Why map reduce
Let's say you work on Facebook; you have lots of data and probably needs lots of map-reduce tasks.
You will use mrjob/PySpark/spark/hadoop. You got the point - you need 1 framework to rule them all.
You need a system: where will temp file be stored, API with cloud, data security, erasuer, multi-tenant etc..
You need standards - standards between developers to themselves, between developers to devops etc. ;
Let's say, for the other hand, your a solopreneur/small startup. Max 3-4 developers team.
You need things to work, and work fast.
Don't have 10ks of map-reduce jobs, but probably 1 or 2.
You won't be using hadoop, that's for sure. Might be using:
Different approaches
Linq
not really map reduce per se, more like "sql w/out sql engine"
However, this adds complexities of .net to your environment;
e.g. read release notes and understand if you can run it on your different OSes (production, staging, developers machines).
Also - need to learn C#; loading from files, different encodings, saving, iterators etc..
If you're not proficient with C#, this could be one-time investment which will not worth it.
Mrjob
Pros: Python native lib; able to debug easily (using inline) run locally e.g. multi process on local machine,
use hadoop, dataproc (seems that "Dataproc is a managed Spark and Hadoop service..." ) etc.
However, lots of moving parts and different configuration options.
Custom made map-reduce
Let's go to UCI Machine Learning website (2015 is on the phone..)
Choose some dataset, and test
Some notes:
We don't need Sha256 and not evey base64; nothing will happen if keys will not distribute very equally.
we could take MMH3; googling "python murmurhash" gives 2 interesting results; and since both use the same cpp code, let's take the one with most stars
Other options would be to simply do (% NUM_SHARDS) or even shift right (however must have shards count == power of 2).
mini setup script:
and 2 python test scripts:
Results:
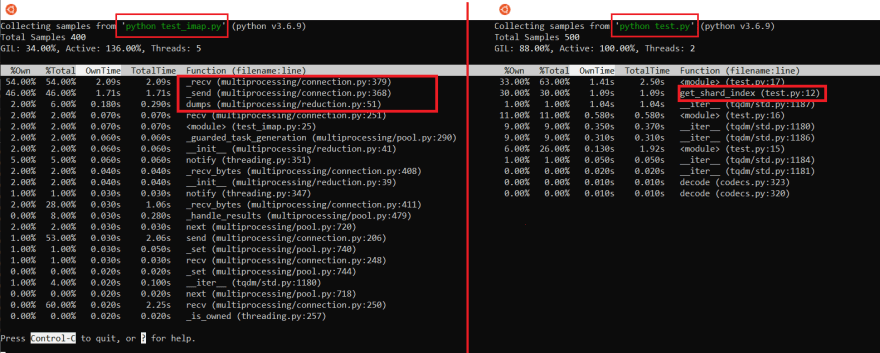
imap runs much slower;
we can look at it/sec from tqdm to see that:
# test.py sample after 4 seconds:
2801493it [00:04, 566075.99it/s]
# test_imap.py sample after 4 seconds:
73439it [00:04, 18754.44it/s]
We could see the non-imap version is 30x faster!
Q&A
Q: Why setup.sh and not requirements.txt file?
A: this is not production code; it's aimed for quick reproducibility, not for having exact same lib (e.g. security etc.)
Q: Why MMH3 and not sha256?
A: This is not a security product, we don't need cryptographic hash; we just need a nice distribution of keys, and we want this to be fast.
Q: Why is imap slower than single process?
A: Might be because the imap version has lots of overhead because of IPC;
The trade-off between offloading the (alleged) "heavy lifting" calculation of hash to external process is being erased by the IPC.
Q: Why?
A: Using process pool might worth it if task is more CPU bound; here, task is more io bound the overhead of MMH hash doesn't justify it.
Q: Are we sure about it?
A: we could use py-spy and see.
Q: Conclusion?
A: it depends
Also - depends on size of file.
Also - depends on post-processing each shard.
conclusion - test mrjob as well; it might have a better IPC.

Top comments (0)