
Let's talk about pages. You know, like this

or infinite scrolling pages like this
Because we never want to give our website visitors all of our data, we present them in pages and let users load more as they please.
One method of paging, AKA pagination, in SQL that's easy is to limit a query to a certain number and when you want the next page, set an offset.
For example, here's a query for the second page of a blog
SELECT * from posts
ORDER BY created_at
LIMIT 10
OFFSET 10
However, for larger databases, this is not a good solution.
To demonstrate, I created a database and filled it 2,000,000 tweets. Well, not real tweets but just rows of data.
The database is on my laptop and is only 500mb in size so don't worry too much about the specific numbers in my results but what they represent.
First, I'm going to explain why using offset for pagination is not a good idea, and then present a few better ways of doing pagination.
Offset Pagination
Here's a graph showing how much time it takes to get each page. Notice that as the page number grows, the time needed to get that page increases linearly as well.

Results:
200,000 rows returned
~17.7s
~11,300 rows per second
** unable to paginate all 2 million rows under 5 minutes
This is because the way offsets works are by counting how many rows it should skip then giving your result. In other words, to get the results from rows 1,000 to 1,100 it needs to scan through the first 1,000 and then throw them away. Doesn't that seem a bit wasteful?
And that's not the only reason why offset is bad. What if in the middle of paging, another row is added or removed? Because the offset counts the rows manually for each page, it could under count because of the deleted row or over count because of a new row. Querying through offset will result in duplicate or missing results if your data is ever-changing.
There are better ways to paginate though! Here's one
Order Based Pagination
You can page on pretty much anything you can order your data by.
For example, If you have an increasing id you can use it as a cursor to keep track of what page you were on. First, you get your results, then use the id of the last result to find the next page.
SELECT * FROM tweet
WHERE id <= $last_id
ORDER BY id DESC
LIMIT 100
2,000,000 rows returned
~4.2s
~476,000 rows per second
This method is not only much faster but is also resilient to changing data! It doesn't matter if you deleted a row or added a new one since the pagination starts right where it left off.
Here's another graph showing the time it takes to page through 2 million rows of data, 100 rows at a time. Notice that it stays consistent!
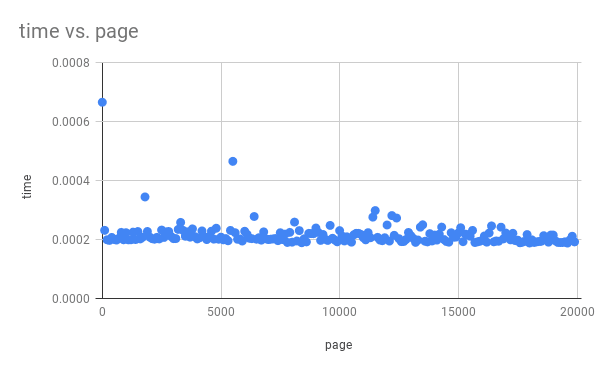
The trade-off is that it cannot go to an arbitrary page, because we need the id to find the page. This is is a great trade-off for infinite scrolling websites like Reddit and Twitter.
Time Pagination
Here's a more practical example of pagination based on the created_at field.
It has the same advantages and one drawback as ID pagination. However, you will need to add an index for (created_at, id) for optimal performance. I included id as well to break the tie on tweets created at the same time.
CREATE INDEX on tweet (created_at, id)
SELECT * from tweet
WHERE (created_at, id) <= ($prev_create_at, $prev_id)
ORDER BY created_at DESC, id DESC
LIMIT 100
2,000,000 rows returned
~4.70s
~425,000 rows per second
Conclusion
Should you really stop using OFFSET in your SQL queries? Probably.
Practically, however, you could be completely fine with slightly slower results since users won't be blazing through your pages. It all depends on your system and what trade-offs you're willing to make to get the job done.
I think offset has its place but not as a tool for pagination. It is much slower and less memory efficient than its easy alternatives. Thanks for reading!
✌🏾

Top comments (41)
It's always about memory vs CPU: using the ID is much faster because the ID field is usually the primary key hence it's indexed, meaning each value is literally assigned a number internally because numbers are great for sorting. For example, when the machine sees "WHERE id > 123 LIMIT 10" it can throw out any smaller id right away and just get those 10 rows, while "OFFSET 123 LIMIT 10" means you perform a query getting 133 rows and then discard 123 rows.
In order to get rid of OFFSET in pagination queries and still have filters in the WHERE clause and custom sorting, you just need to index any table field you want rows to be sorted by, so that each row of that field internally has a number to refer to.
That’s a good clarification, the cursor pagination methods rely on there being an index to reduce the lookup time for the where clause.
Without an index the query goes much slower.
Did you have any performance charts on the second technique outlined? Curious to know if having a slightly more complex
WHEREclause with two sorted columns affects performance much when dealing with ~2M rows.Also: Was this MySQL? I wonder if different databases have similar results. Worth noting in case results vary between the SQL DB's out there. Since I'm lazy and I'd be interested in tinkering with this first hand, do you still have the source code you used to generate these stats? Specifically, the code used to generate the fake data (e.g. script inserting output from Faker)?
Thanks for the article!
Found my code and added it to GitHub here github.com/Abdisalan/blog-code-exa...
I've also included the db schema sql file to help create the database. Also, each file is named after what pagination method they use and I collected the data by outputting the times into a file like this:
The performance when sorting with two columns was slightly slower, running at 425k rows per second vs 476k. I don’t have the charts for that one unfortunately, I should have made it before I deleted the DB!
The database was in PostgreSQL, I wonder if another db would perform better 🤔
The script is also gone! 😢 I can try to recreate it and get back to you though.
Thanks for reading!
(sorry, I didn't actually read anything but the title) ... you could pull in all of the data at once and let your (application) code send it out in chunks which would mean you could write the SQL any way you wanted (code review should clean it up)
or if you have database access: write a function or procedure from that side to help.
using indexes (and partitioning for huge table) really helps
I promise the rest of the article is good too 😂
Ok, I read it :-)
I've never used 'offset' because it doesn't seem like a good idea to me (though I do keep an eye out for an actual use case) .. but I'm also writing apps that are used on a robust enterprise WAN and have access to ... well .. just about anything I could possibly need from a hardware prospective so YMMV
This is exactly right. More pertinently, ORMs should be providing this manner of pagination by default. The other reason is because if database rows are inserted inbetween queries, the pagination will start to overlap.
Absolutely, this should be standard or at least an option in most ORMs!
Markus Winand maintains a "hall of fame" for data access tools which offer keyset pagination.
That’s awesome! Thanks for sharing 🤩
This was a terrific and quick read. My MySQL skills are limited but this makes perfect sense for getting in/out of the db as efficiently as possible (though it's an interesting proposition to just grab all results and filter server-side, away from the db). Great stuff.
Thanks! Glad you liked it!
Great article! I guess I never thought about ever-changing data with long pagination.
Mini-tip: avoid the trap of clickbaits! You can better title the article, like "1 SQL feature" instead, or even mentioning paging directly.
I'd worry about using an auto-incremented ID column as the offset. I imagine in practice that they're sequential, but I don't think it's part of the spec (of course, I'm no expert). I have seen MySQL and Postgres spit out rando indexes though.
Like @robloche mentioned, I think using OFFSET + FETCH might help with the issue. It'd be interesting to see results, anyway. Postgres supports it.
The auto-incremented ID was just a demonstration that you can use any ordered column. I'll have to look into FETCH! There are so many awesome suggestions from this community 😁
Are you talking about MySQL?
Because I have an SQL Server stored procedure that uses OFFSET and FETCH NEXT to browse through a 500K-row table and the execution time is stable throughout the table.
I'm using PostgreSQL and no stored procedures. That's awesome that MySQL can do that!
Sorry for the confusion. I'm using SQL Server, and yes, it seems correctly optimized for this situation.
I am not good in this aspect but wouldn't indexing help in this ?
With the disclaimer that I'm no expert, there are two different types of index:
Interesting, I'll have to learn more about this Luke. Good point!
That's okay! I'm learning as well :)
In my testing, I used an index to help with the OFFSET and the results are improved but still no where near as good as the cursor method.
The results you see in the article are me using an index.
I already know about the internals of pagination. But how can we avoid this if we have a Pool of items with one to ten filters where the user can decide which filter he combines and how he sorts . Is there a solution available that gives me always ten items per page (except the last page of course)?
As long as your results are ordered, you can use this method with any number of filters. You'll have to get creative on how to add the filters, because you don't want to create 2^10 SQL statements for every combination of filters.
The solution would be to pick 1 or 2 fields you can order your results by and then apply your filters as well. You can query the next page based on the field you are ordering your data by.
Example query for employees where the filter is the department and whether they are on vacation and order by birthdays
Hope that helps