Let’s move things out of theories and designs and check what actually these constructs can perform. So. I chose one database from each category to test out some standard and complex queries. Test databases are as follow:
- Neo4j -> Graph
- PostgreSQL -> SQL
- Apache Cassandra - > NoSQL
Licensing:
All of them are flagship products of their own categories. PostgreSQL and Cassandra are fully open-source. Neo4j is open-core and floats a free community edition.
Schema:
- Neo4j is schema-less but it is better to define labels to group nodes for faster speed.
- Cassandra is NoSQL but requires a schema up-front.
- PostgreSQL also requires a schema.
Data/Key Partitioning:
- Neo4j doesn't support data partitioning, but labels provide nodes grouping for faster operations. Neo4j only supports Vertical Scaling with Read-Replica support.
- PostgreSQL doesn’t have any data partitioning mechanism, so vertical scaling with read-replicas support only.
- Cassandra splits data based on primary or composite key across clusters. So, both horizontal and vertical scaling is available.
Benchmark:
Test Setup: T3.Small, 2 vCPUs, 2 GB RAM, 10 GB EBS General Purpose SSD
Test Instances: One instance for each DB Engine
Test Dataset: 65.2 MB (Personality 2018)
Results:

This result includes combined time for import of both files in the respective databases. Cassandra took a lot of time. Good amount of searching concluded that there is another open-source tool available for bulk-loading CSVs in Cassandra. I used built-in mechanisms for benchmarking purposes only.
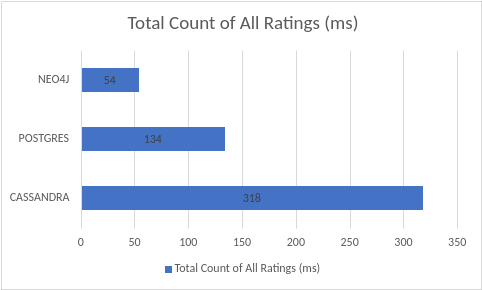
This result contains total time to it took for all of three to count all of the available ratings. Neo4j did an exceptional job snice the traversal was only within “RATINGS” label. Postgres did great also since the traversal was within “Ratings” table only. Cassandra had to open-up each range-key for the traversal that slowed it down a bit.
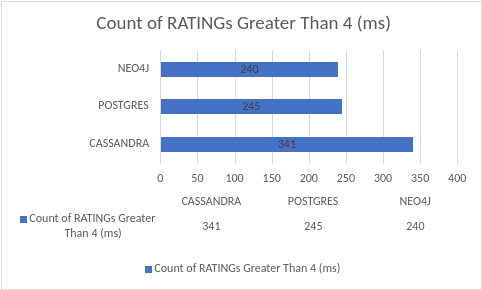
This result explores all of the ratings greater than “4”. Postgres and Neo4j yielded similar results based on contained traversal. Cassandra cached up quite well because of distributed aggregated functions processing.

This traversal includes one table access with a foreign key match at one instance only for a user in Postgres “ratings” table. For Cassandra, it was just a composite key match. Neo4j didn’t perform well, due to the traversal of nodes and relationships for the first time. The same subsequent request yielded scores even lower than PostgreSQL. Neo4j is highly memory-centric and utilizes it well.

This involves access pattern just like above example, but with a more aggressive stats function. Return times are quite similar based on prediction.
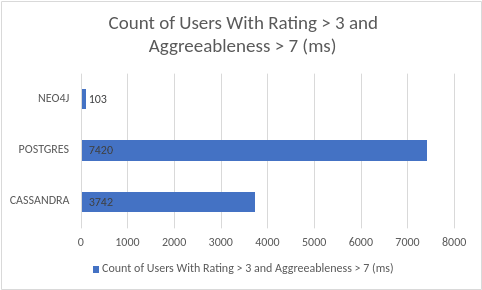
This is a complex query with complex access patterns. This is two table accesssses for PostgreSQL. It has to collect the number of users with ratings greater than 3 in the “Ratings” table and agreeableness > 7 in the “Users” table. It has to perform a join operation, hence taking more time for a complex query. For Cassandra, it was two sort keys lookup and then collect users with rating > 3 and agreeableness > 7 within the same table. Hence, relatively faster results than any SQL database. Neo4j performed marvelously due to its pre-embedding of nodes and relationships. Although, it involves scanning two set of labels, “PERSON” and “RATINGS”, the traversal or jumps between these two nodes is pre-embedded by a relationship between then. This relationship embedding not only allows faster complex queries but offers much more complex operations that no other DB could even perform.
Other Capabilities:
- Cassandra is a columnar database that distributes its keys among shards to achieve horizontal scaling. So, up till a point, where your table has millions of rows, your SQL solutions can work, but after that you would see degraded query performance. Cassandra is for Big Data which distributes data horizontally and also supports a huge amount of column numbers.
- Neo4j is built with a graph visualization browser tool that helps in the deep analysis of your loaded data. Apart from that, Neo4j also contains rich library for AI-based graph analysis that further helps in digging deeper into the data for analysis purposes.Neo4j also keeps a subset of warm data in memory for faster access.

Top comments (0)