My experience trying ‘Text2SQL’ recipe from llama-cookbook series!
Image from Meta’ llama-cookbook
Introduction
Reading about “llama” examples, I began tryin recipes which could be found of the llama-cookbook github repository. Having already been involved on a very specific text to SQL project for my job (much more complex than the example given on the cookbook’s repository) I wanted to give it a try, and it went so smoothly, and I’m much delighted ☺️. As always I share my experience with my peers. I didn’t do any modifications and used the code as is. However I got knowledge of two or three more things and tonight I’d be less dumb than last night 😂.
Implementation and running the code
First things first! The sample used “SQLite” database. My first discovery is that “SQLite” database exists already on most of current and up-to-date operating systems. Just open a terminal and type sqlite3!
░▒▓ ~/Devs sqlite3 127 ✘ base at 15:03:13 ▓▒░
SQLite version 3.43.2 2023-10-10 13:08:14
Enter ".help" for usage hints.
Connected to a transient in-memory database.
Use ".open FILENAME" to reopen on a persistent database.
sqlite>
To get familiar with the SQLite CLI go here: To get familiar with the SQLite CLI go here: https://www.sqlite.org/cli.html
I just installed a graphical database manager/viewer to use on my laptop!
brew install db-browser-for-sqlite
brew install db-browser-for-sqlite
==> Auto-updating Homebrew...
...
==> Downloading https://github.com/sqlitebrowser/sqlitebrowser/releases/download
==> Downloading from https://objects.githubusercontent.com/github-production-rel
######################################################################### 100.0%
==> Installing Cask db-browser-for-sqlite
==> Moving App 'DB Browser for SQLite.app' to '/Applications/DB Browser for SQLi
🍺 db-browser-for-sqlite was successfully installed!

Then I cloned the code repository on my laptop.
The steps I took to prepare the environment for my test.
python3.12 -m venv myvenv
source myvenv/bin/activate
pip install --upgrade pip
pip install -r requirements.tx
Regarding the sample code, I figured out that I’ll need an API key from “together.ai/”.
Together AI offers an API to query 50+ leading open-source models in a couple lines of code.
Just go the site, log into the site (in my case I used my GitHub credentials) and fetch your API Key! You can always access it from your dashboard beginning with “https://api.together.ai/?xxxxx….”.
Now back to the code. The code comes with sample files which makes it easy to populate a SQLite database. Just follow the readme file of the repository.
# run in the following order
# 1- convert sample text data provided to CSV format
python3 txt2csv.py
# 2- now make a db from the CSV
python3 csv2db.py
# 3- you'll obtain the nba_roster.db
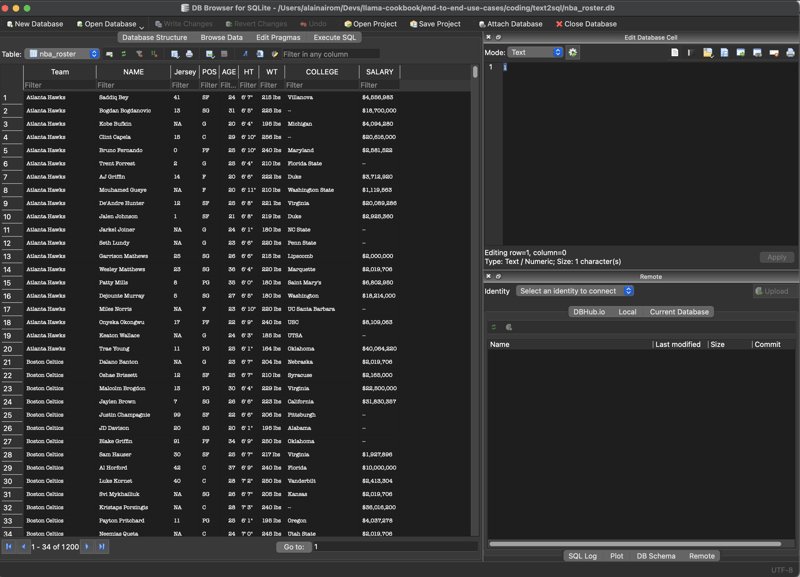
Access your database with the graphical tool.
Now run the sample notebook provided (answering sequences shortened a bit)!
!pip install --upgrade -r requirements.txt
...
Requirement already satisfied: sniffio in ./myvenv/lib/python3.12/site-packages (from openai<2.0.0,>=1.66.3->langchain-openai<0.4,>=0.3->langchain-together->-r requirements.txt (line 3)) (1.3.1)
Requirement already satisfied: tqdm>4 in ./myvenv/lib/python3.12/site-packages (from openai<2.0.0,>=1.66.3->langchain-openai<0.4,>=0.3->langchain-together->-r requirements.txt (line 3)) (4.67.1)
Requirement already satisfied: regex>=2022.1.18 in ./myvenv/lib/python3.12/site-packages (from tiktoken<1,>=0.7->langchain-openai<0.4,>=0.3->langchain-together->-r requirements.txt (line 3)) (2024.11.6)
Requirement already satisfied: mypy-extensions>=0.3.0 in ./myvenv/lib/python3.12/site-packages (from typing-inspect<1,>=0.4.0->dataclasses-json<0.7,>=0.5.7->langchain-community->-r requirements.txt (line 2)) (1.0.0)
...
import os
from langchain_together import ChatTogether
os.environ['TOGETHER_API_KEY'] = '99674315ea9ea526f74d76347bd9fada2d56bf5cdb77d5fffd8e25f46809a07b'
llm = ChatTogether(
model="meta-llama/Llama-3.3-70B-Instruct-Turbo",
temperature=0,
)
from langchain_community.utilities import SQLDatabase
# Note: to run in Colab, you need to upload the nba_roster.db file in the repo to the Colab folder first.
db = SQLDatabase.from_uri("sqlite:///nba_roster.db", sample_rows_in_table_info=0)
def get_schema():
return db.get_table_info()
question = "What team is Stephen Curry on?"
prompt = f"""Based on the table schema below, write a SQL query that would answer the user's question; just return the SQL query and nothing else.
Scheme:
{get_schema()}
Question: {question}
SQL Query:"""
print(prompt)
"""
Based on the table schema below, write a SQL query that would answer the user's question; just return the SQL query and nothing else.
Scheme:
CREATE TABLE nba_roster (
"Team" TEXT,
"NAME" TEXT,
"Jersey" TEXT,
"POS" TEXT,
"AGE" INTEGER,
"HT" TEXT,
"WT" TEXT,
"COLLEGE" TEXT,
"SALARY" TEXT
)
Question: What team is Stephen Curry on?
SQL Query:
"""
answer = llm.invoke(prompt).content
print(answer)
"""
SELECT Team FROM nba_roster WHERE NAME = 'Stephen Curry'
"""
result = db.run(answer)
result
"""
[('Golden State Warriors',), ('Golden State Warriors',)]"
"""
follow_up = "What's his salary?"
print(llm.invoke(follow_up).content)
"""
I don't have any information about a specific person's salary. This conversation just started, and I don't have any context about who "he" refers to. If you could provide more information or clarify your question, I'll do my best to help.
"""
prompt = f"""Based on the table schema, question, SQL query, and SQL response below, write a new SQL response; be concise, just output the SQL response.
Scheme:
{get_schema()}
Question: {follow_up}
SQL Query: {question}
SQL Result: {result}
New SQL Response:
"""
print(prompt)
"""
Based on the table schema, question, SQL query, and SQL response below, write a new SQL response; be concise, just output the SQL response.
Scheme:
CREATE TABLE nba_roster (
"Team" TEXT,
"NAME" TEXT,
"Jersey" TEXT,
"POS" TEXT,
"AGE" INTEGER,
"HT" TEXT,
"WT" TEXT,
"COLLEGE" TEXT,
"SALARY" TEXT
)
Question: What's his salary?
SQL Query: What team is Stephen Curry on?
SQL Result: [('Golden State Warriors',), ('Golden State Warriors',)]
New SQL Response:
"""
new_answer = llm.invoke(prompt).content
print(new_answer)
"""
SELECT SALARY FROM nba_roster WHERE NAME = "Stephen Curry"
"""
db.run(new_answer)
"""
"[('$51,915,615',), ('$51,915,615',)]"
"""
Quite easy ✌️
Conclusion
This document describes a basic hands-on experience with the llama-cookbook code repository. The code provided is easy and simple to use as-is. The samples provided could be adapted to entreprise use-cases.
Useful links
Meta’s LLama-CookBook: https://github.com/meta-llama/llama-cookbook
Together.ai: https://www.together.ai/

Top comments (0)