
From OpenAI docs
Fine-tuning lets you get more out of the models available through the API by providing:
- Higher quality results than prompting
- Ability to train on more examples than can fit in a prompt
- Token savings due to shorter prompts
- Lower latency requests
In this post, we will look at how to build an assistant with and without fine-tuning in this experiment and compare the results.
Code
https://github.com/amalshaji/finetune-gpt
Use-case
Let's build an assistant capable of generating template messages for engaging with our users. The assistant will generate messages based on the required tone and use pre-defined template tags wherever necessary.
e.g.:
Happy Birthday {{ first_name }}! We're thrilled to celebrate this special day with you. As a valued customer, your happiness is our top priority. Enjoy this day to the fullest, and here's to another year of great experiences with us. Cheers to you on your birthday!
Assume the following tags are valid: first_name, email, last_name
Without fine-tuning
Generate a message in less than 50 words using the following parameters:
occasion: {occasion}
tone: {tone}
Use the following template tags as placeholders wherever necessary
| tags | description |
|---|---|
| {{ first_name }} | User's first name |
| {{ last_name }} | User's last name |
| {{ email }} | User's email |
The program will set the occasion and tone before passing to the OpenAI endpoint.
import asyncio
import openai
import os
from string import Template
openai.api_key = os.getenv("OPENAI_API_KEY")
prompt = Template(
"""
Generate a message in less than 50 words using the following parameters:
occasion: $occasion
tone: $tone
Use the following template tags as placeholders wherever necessary
| tags | description |
|---|---|
| {{ first_name }} | User's first name |
| {{ last_name }} | User's last name |
| {{ email }} | User's email |
"""
)
async def run(occasion: str, tone: str):
response = await openai.ChatCompletion.acreate(
model="gpt-3.5-turbo",
messages=[
{
"role": "system",
"content": prompt.substitute({"occasion": occasion, "tone": tone}),
}
],
)
print(response)
asyncio.run(run(occasion="birthday", tone="texas accent"))
- The prompt is set to generate a birthday message in a Texas accent
- Chat completion API used for accessing the gpt3.5 model
- Using
gpt-3.5as fine-tuning does not support the gpt-4 model
Output
{
"id": "chatcmpl-817dhqQoNvTmBHlDMKDkiQIYezgRn",
"object": "chat.completion",
"created": 1695278385,
"model": "gpt-3.5-turbo-0613",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Happy birthday, {{ first_name }}! Hope y'all have a rootin' tootin' day filled with joy and good ol' Texas charm. Yeehaw! \ud83e\udd20"
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 99,
"completion_tokens": 39,
"total_tokens": 138
}
}
- Time to complete: ~3s
- Total cost for this execution: (99/1000 x 0.0015 + 39/1000x0.002) = $0.0002265.
Fine-tuning
Preparing the dataset
OpenAI fine-tuning requires a dataset of at least ten examples to work. It accepts the input as a jsonl (json lines) file, where each line is a valid json. e.g.:
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."},{"role": "user", "content": "What's the largest planet in our solar system?"},{"role": "assistant", "content": "Jupiter, but don't worry, it's not like it's taking up half the solar system or anything."}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."},{"role": "user", "content": "Who discovered penicillin?"},{"role": "assistant", "content": "Alexander Fleming. But don't get too excited; it's just one of the most important discoveries in medical history."}]}
Here is the training data we will use to fine-tune our model.
Create a new file
async def create_training_file():
file_create_output = await openai.File.acreate(
file=open("data.jsonl", "rb"), purpose="fine-tune"
)
print(f"Created training file: {file_create_output}")
return file_create_output
The response should contain the file id and status. If the status is not processed, keep checking the status manually await openai.File.aretrieve(file_id)
Fine-tune
We can schedule a fine-tuning job with OpenAI using the uploaded file ID.
async def start_finetune_job(training_file: str):
ft_job = await openai.FineTuningJob.acreate(
training_file=training_file, model="gpt-3.5-turbo"
)
print(f"Created fine tuning job: {ft_job}")
return ft_job
Navigate to https://platform.openai.com/finetune to see the job status. Once complete, you'll see the relevant metrics, including the tokens used for training.
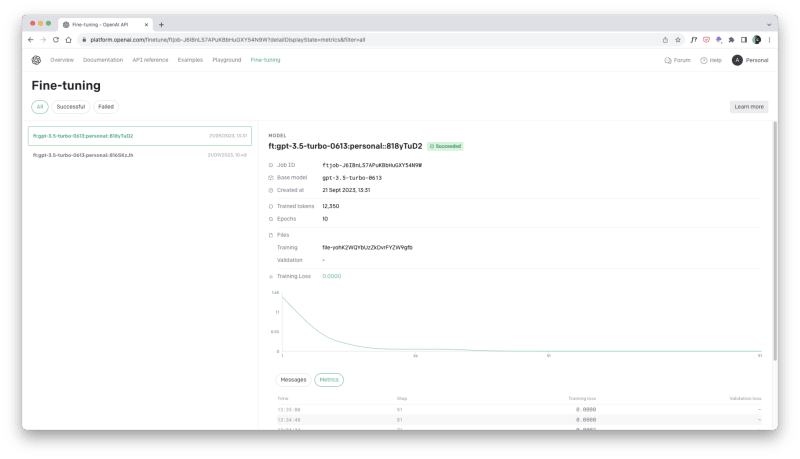
- Tokens used for training: 12,350
- Total cost: (12350 / 1000 x 0.0080) = $0.0988.
Working with the new model
We run something similar to the non-fine-tuned version, replacing the model with our custom model.
async def run(occasion: str, tone: str):
start = timeit.default_timer()
response = await openai.ChatCompletion.acreate(
model="ft:gpt-3.5-turbo-0613:personal::819PHd1U",
messages=[
{
"role": "system",
"content": prompt,
},
{
"role": "user",
"content": f"occasion: {occasion}, tone: {tone}",
},
],
)
print(response)
print(f"Time taken: {timeit.default_timer() - start}s")
asyncio.run(run(occasion="birthday", tone="informal"))
imports and other stuff are the same as the non-fine-tuned version
{
"id": "chatcmpl-81AzImR0c0f9h3Kud3sHeHo8rmRyl",
"object": "chat.completion",
"created": 1695291256,
"model": "ft:gpt-3.5-turbo-0613:personal::819PHd1U",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Happy birthday, {{ first_name }}! Hope your special day is filled with lots of cake, presents, and non-stop fun."
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 96,
"completion_tokens": 26,
"total_tokens": 122
}
}
There's a slight reduction in the number of tokens, and the total cost is around $0.000196.
Comparison
| non fine-tuned | fine-tuned | |
|---|---|---|
| Cost | If you need to pass examples in the system commands, it will incur a higher cost | cheaper, as the model can be fine-tuned on the examples |
| Availability | Always available | After training, the API raised a lot of server overload exceptions before giving the correct response. |
| The inference speed | is slow; on average, it takes ~3 seconds | faster, and most queries are finished in less than a second. Some outliers took more than 10 seconds. |
| Ease of use | Straightforward, write prompt and query | Prepare training and validation data, create files, start training, and wait for training to finish (Obviously, you can automate all these). |
| Limitations | No known limitations (Using this as the base for comparison) | gpt-4, function calling not available (later this year) |
Conclusion
In this experiment, we improved the output of our prompt by fine-tuning gpt-3.5 on a small dataset. You must pass examples with each prompt in the non-fine-tuned version to achieve the same. Imagine the cost of doing this for 100,000-1,000,000 API calls. Although this experiment did not show any difference in results(as the task was easy for gpt), a complex task would've benefited from fine-tuning.
Fine-tuning GPT-3 models can significantly improve their performance on complex tasks, making them ideal for building low-cost, highly efficient assistants. While the process of fine-tuning requires some additional effort, the benefits in terms of cost and speed make it a worthwhile investment. As support for GPT-4 and function call is added, the potential applications of fine-tuned models will only continue to expand. However, it's essential to carefully consider whether fine-tuning is the right approach for your specific use case. By researching and weighing the pros and cons, you can decide whether fine-tuning is the best way to achieve your goals.

Top comments (0)