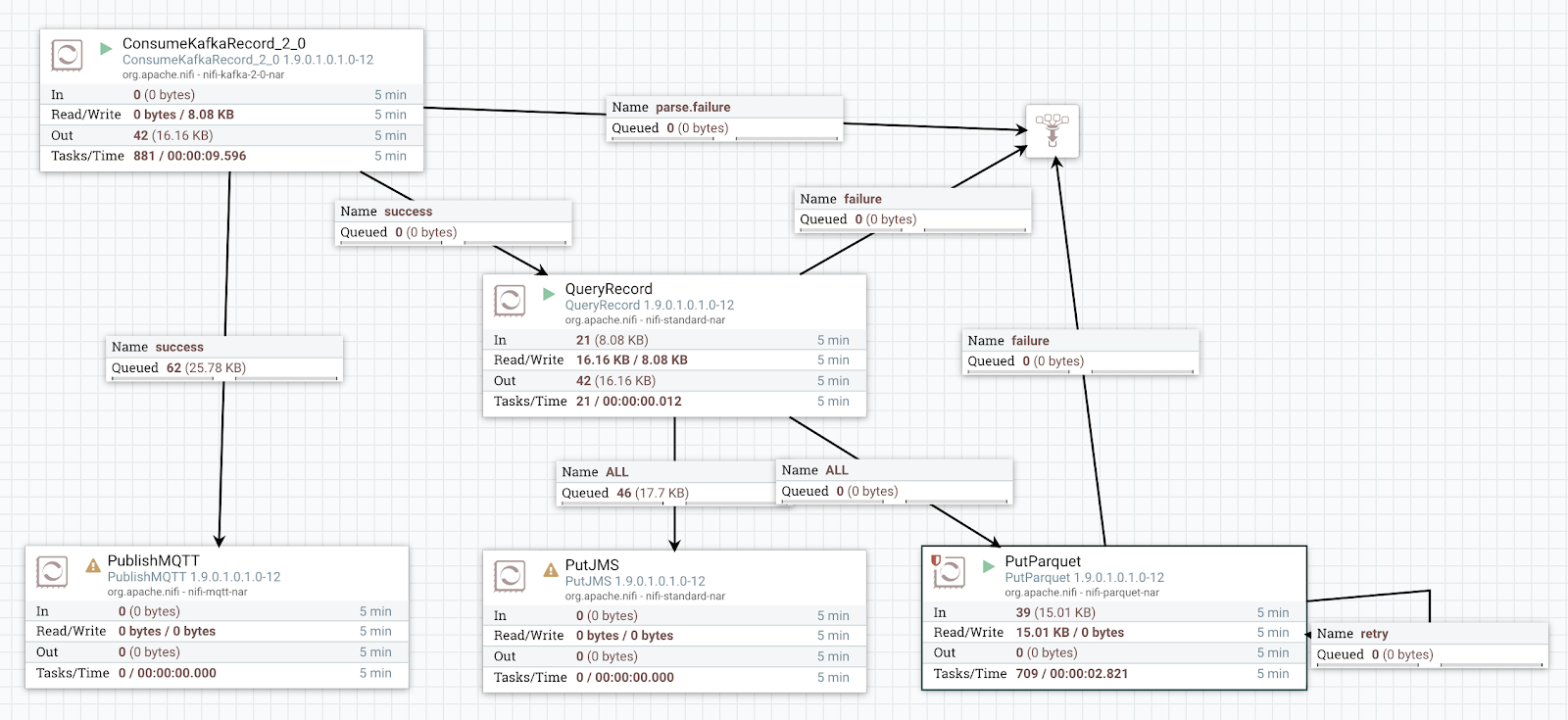
Let's read that Kafka message and store to Parquet, we will push to MQTT and JMS in the next article. This is our universal proxy/gateway.
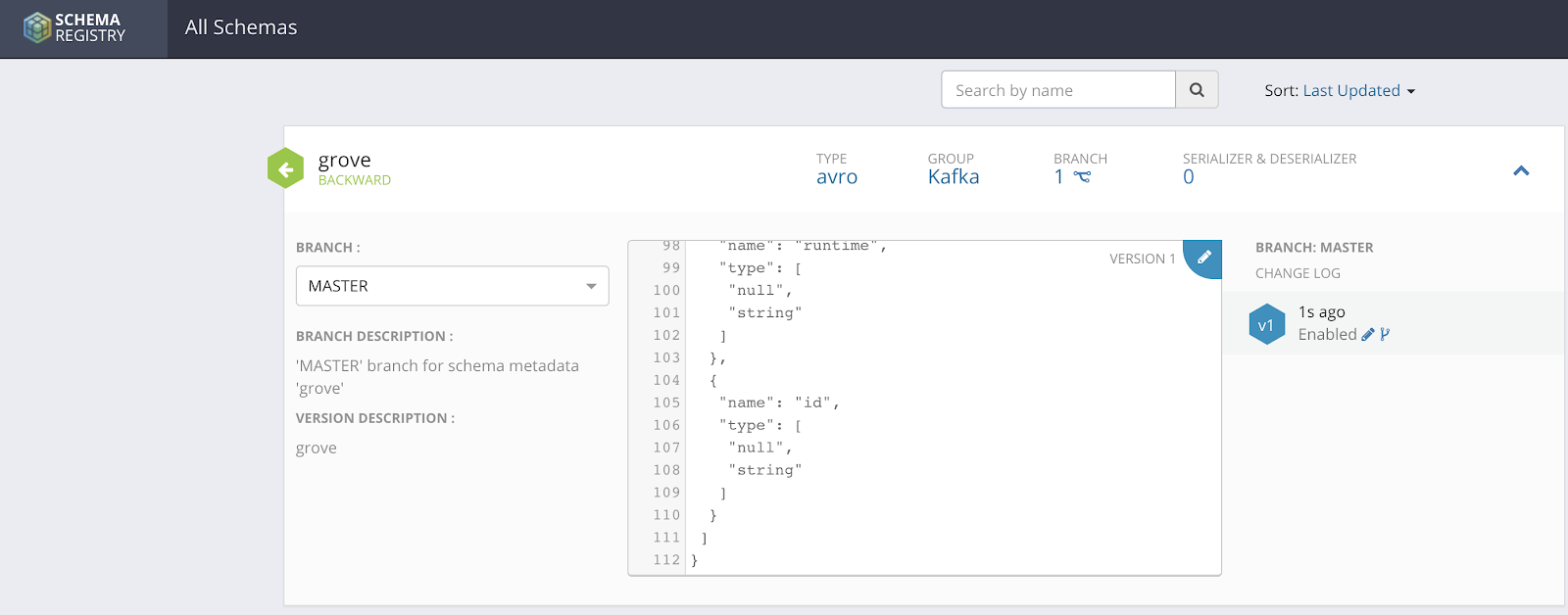
We could infer a schema and not save it. But by saving a schema to the schema registry it makes SMM, Kafka, NiFi and others schema aware and easy to automagically query and convert between CSV/JSON/XML/AVRO/Parquet and more.
Let's store the data in Parquet files on HDFS with an Impala table. In Apache NiFi 1.10 there is a ParquetWriter.
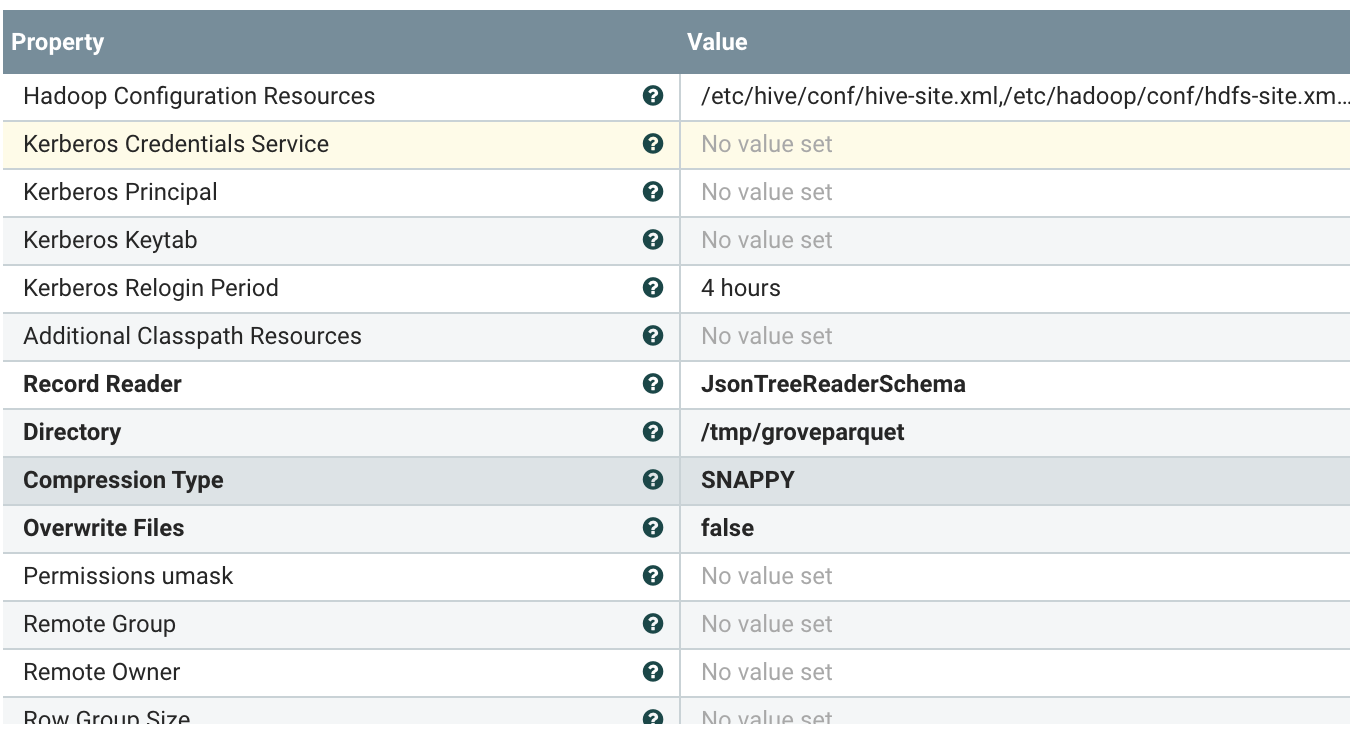
Before we push to Kafka, let's create a topic for it with Cloudera SMM

Let's build an impala table for that Kudu data.

We can query our tables with ease as data rapidly is added.
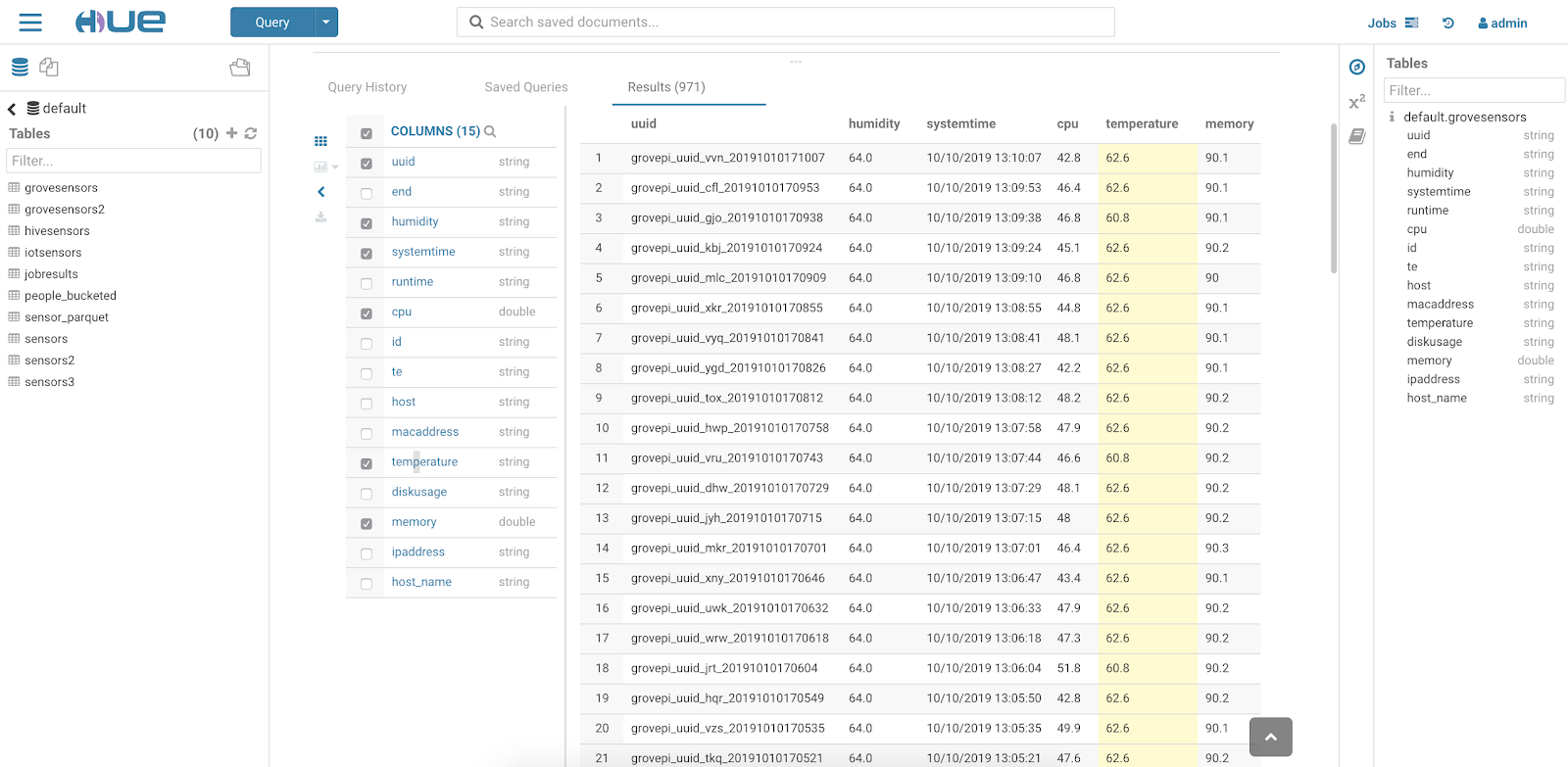
Let's Examine the Parquet Files that NiFi Generated

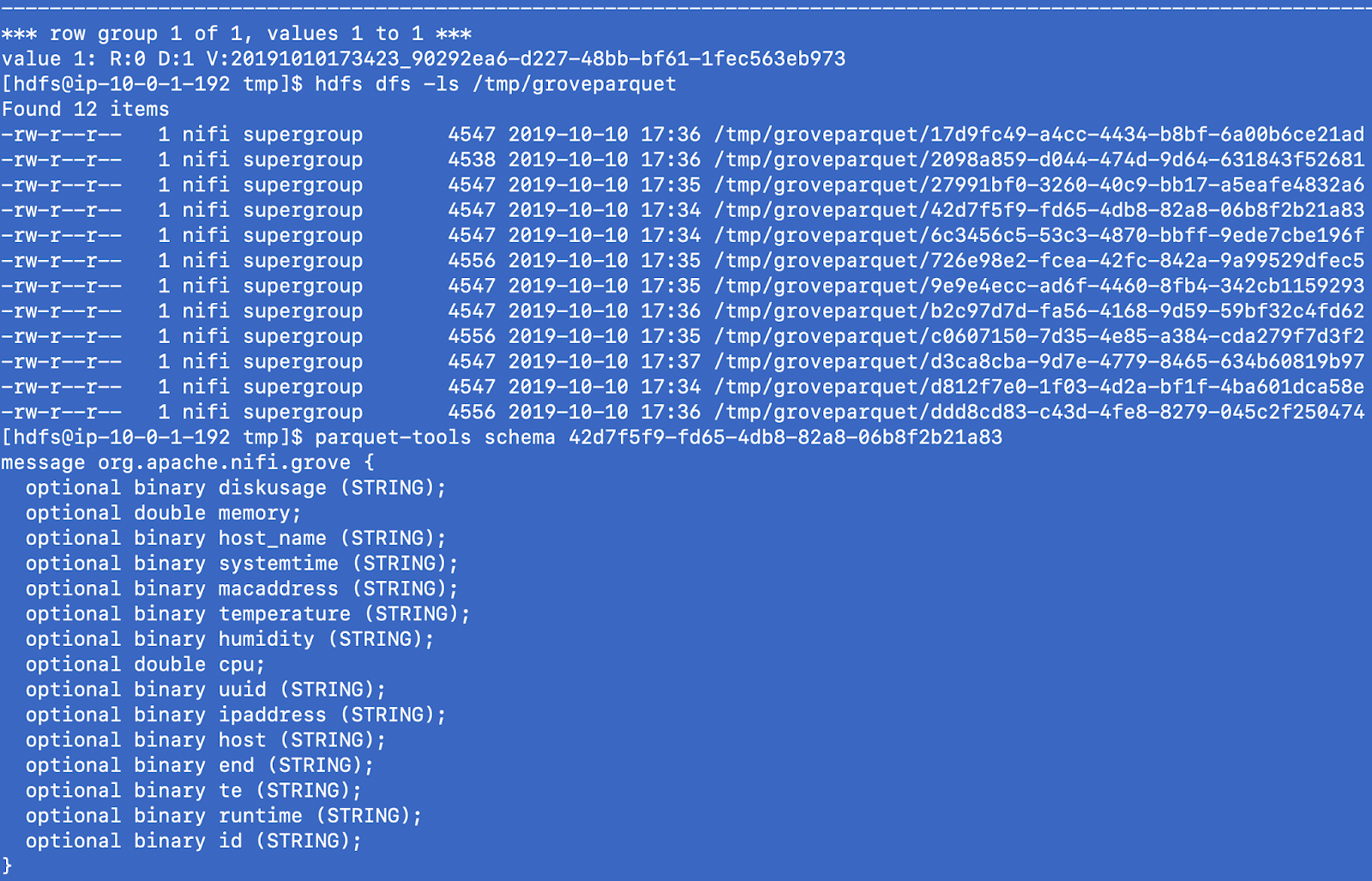
Let's query that parquet data with Impala in Hue

Let's monitor that data in Kafka with Cloudera SMM
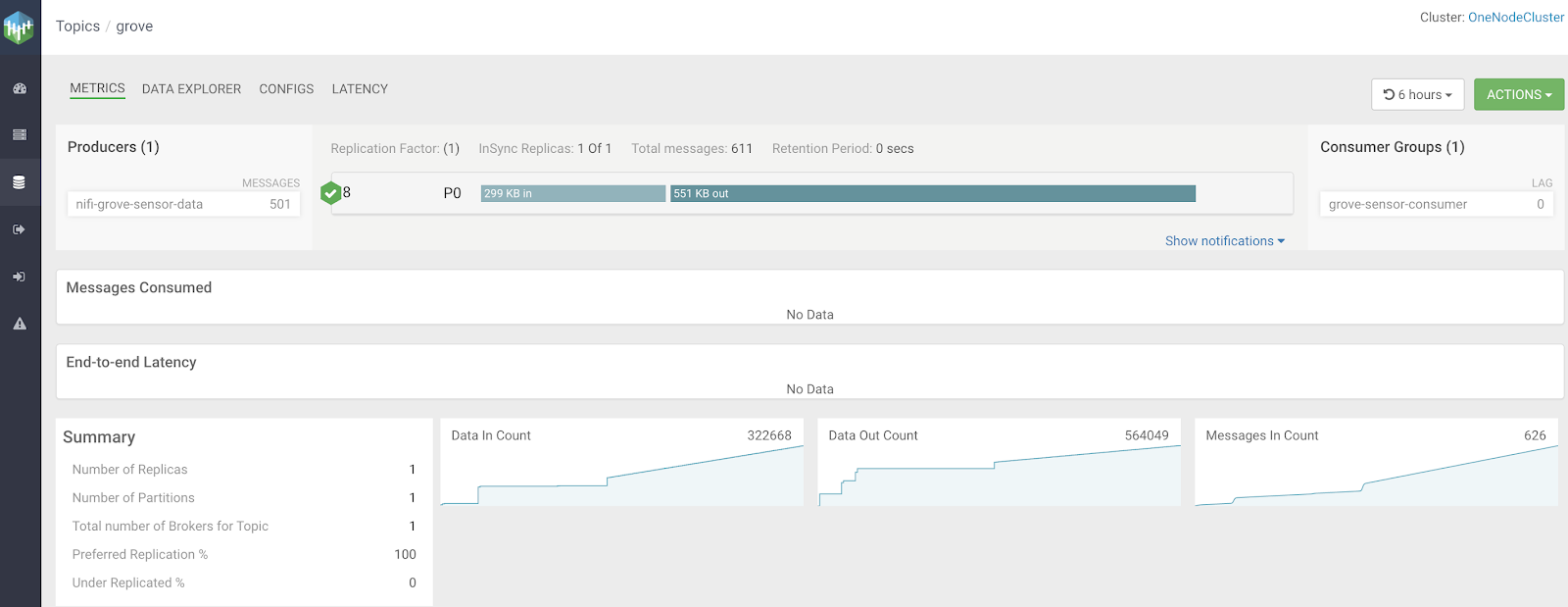

That was easy from device to enterprise cloud data store(s) with enterprise messages, security, governance, lineage, data catalog, SDX, monitoring and more. How easy can you ingest IoT data, query it mid stream and store it in multiple data stores. It took longer to write the article then to do the project and code. All graphical, Single Sign On, multiple schemas/verisons/data types/engines, multiple OSs, edge, cloud and laptop. Easy.
Table DDL
CREATE EXTERNAL TABLE IF NOT EXISTS grovesensors2
(humidity STRING, uuid STRING, systemtime STRING, runtime STRING, cpu DOUBLE, id STRING, te STRING, host STRING, end STRING,
macaddress STRING, temperature STRING, diskusage STRING, memory DOUBLE, ipaddress STRING, host_name STRING)
STORED AS ORC
LOCATION '/tmp/grovesensors'
CREATE TABLE grovesensors ( uuid STRING, end STRING,humidity STRING, systemtime STRING, runtime STRING, cpu DOUBLE, id STRING, te STRING,
host STRING,
macaddress STRING, temperature STRING, diskusage STRING, memory DOUBLE, ipaddress STRING, host_name STRING,
PRIMARY KEY (uuid, end)
)
PARTITION BY HASH PARTITIONS 16
STORED AS KUDU
TBLPROPERTIES ('kudu.num_tablet_replicas' = '1')
hdfs dfs -mkdir -p /tmp/grovesensors
hdfs dfs -mkdir -p /tmp/groveparquet
CREATE EXTERNAL TABLE grove_parquet
(
diskusage STRING,
memory DOUBLE, host_name STRING,
systemtime STRING,
macaddress STRING,
temperature STRING,
humidity STRING,
cpu DOUBLE,
uuid STRING, ipaddress STRING,
host STRING,
end STRING, te STRING,
runtime STRING,
id STRING
)
STORED AS PARQUET
LOCATION '/tmp/groveparquet/'
Parquet Format
message org.apache.nifi.grove {
optional binary diskusage (STRING);
optional double memory;
optional binary host_name (STRING);
optional binary systemtime (STRING);
optional binary macaddress (STRING);
optional binary temperature (STRING);
optional binary humidity (STRING);
optional double cpu;
optional binary uuid (STRING);
optional binary ipaddress (STRING);
optional binary host (STRING);
optional binary end (STRING);
optional binary te (STRING);
optional binary runtime (STRING);
optional binary id (STRING);
}
References
- https://github.com/apache/parquet-format
- https://docs.cloudera.com/documentation/enterprise/5-8-x/topics/impala_create_table.html
- https://docs.cloudera.com/documentation/enterprise/5-8-x/topics/impala_parquet.html
- https://github.com/tspannhw/minifi-grove-sensors
- https://github.com/tspannhw/GrovePi
- https://github.com/tspannhw/grove.py
- https://github.com/tspannhw/Grove-RaspberryPi
- https://seeeddoc.github.io/Grove-Ultrasonic_Ranger/
- http://wiki.seeedstudio.com/Grove-Ultrasonic_Ranger/

Top comments (0)