
Step-Video-T2V is creating a buzz in the AI community, and for a good reason. This model represents a revolutionary leap in text-to-video technology by combining massive-scale training with innovative architectural design. Whether you’re an AI enthusiast, a tech hobbyist, or a professional in the creative industry, this model promises to transform how you generate video content from simple text prompts. In this article, we’ll explore what sets Step-Video-T2V apart, dive into its unique features and technical breakthroughs, explain how to run it on various platforms, and see why it might just be the game changer you’ve been waiting for.
Jumpstart Your Creative Journey with Anakin AI!
Imagine having every cutting-edge AI model at your fingertips in one seamless platform. With Anakin AI, you can effortlessly generate stunning videos using breakthrough models like Step-Video-T2V, craft eye-catching images, produce engaging audio, and so much more—all under one roof. Whether you're an innovator, content creator, or tech enthusiast, Anakin AI is your gateway to transforming ideas into immersive experiences. Remember, the city will be for Anakin AI—join the revolution today and see where your creativity can take you!
A Deep Dive into Step-Video-T2V

Unpacking the Technology
Step-Video-T2V is no ordinary AI model. With a staggering 30 billion parameters, it harnesses the power of deep learning to create videos that can stretch up to 204 frames. The journey begins with a robust, three-stage training methodology:
Text-to-Image Pre-training:
The model kicks off by learning from 5 billion image-text pairs. This stage is crucial as it builds a solid foundation in spatial understanding, enabling the AI to capture intricate details in each frame.Joint Text-Video/Image Training:
Next, the model incorporates 1 billion video-text pairs, which helps it grasp temporal changes and motion dynamics. This training allows the model to understand not just static images but also the flow and continuity between frames.High-Quality Fine-Tuning:
Finally, with 100 million premium video-text pairs, the model fine-tunes its skills. This stage refines its ability to generate smooth, high-quality videos that align closely with the prompts provided.
Think of it as an intensive boot camp for an AI—every layer and parameter is trained meticulously, ensuring that the model can turn even the simplest of text prompts into a dynamic, immersive video experience.
Step-Video-T2V Technical Innovations
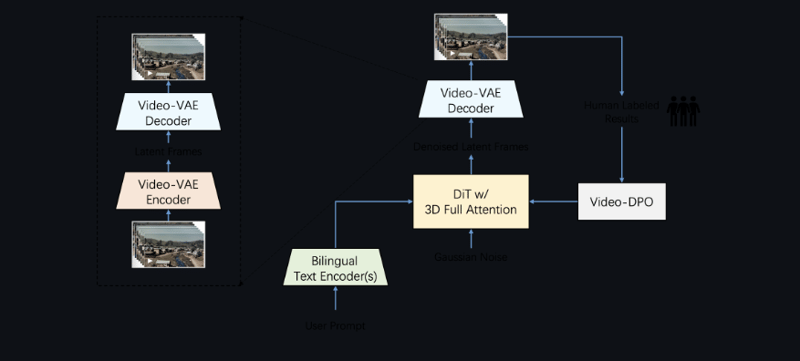
One of the standout features of Step-Video-T2V is its Video-VAE Compression technology. This method compresses video data both spatially and temporally, achieving a 16×16 compression ratio in space and an 8× compression ratio in time. The result? The model can generate lengthy video sequences without sacrificing quality or detail.
In addition, the model employs a 3D Full-Attention Diffusion Transformer (DiT). With 48 layers and advanced techniques like RoPE-3D positional encoding and QK-Norm stabilization spread across 48 attention heads, this architecture ensures that every detail—from subtle movements to complex scene changes—is rendered with precision.
Another breakthrough is the model’s bilingual processing capability. By using dual text encoders (one for English and one for Chinese), Step-Video-T2V can interpret and generate content in multiple languages. This opens up a world of possibilities for global content creators who wish to work beyond language barriers.
What Sets Step-Video-T2V Apart?
Superior Video Quality and Fluid Motion
When you compare Step-Video-T2V with other models like Sora, Veo 2, or Gen-2, its strengths become immediately clear:
- Higher Frame Capacity: The model can generate videos up to 204 frames long. This means longer, more detailed video outputs that can capture intricate motion dynamics.
- Advanced Attention Mechanism: The use of a 3D full-attention approach means the model not only understands the spatial details but also the flow of time between frames. This results in videos that are both visually stunning and fluid in their motion.
- Multilingual Support: While many competitors only support English, Step-Video-T2V handles both English and Chinese. This dual capability makes it a truly global tool.
- Enhanced Motion Dynamics: Evaluations show that this model delivers smoother transitions and more realistic motion, making it ideal for complex scenes where every nuance matters.
One user remarked, “Using Step-Video-T2V felt like having a powerhouse at my fingertips—it just gets what I mean, even when the prompt is a bit off the beaten track!” Such testimonials underline the model’s ability to convert abstract ideas into coherent, visually engaging videos.
Efficiency Through Advanced Compression
The genius behind Video-VAE compression is in its ability to shrink the data needed for video generation without losing fidelity. By efficiently compressing both spatial and temporal components, the model can produce high-quality videos even when dealing with long sequences. This not only speeds up the generation process but also ensures that each frame retains its clarity and detail.
Versatility for Creators
Step-Video-T2V is designed to be a versatile tool. Whether you’re envisioning a futuristic cityscape, a serene nature scene, or an action-packed sequence, the model adapts to your creative vision. Its impressive prompt adherence means even complex or nuanced descriptions are faithfully translated into dynamic video content. This level of creative control is a major boon for artists, filmmakers, and anyone looking to push the boundaries of conventional video production.
How to Use Step-Video-T2V Locally
For those eager to explore the model hands-on, there are several ways to deploy Step-Video-T2V based on your operating system.
Running on Linux (Recommended)
Linux remains the platform of choice for running Step-Video-T2V due to its compatibility with high-performance hardware.
Hardware and Software Requirements:
- Hardware: A robust setup with 4× NVIDIA A100/A800 GPUs (80GB VRAM each) and 500GB SSD storage.
- Software: CUDA 12.1 and cuDNN 8.9.
Step-by-Step Guide:
**Clone the Repository:
git clone https://github.com/StepFunAI/Step-Video-T2V.git
cd Step-Video-T2VInstall Dependencies:
conda create -n stepvideo python=3.10
conda activate stepvideo
pip install torch==2.3.0+cu121 -f https://download.pytorch.org/whl/torch_stable.html
pip install -r requirements.txtDownload Model Weights:
huggingface-cli download StepFun/Step-Video-T2V --include "*.pt" --local-dir models-
Run Inference:
python generate.py --prompt "A futuristic city skyline at dusk" --frames 128 --resolution 768x448Running on Windows
Windows users can explore two primary methods:
Option 1: WSL 2 + NVIDIA CUDA
Setup: Install Windows Subsystem for Linux 2 (WSL 2) and configure NVIDIA CUDA within the Linux environment.
Follow Linux Instructions: After setting up WSL 2, simply follow the Linux installation steps.
Option 2: Docker Container
A Docker container provides an isolated environment:
docker run --gpus all -it stepfun/stepvideo-t2v:latest
python generate.py --prompt "Rainforest waterfall timelapse" --frames 64
This approach simplifies the deployment process and minimizes compatibility issues.
## Running on macOS
For macOS users, particularly those with Apple Silicon (M1/M2 chips), experimental support via MPS is available:
Install PyTorch-Nightly with MPS:
pip install --pre torch torchvision --extra-index-url https://download.pytorch.org/whl/nightly/cpu
- Update the Model Configuration: In the config.yaml file, set:
device: "mps"
mixed_precision: "fp16"
Note that on macOS, the model runs at reduced capacity:
- Maximum resolution: 512×288
- Maximum frames: 32
- Performance: Approximately 0.5 frames per second on an M2 Ultra ## Cross-Platform Integration with AUTOMATIC1111 Web UI For those who prefer a unified interface, integrating Step-Video-T2V into the AUTOMATIC1111 web UI is a viable option:
- Install AUTOMATIC1111 Web UI.
- Add the Step-Video-T2V Extension:
cd stable-diffusion-webui/extensions
git clone https://github.com/StepFun/sd-webui-stepvideo
- Configure the Web UI: Edit the webui-user.bat file to include:
set COMMANDLINE_ARGS=--xformers --precision full --no-half
How Does It Compare With Other AI Models?
Step-Video-T2V stands out when compared to other text-to-video models for several reasons:
Frame Generation Capacity: With a maximum output of 204 frames, it delivers longer and more detailed videos than many competing models.
Innovative Attention Mechanism: Its use of 3D full-attention surpasses the more common 2D approaches, ensuring both spatial and temporal details are meticulously captured.
Multilingual Capabilities: Supporting both English and Chinese, it is far more versatile than models restricted to a single language.
Efficient Compression: The advanced Video-VAE compression technology ensures high-quality outputs with reduced processing overhead.
These features collectively make Step-Video-T2V a leader in the realm of AI video generation, giving creators a powerful tool to bring their visions to life with unmatched clarity and dynamism.
Why This Model Matters
Step-Video-T2V isn’t just a technological marvel—it’s a transformative tool for creative expression. By converting simple text prompts into immersive video experiences, it democratizes video production. Whether you’re a filmmaker, digital artist, or content creator, the model’s ability to faithfully render your ideas can break down traditional barriers and open up exciting new avenues for storytelling.
Embracing the Future with Anakin AI
Imagine having all these advanced AI models like Runway ML, Minimax, Luma AI, and Pyramid Flow at your fingertips, not as isolated tools, but integrated seamlessly into one comprehensive platform. Anakin AI is that platform. It’s an all-in-one solution where you can harness every leading AI model to create your own AI-powered applications. Whether it’s generating breathtaking videos with models like Step-Video-T2V, designing engaging images, converting text to audio, or simply experimenting with diverse AI technologies, Anakin AI is your one-stop hub for it all.
The city will be for Anakin AI—a vibrant ecosystem where every AI tool works together to empower your creativity. With Anakin AI, you’re not just limited to a single functionality. Instead, you enjoy an integrated experience where video, text, audio, and image generation converge to deliver unmatched creative power.
Wrapping It All Up
Step-Video-T2V is more than just an AI model—it’s a leap into the future of content creation. Its deep learning architecture, innovative compression, and bilingual capabilities make it a standout choice for anyone interested in pushing the boundaries of what AI can do. Whether you deploy it on Linux, explore Windows through WSL or Docker, or even test the waters on macOS, you’ll experience a level of performance and creativity that redefines the standard for text-to-video generation.
Take the Leap Today!
If you’re ready to explore the limitless possibilities of AI-powered video generation and more, it’s time to make the smart move. Anakin AI is the ultimate platform where you can integrate every leading AI model under one roof. From generating stunning videos with Step-Video-T2V to creating captivating images, texts, and audio, Anakin AI offers the complete toolkit for every creative mind.
Step into the future with Anakin AI, and watch as your creative ideas transform into vivid, immersive experiences. Embrace a platform that not only meets your needs but also sets the pace for tomorrow’s innovations. Discover, create, and innovate like never before—because your next big breakthrough is just a click away.
In conclusion, Step-Video-T2V is a groundbreaking text-to-video model that redefines what’s possible with AI. Its combination of massive-scale training, cutting-edge technical features, and versatile deployment options makes it a leader in its field. When paired with the comprehensive capabilities of Anakin AI, you gain access to a world of creative possibilities—all within one seamless platform. Don’t wait any longer; join the revolution in AI-powered content creation and let your imagination soar.
Ready to unlock the full potential of AI? Explore Anakin AI now and transform the way you create—because with Anakin AI, the future of content is in your hands!

Top comments (0)