
As a computer vision engineer, you are often expected to be able to suggest the best model for a problem statement. It can be tempting to resort to your favorites or choose models that you tend to use often. But truly understanding the best models and staying updated can take time and effort. So, here are the top six instance segmentation models to remind you of your options!

Quick Reminder
Before we dive into the models, let’s revisit what instance segmentation is. It is the crucial process of splitting an image into multiple regions based on the different characteristics of pixels.
So, where can it be used, and why is it relevant? Instance segmentation helps with identifying objects or boundaries of regions within an image, helping machines to better simplify the image and more efficiently analyze it for many different tasks and applications.
Applications of Instance Segmentation
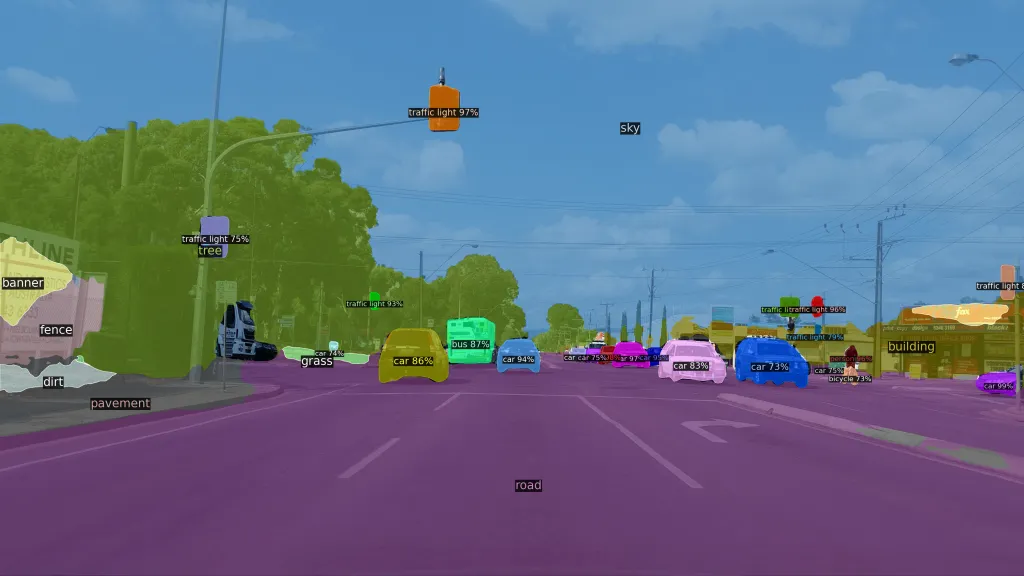
Instance segmentation is fundamentally changing how we do things in various industries. Take self-driving cars, such as Teslas, for instance. They rely on this tech to see and understand everything around them, from other cars and pedestrians to any obstacles in their path. It's this detailed view at the pixel level that allows these vehicles to navigate safely, avoid obstacles, stay in their lanes, and get where they need to go without a hitch.

An example of instance segmentation being used to analyze the street at a stoplight. Source
In healthcare, the impact of image segmentation is equally impressive. It's transforming the way medical images, like MRI scans, CT scans, and X-rays, are analyzed. By picking out specific structures or spotting something out of the ordinary, this technology helps catch things that might otherwise go unnoticed, aiding doctors in diagnosis and treatment planning. It's also proving to be a game-changer in research, helping with everything from counting cells to studying tissues.

An example of brain tumor detection using image segmentation. Source
Manufacturing is another area where image segmentation is proving invaluable. It's being used to spot defects in products or components by analyzing images or videos for any flaws. This is a massive plus for industries like electronics and automotive, where spotting a faulty component on a circuit board or identifying a dent on a vehicle body can mean the difference between a quality product and a defective one.

Using instance segmentation to detect dents. Source
By improving inspection accuracy and speed, this tech not only helps maintain high-quality standards but also cuts costs and reduces the need for manual checks. Through its diverse applications, instance segmentation is proving to be an essential tool in the modern technological toolkit.
Top 6 Models For Instance Segmentation
Next, let’s take a detailed look at the top 6 instance segmentation models that are being used today.
1) Segment Anything Model (SAM)
The SAM model does exactly what it says and can segment anything. Released in April of 2023 by Meta Research, SAM is a promptable image segmentation system that has zero-shot generalization capabilities. Which means it can segment unfamiliar objects in images without much training.
The model was trained on a big dataset called SA-1B (1 Billion Mask). Because of this training, it works really well in several areas. These areas include remote sensing, general computer vision, and medical imaging.
Another interesting application of SAM is its use in annotation tools. Tools like Auto-Segment by Annotab AI use SAM to automate the detection and outlining of objects in images. This technology can create detailed, pixel-perfect masks around each identified item. The capability to auto segment proves to be immensely beneficial in a wide range of industries.
For instance, in the retail industry, it can accurately separate products in images for cataloging or online presentation. The efficiency and precision of SAM-equipped tools significantly enhance productivity and accuracy in tasks that traditionally require time-consuming manual effort.

An example of SAM being used to make image annotation simpler and more efficient.
The basic working of SAM can be broken down into two steps. The first step includes a featurization transformer block that can take images and individually compress them to a 256x64x64 feature matrix. These features are then passed on to the next step, which involves a decoder head. The decoder head can accept the model’s prompts, whether that be a rough mask, labeled points, or simple text prompts.

The Segment Anything Model Structure Source
2) Mask R-CNN
Mask Region-based Convolutional Neural Network, or Mask R-CNN for short, is an extension of the Faster R-CNN object detection algorithm, used for object detection and instance segmentation tasks in various computer vision projects. It was developed in 2017 by Facebook AI Research, and its key innovation is its ability to perform pixel-wise instance segmentation along with object detection.
This is achieved by adding an extra "mask head" branch, which can generate precise segmentation masks for each detected object. The model was able to achieve better results than the more intricate model like FCIS+++, which incorporates multi-scale training/testing, horizontal flip testing, and OHEM.

The working of the Mask R-CNN Image Segmentation Model. Source
The working of the Mask R-CNN model begins with a CNN-based backbone like the feature pyramid network (FPN) that extracts feature maps from input images. This is done by extracting high-level features from the input image, combining high-level semantic information with lower-level feature maps by forming connections between different backbone network levels, and arranging them in a pyramid where the top level contains high-resolution features.
The Region Proposal Network then processes the feature maps, which will generate regions of interest (ROIs) that may contain objects. Fixed-size feature maps from each ROI are then extracted for further processing by ROI Align. The final stage involves the generation of bounding boxes and class labels for the detected objects, along with a mask for each ROI. This mask defines the shape of the detected object at the pixel level.
3) YOLACT
YOLACT is another innovation from Facebook AI Research. Developed in 2019, YOLACT, or ‘You Only Look At Coefficients,’ is a groundbreaking computer vision approach for real-time instance segmentation. This model is a real game changer for its unique blend of efficiency, accuracy, and simplicity. YOLACT is best for applications that require real-time processing, like autonomous vehicles or real-time video analysis.
A major advantage of this model is the separation of mask generation into prototypes and coefficients. By doing so, it simplifies the overall network, reducing the computational overhead and making the model easier to train and deploy.

The Working of the YOLACT model. Source
As mentioned earlier, YOLACT instance segmentation separates mask generation into prototypes and coefficients. It first generates the prototype masks, generalized shapes covering different object structures in the image. These prototypes act as a foundational reference for any object in the image.
Simultaneously, YOLACT predicts per-instance coefficients, which are unique to each object, dictating how the prototype masks are blended. Finally, by combining the prototype masks with the per-instance coefficients, YOLACT produces precise final instance masks for each object in the image.
4) FastSAM
FastSAM was developed by the Chinese Academy of Sciences Image and Video Analysis Group (CASIA) in 2023, and it uses the Ultralytics YOLOv8 instance segmentation architecture for training. Unlike its predecessor, the Segment Anything Model (SAM) we discussed earlier, FastSAM is trained on only 2% of SAM's data, yet it maintains high accuracy while demanding lower computational resources.
It can get a remarkable 63.7 at AR1000, and it outperforms SAM by 1.2 points using 32×32 point-prompt inputs. FastSAM is also designed to be compatible with consumer-grade graphics cards, which makes it accessible to a wide range of users. FastSAM demonstrates adaptability and flexibility across different scenarios with its ability to segment any object within an image, guided by different user interaction prompts.

FastSAM vs SAM Source.
FastSAM works in two main steps. The first step is detection, where it finds all the objects in an image and draws boxes around them, and then comes segmentation, where it figures out the exact shape of each object. It does this by creating different shapes called prototypes for each object and figuring out how these shapes fit together to form the object. Both detection and segmentation are done simultaneously, making it fast.
In the second step, FastSAM uses different ways to help it find the object you're interested in. It can do this by looking at specific points you select on the object, comparing a box you draw around it with the boxes it already created, or reading a short description of the object. These methods help FastSAM focus on the object you want to find, even if many other objects are in the image.
5) DETIC

An output example of DETIC. Source
Detic is a segmentation model introduced by Facebook Research in January of 2022 and designed for object detection applications. It stands out for its ability to accurately identify a wide range of objects, even those that are traditionally challenging to detect, without requiring retraining. This efficiency is complemented by its unique feature of being trained solely on image annotations, which prevents the need for object-bounding boxes.
Detic achieves this through Weakly-Supervised Object Detection (WSOD), which enables training without explicit bounding box annotations. This approach simplifies the overall training process and enhances the model's adaptability to new objects, making it a valuable and time-saving solution for object detection tasks.
6) OneFormer
Oneformer, which was created in 2022 by a group of AI research scientists, including Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, and Humphrey Shi, is a groundbreaking model that combines semantic, instance, and panoptic segmentation into a single approach. Unlike traditional methods that require separate training for each task, Oneformer uses a unified framework covering all image segmentation aspects.
This innovative approach simplifies the overall training process and allows for more efficient segmentation. Researchers tested Oneformer on three popular datasets, Cityscapes, ADE20K, and COCO, demonstrating its effectiveness across various segmentation tasks.

OneFormer Performance on Popular Datasets. Source
OneFormer moves away from the conventional approach of using convolutional neural networks (CNNs) as its foundation. Instead, it adopts transformers, which allows it to use its ability to capture global relationships within an image. This departure leads to a more subtle understanding of context, resulting in more accurate segmentation.
A distinctive feature of OneFormer is its use of a task-conditioned joint training strategy. This strategy involves training the model on a single dataset for panoptic segmentation while predicting semantic, instance, and panoptic labels. This approach enhances the model's efficiency and effectiveness in understanding and segmenting complex visual scenes.
Comparing The Models Side By Side
So far, we’ve looked into the top 6 instance segmentation models and their workings. Now, let’s take a look at all of them side by side. The following breakdown clearly distinguishes between the key aspects of all the above-mentioned models, from the strengths and weaknesses to the tasks they are best suited for.
| MODEL | DEVELOPED BY | YEAR | STRENGTHS | WEAKNESS | BEST SUITED FOR |
| SAM | Meta AI | 2023 | Zero-shot, versatile, integrated tools | Can be less precise, needs text prompts | Rapid prototyping, low data scenarios |
| Mask R-CNN | Facebook AI Research
(FAIR) |
2017 | Strong baseline, well-established | Less speed-focused | General robust instance segmentation |
| YOLACT | Facebook AI Research
(FAIR) |
2019 | Real-time speed, simpler for videos | May sacrifice some accuracy for speed | Video analysis, high-frame-rate apps |
| FASTSAM | Chinese Academy of Sciences Image and Video Analysis Group
(CASIA) |
2023 | Generalize well, efficient & small | Still evolving, some precision trade-off | Limited resources, deployment on devices |
| DETIC | Facebook Research | 2022 | Transformer-based innovation, open-source | Less mature, complex to implement | Experimentation, pushing performance limits |
| OneFormer | Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi | 2023 | Streamlined for multiple tasks, efficient | Might be unnecessarily complex for simple tasks | Projects with many similar image tasks |
Conclusion

Congratulations! Source
We've covered the top six instance segmentation models, each offering unique advantages and disadvantages. Picking the right model for what you need depends on what the application specifically requires.
Always remember to stay updated with the latest in AI. Thank you for joining me on this exploration. Farewell until our next deep dive.
FAQs
What's the difference between semantic, instance, and panoptic segmentation? Semantic segmentation involves assigning each pixel in an image to a specific class, such as "dog," "car," or "road," focusing on the content of the image rather than individual instances. Instance segmentation goes further by not only identifying classes but also distinguishing between individual objects within those classes, such as "dog 1," "dog 2," and "car 1." Panoptic segmentation merges these two approaches, making sure that every pixel receives both a class label and an instance ID if it relates to a countable object.
How are models like YOLACT, Mask R-CNN, and OneFormer changing image segmentation? Models like YOLACT, Mask R-CNN, and OneFormer are changing image segmentation in three key ways. First, they are improving performance by being more accurate and faster. For example, Mask R-CNN is great for detailed instance segmentation, while YOLACT is best known for its real-time segmentation. Second, these models are becoming more versatile. OneFormer, for instance, aims to do many types of segmentation with just one flexible design. Lastly, they are making segmentation much easier. Models like FASTSAM and Detic show that you can get good results with less data or special training methods like weakly supervised learning.
Where can I learn more and try out image segmentation? If you're looking to learn more and try out image segmentation, there are several sites you can explore. For courses and tutorials, platforms like Coursera and Udemy offer many options, from foundational computer vision to in-depth studies of specific models. Frameworks like TensorFlow and PyTorch provide pre-trained models and guides for using your custom dataset images. Open-source datasets like COCO and CityScape are also available for experimentation and benchmarking.

{kind=link}
{kind=link}
{kind=link}
Top comments (0)