The master-slave concept has been around for a while now. This is a fairly simple concept actually, all you need to understand is that there is one master and there are many slaves. Master-slave is a way to optimize the I/O in your application other than using caching. The master database serves as the keeper of information, so to speak. The true data is kept at the master database, thus writing only occurs there. Reading, on the other hand, is only done in the slave. What is this for? This architecture serves the purpose of safeguarding site reliability. If a site receives a lot of traffic and the only available database is one master, it will be overloaded with reading and writing requests. Making the entire system slow for everyone on the site.
Visualization of an implementation
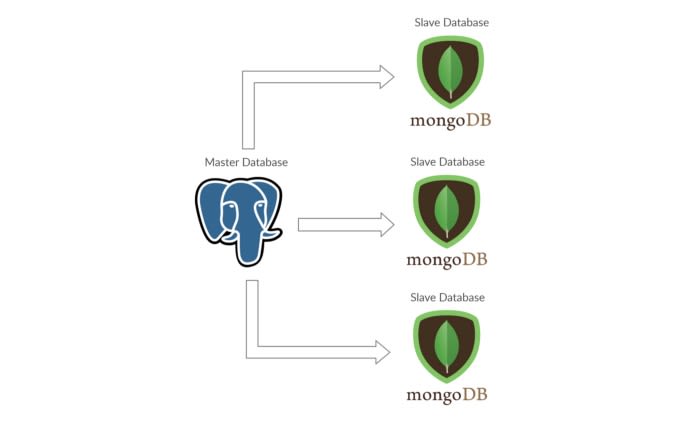
In the example diagram, I use Postgresql as my master. Postgres is a relational database. Relational databases are structured and easy to maintain. For the slave, I use MongoDB because MongoDB is a non-relational database or NoSQL. You can learn how to implement this architecture in a blog post by Greg Sabino. Though slave databases don’t have to be NoSQL, there is another example of using MySQL as both master and slave. Having one type of database for both master and slave can serve to be convenient because in the end maintaining the codebase will be a lot easier.
The process for handling the data transfer/synchronization from the master to slave databases is called replication. To replicate data you can, for example, use a serverless function as a pipeline to distribute data to the slaves. Making your own solution to replicate databases can be tedious so I recommend a database replication tool. Here is a list of database replication tools in 2020 by g2.com. You can also make an insert function to add data to both master and slave databases if you want to do realtime data management.
Wait, what?
Why is the master-slave concept a thing? Well imagine it this way, you are trying to manage a large scale system and you end up with a server bottleneck. A few debug later you find out one of the causes is the read/write traffic to your database server. You stop and think. “What now?” one of the solutions would be to apply master-slave. Sure this might not be the first thing to come to your mind, other methods such as using a Redis cluster might be enough to sustain yourself for a few years, but this concept can be another great option.
Well, obviously the downside would be the insurmountable complexity surrounding this setup. You would need a team of dedicated systems and database administrators to be able to pull this off on a large scale system infrastructure. Not saying that it’s impossible but just saying that some costs outweigh the benefits.
Opinions
Costs
Compared to add more clusters to Postgres/SQL Server setup I would say the master-slave concept would be cheaper and could have similar or even better results than the former.
In the end, how much traffic would a relational database efficiently handle? Probably a lot, but not as much as about 3 MongoDB slave clusters. I’m not implying that 3 MongoDB clusters are more efficient than a single relational database but in the long run, I would say having NoSQL slave databases could be an advantage.
Implementation differences
In a way, the master-slave concept can be interpreted as a method to cache data from the master to all the slave databases, so to add a simple Redis implementation to your system can technically work as a master-slave system though this concept is not entirely about caching. The initial purpose is to help users get data from the database faster, any data. To help you visualize how I would do master-slave, see the diagram below:
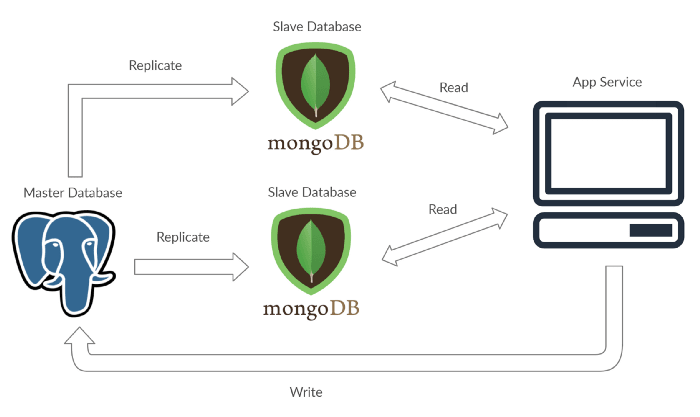
Implementing caching wouldn’t really help the database much either. Caching will only result in select data that will be available on your cache. If the data requested is not available then the reading process will happen in the master. Implementing caching is great to optimize your site, but the master-slave concept works better if we have a separate data source identical to the master that can be used to read. Here is how I imagine caching would be, this is not an example of how to do master-slave:
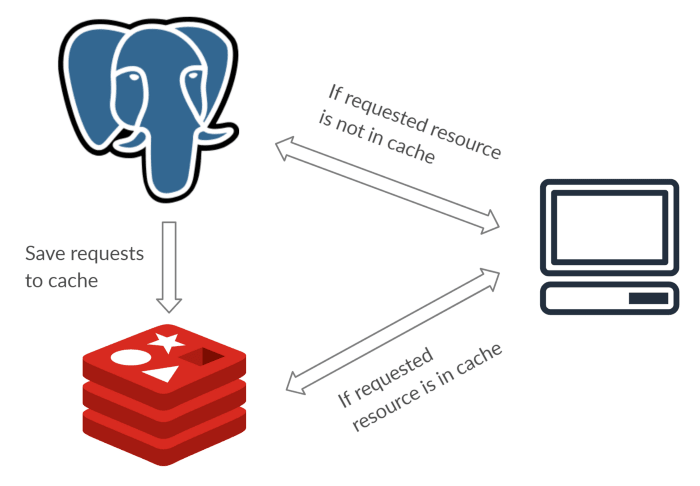
In the example above, the architecture is an example of how caching and master-slave is different. To do a master-slave WITH caching I would probably do it like this:

Architecture Complexity
Imagine this, you already have enough trouble having to code and keep your business afloat and now you burden yourself and your team with an additional load to constantly manage a master-slave system.
To be honest, many things can go wrong here. What do you do when you have a failed replication? How long does the synchronization between the master Postgres database and MongoDB should take? Wouldn’t Redis suffice? Why should you bother in the first place?
Look there are many reasons to choose this architecture also as many reasons not to. The fact of the matter is, this is an option if you deem yourself ready and capable to handle a master-slave database system then go for it! It may just benefit your organization. I’m not evangelizing this concept I’m just trying to share this concept to programmers who do not know beforehand.
An easy way would be to use a distributed database like CosmosDB a NoSQL MongoDB alternative from Microsoft Azure. CosmosDB works by adding clusters to itself and it’s data to handle exceptional loads. Thus, when using this service on Azure you are charged on the RU (a type of data read/write meter used for CosmosDB) usage rather than the number of CosmosDB clusters active.
But let’s face it, sometimes an easy way out is just not fun!
We need thrill in our lives, people! The thrill of making a master-slave system would be an experience you should not pass up if had the chance.
Conclusion
To summarize master-slave database architectures are usually used to help stabilize the system. Because reading data can be done through the slave database while inserting data needs to be done to the master database. Synchronizing data from the master to slave is called data replication, and some techniques to get realtime data can involve inserting in both master and slave database to even realtime data replication depends on your needs. To help you understand more regarding master-slave database architecture here are some good resources for you to check out:
- Database Master-Slave Replication in the Cloud — MariaDB
- Master-master vs master-slave database architecture? — Stackoverflow
- Master-master vs master-slave database architecture? — IntelliPaat
- What are Master and Slave databases and how does pairing them make web apps faster? — Quora
- Master/slave (technology) — Wikipedia
A special thanks to Richard M Simarmata for the valuable inputs.

Top comments (0)