
Introduction
Adaptive Boosting or AdaBoost, like a random forest, is an ensemble learning algorithm. We can apply it to both classification and regression problems. As we know, ensemble methods combine several machine learning algorithms, and AdaBoost is commonly used with decision trees.
The core element of the algorithm is the decision stump. Each stump represents a node (e.g., a feature with a specific condition) with two leaves: one with data points where the condition is True and another one where the condition is False. Because individual stumps are not so efficient, they are called 'weak learners'. However, when 'weak learners' combined as an ensemble, and adaptive 'magic' boosting applied, they are quite efficient.
Algorithm
Let's dive into the details of how AdaBoost 'magic' works. For example, we have a binary classification problem, and the dataset has N features.
1) We create N number of stumps using all initial data. Then, the most efficient stump out of N is chosen, e.g., based on Gini index.
2)We calculate how much error (misclassifications) this stump made and using the log formula, the 'decision influence' (alpha) of this stump is calculated.
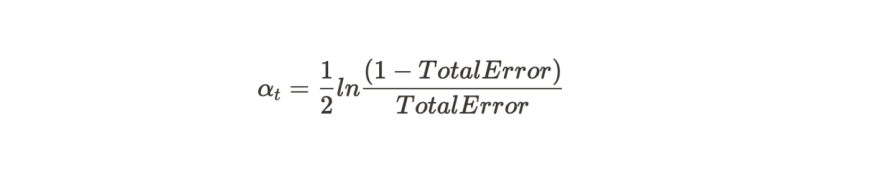
This decision influence will be used for the final decision when we sum up all the points of stumps concluding that it is a class 0 and class 1 separately. Depending on which class has more points, the final decision will be made.
3) At this step we need to prepare our initial data set for the modification. This preparation has two steps:
a) Initially all our data points(rows) have equal 'sample weight' [1/(number of rows)].
Now we need to update the 'sample weights' of each data point (row) based on the 'weak learner' correct and incorrect classification. If the stump is correctly classified, the data point (row), the sample weight will be reduced and if incorrectly then increased.
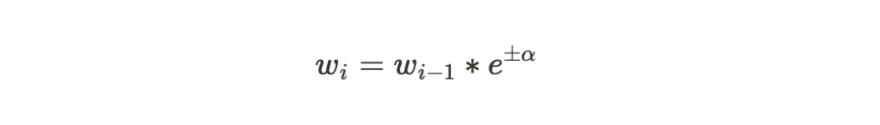
b) we create a new dataset using sampling with replacement and taking into account the sample weight we updated earlier. Basically, the higher the sample weight more chances that this data point will be duplicated in the new dataset. The size of the data set is kept the same as the original.
4) We repeat steps 1-3.
Note: in step 3a, we need to normalize 'sample weights', such that the sum of the weights equals 1.
Summary
AdaBoost's 'weak learners' (stumps) have a different influence on the final decision compared to Random Forest, where all trees have the same importance.
Also, AdaBoost has an iterative learning process, where each next learner 'influenced' by the previous leaner through the changed dataset. Whereas, Random Forest uses just random with replacement datasets without implying weight for each row during the process.

Oldest comments (0)