
Welcome to the R.A.G, a guide about Amazon's Redshift Database written for the Analyst's out there in the world who use it.
So what is it?
takes a deep breath
It's a Cloud Managed OLAP MPP Columnar SQL Relational Petabyte-scale Data warehouse.

lets break that down.
▪️ Cloud Managed ☁️ (as opposed to on prem)
As Redshift is an Amazon product it should come as no surprise that it is hosted on AWS. This is where the 'Cloud Managed' part comes into place. You can't setup your own server in the backroom and 'install' Redshift on it. Redshift exists only within the AWS platform and for the end user that's a good thing. As it's a managed service AWS takes care of the servers, backups, infrastructure maintenance, upgrades and so much more. It's also built to connect to all the other AWS services seamlessly, things like Kinesis, S3, Glue all work with Redshift with very little setup needed.
▪️ OLAP (as opposed to OLTP)
To understand OLAP, I find it best to explain OLTP first.
An OLTP, or Online Transaction Processing, is a system tuned to do reading, writing, updating and deleting of single records as fast as possible.
Let’s look at Facebook. They have about two billion user accounts. If you’ve done any analytics before you know that to query a table with 2 billion rows takes minutes at the very least. However when you log into Facebook it searches that entire database makes sure your user name and password match and lets you in all within a few milliseconds.
Now what Facebook is actually doing in their back end is far more complicated than that, however, it works as an apt example of an OLTP process at work. OLTP excels at doing one thing at a time very very fast. Which is why we refer to it as transactional processing.
A lot of time and care is taken to build tables and data structures that can be read and updated as fast as possible.
What this often results in are tables that aren't very human readable. For example what you think should be one table is in fact four, and instead of any readable information it might be a series of numbers, for example User: 5895352 did action: 94833 on object: 482141. Databases process numbers faster than strings of characters and things can be sped up by using hierarchies i.e. 'where actionid > 1000'.
Some OLTP databases don't even retain a history of changes as this keeps the database lean.
So to recap, an OLTP database, is built to do single transactions as fast as possible, achieved by doing whatever it can to transact as fast as possible.
Then lets throw in the fact that OLTP databases are, more often than not, production databases connected to live websites / apps where anything that could slow down the database i.e. a complex query, could slow down the app/website.
Do you start to get an inkling as to why an OLTP system might not be fit to crunch big data datasets?
Enter the Online Analytical Processing (OLAP) way of doing things. An OLAP is built to be searched. It's built to have a boat-load of data stored within it and for users to slice, join, and dice to their hearts content over sometimes billions of rows of data.
The subtleties in how it stores and handles data give it that edge when you want to run complex queries. However transactional activities like inserting, updating and deleting take much longer in an OLAP enviroment.
It will never beat an OLTP system in retrieving a single record of information however an OLTP system won't beat an OLAP in joining a two billion row table to a five billion row table and grouping by the first five columns while calculating the median on the sixth.
| OLTP | OLAP |
|---|---|
 |
 |
▪️ MPP (as opposed to SMP)
Redshift does massively parallel processing (MPP) which means spreads its storage and computational power across multiple nodes. To put it simply, each node is it's own computer with its own a processor and a hard drive. For example one table of data could be spread across eight nodes so when a query is executed against that table, each processor (node) only has to look at 1/8th the data.
If you can afford it, you can have up to 128 nodes...
The benefits here are clear, it's like sharing out a project at work amongst your team. More people can mean that more tasks can be completed in parallel.
This is in comparison to Symmetric Multiprocessing (SMP) databases like Oracle. SMP's can have multiple processors, however it's all in one place and all the other resources like storage are shared. Some processes won't be able to benefit from the existence of multiple processors, or other parts of the SMP will bottleneck the work regardless of the multiple processors. To use the team metaphor again, sometimes there are too many cooks in the kitchen, eight people won't write a single word document faster than one person.
However it's not always a clear win for MPP. SMP's tend to be a lot cheaper and easier to clean up if something goes wrong. MPP's, just like a team of people, need to be carefully managed in order to get the blazing fast speeds it promises over SMP. If you don't build your data structures right then it can result in your nodes working harder and taking longer. More on that in a later article.
| MPP | SMP |
|---|---|
 |
 |
▪️ Columnar (as opposed to row-store)
Databases can chose to store their tables in row store or column store.
In a row store, a row is considered a single block of data, this has its benefits when writing and updating rows but if you are querying that row and you only want one column you pay the performance cost for the entire row.
This also has the downside of wasting a lot of space in the database. Rows are considered a holistic entity, if one column contains a lot of data it impacts the entire row, which happens with JSON, CLOB and BLOB data types.
OLTP databases tend to run on row stores.
On the other hand a column store makes every column in the row its own object, as well as considering the whole row itself an object.
Column store is immensely more performant as if you just need one column you can do so without paying the price of the whole row.
It also stores all the cells of each column differently per column often storing all the similar values together, further increasing performance.
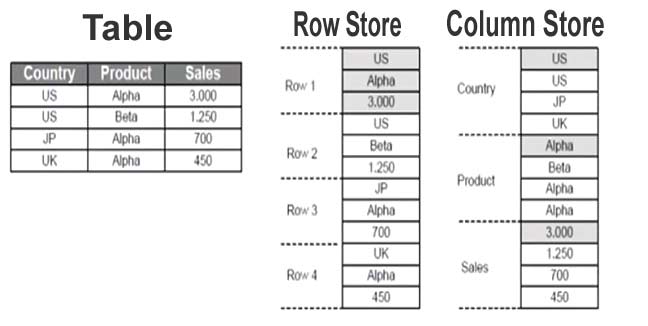
Because it's storing all the column cells individually, it has to track that, and does so using a metadata table in the background. Through the use of zone-maps, something we'll discuss in a later article, column store and the metadata table speeds up queries that use predicates (conditions), for example if your query is looking for records dated after '2018-01-01' then the metadata table knows what column cells fall into that range without needing to look at the data.
However all these benefits to storing your data in columns doesn't come for free. It takes longer to update, insert, delete, and re-sort these data types and as such are only beneficial on datasets that aren't updated at a high frequency
▪️ SQL Relational (as opposed to NoSQl)
Redshift is a Relational database which uses SQL as the primary mechanic for querying its data.
At its core a relational database means you store data in a consistent structure of tables and that your data carries unique identifiers that allow you to relate records across tables.
Non-relational databases, or as their commonly referred to, NoSQL (which stands for not-only-SQL) databases hold things like API calls, documents, or blog posts. They tend to be structured in a way that suits the specific needs of the data / don't work to be stored in tables, i.e documents, and often duplicate and nest data for performance reasons. Often the way they are structured does not allow for joins during queries and other coding languages can be used to find data.
As Redshift is built as a data warehouse for the purpose for crunching large scale analytics it needs to be relational database.
📚 Learn more
Article No Longer Available
▪️ Petabyte-scale (as opposed to Terabyte Scale)
While the smallest configuration of Redshift possible is two terabytes, Redshift can go all the way to two petabytes. For those wanting to run a small data warehouse or a small pure OLAP database on AWS you really should look towards Amazon Aurora. Redshift really doesn't shine until your dealing with tables over ten million rows, so if your tables, are on average smaller than that, Redshift isn't for you.
📚 Learn more
Article No Longer Available
Part Two
Article No Longer Available
header image drawn by me
Who am I?


 Ronsoak 🏳️🌈🇳🇿@ronsoak
Ronsoak 🏳️🌈🇳🇿@ronsoak Who Am I❓
Who Am I❓
|🇳🇿 |🇬🇧 |🏳️🌈
📊 Senior Data Analyst for @Xero
⚠️ My words do not represent my company.
✍️ Writer on @ThePracticalDev (dev.to/ronsoak)
✍️ Writer on @Medium (medium.com/@ronsoak)
🎨 I draw (instagram.com/ronsoak_art/)
🛰️ I ❤️ space!03:11 AM - 13 Oct 2019



Top comments (2)
Without a doubt the best visual explanation of OLTP vs OLAP I've ever seen :)
Thank you !!