In this post, I'll talk about how a bot tweets translations of Urdu words to English.
TL; DR:
1. Use the JSON data returned freely by the well-documented Oxford Dictionaries API.
2. Tweet like @_alfaaz_1
Why this bot
How the bot works
- How the Oxford Dictionaries API works
- The difficulties in using the API
- The workarounds
- How do the tweets happen
Where's the code
Why this bot, again
Why this bot
I know Urdu. At least, I think I know Urdu, chiefly because I know the lyrics of practically every popular Hindi film song ever made. But film songs are ... poems, and there's this thing called poetic license, and then, not all words always mean what I might think they mean.
And I am not alone. Dozens of people around me, growing up following the major religion in India (which is 'Films') know and quote lyrics off the cuff, but don't always know the exact meaning of certain words. For example, I (and hundreds of others) went through teenage and the rest of our lives thinking jigar means heart. It doesn't. Nope.
So, when I chanced upon the Oxford Dictionaries API, which includes an Urdu dictionaries endpoint, I thought, "Why not make a tweet bot?"
How the bot works
It picks a Urdu words one by one from a list I give it, supplies those words to the Oxford Dictionary API endpoint, gets the JSON responses, parses the responses to pick the translations, and tweets the Urdu words and their English translations.
Its requirements are as follows:
- A computer connected to the internet
- A token, token secret, consumer key, and consumer secret from Twitter
- An app ID and app key from Oxford Dictionaries
- A scripting environment to write and run the bot code in
How the Oxford Dictionaries API works
It serves a JSON response through REST endpoints that are well-documented2.
The actual translations of a word are contained in a list of dictionary objects; the list is called results.
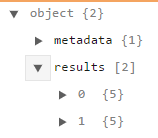
Each dictionary object in this results list has a key called lexicalEntries. If you drill down from there, you finally arrive at a list called translations where a dictionary key called text contains the actual translation. The following image shows the complete sequence, with the translation highlighted in a red box :

A word can have several meanings and, therefore, several translations. How would one know how many meanings exist? Well, one looks at the number of items in the senses list for every dictionary object in the results list. Here's the hierarchy of senses:
['results'] > ['lexicalEntries'] > ['entries'] > ['senses']
The difficulties in using this API
The script. The difficulty is the script.
Urdu, as spoken in its daily form in India, is indistinguishable from Hindi. Urdu, when written, is written in a script called Nastaliq. I don't know how to read Nastaliq3. The Oxford Dictionaries API takes input only in the Nastaliq script. Uh oh!
The workarounds
- Learn how to read Nastaliq.[But] Yeah, right, on top of everything else. It's because I don't know that script that I've been unable to look up a dictionary thus far but, surely, in this day and age of OneWorld, there is an easier way? After all, I can make out the letters with huge effort, surely that's sufficient?
- Use a transliteration service.[But] I searched, but found nothing. The GoogleTransliterate API has been deprecated. Python (the language I can code in) has a
polyglotlibrary but it refused topipinstall on my machine. I did not find a single resource that could take in a word written in Devanagari and give out that word in Nastaliq programmatically. - Extract the Urdu word from one of the online dictionary resources that contain both the Urdu word and its transliterated English form, like the Platt's dictionary4 does: جگر jigar.[But] None of these web resources are in any structured format such as XML or JSON. Not one.
- Build my own transliterator.[But] Heh, like I can even write two lines of code without looking up a textbook... But wait. I found a Nastaliq-to-Roman mapping table on Medium5. Maybe I could do something similar for tweeting, I thought, and parked away this idea for later. But this doesn't help me get spelling-perfect transliterations that a language dictionary can recognise.
- Use a readymade word-list.[But]Oxford Dictionaries supplies ready-made wordlists for English. But not for Urdu.
Because none of these workarounds were feasible, I had to generate a word-list manually. I used Platt's dictionary to make my word-list. I would type the Urdu word in Roman script, and copy the Nastalikh version of it in my word-list.
How do the tweets happen
- The bot uses tokens to authenticate itself with Twitter and with Oxford Dictionaries.
- It picks a word from the word list and gets the translations from Oxford Dictionaries.
- It puts the translations on to a tweetable image, together with all of the letters in that word broken up and mapped to their Devanagari counterparts (see #4 under Workarounds). It then tweets this image.
- [Enhancement, added later] It picks up the Devanagari version of the word (present in the same word-list), gets the Hindi meanings from Oxford Dictionaries, and tweets these meanings.
- It also feeds the word to Platt's dictionary, gets the URL of the search result, and tweets that URL.
- It then sleeps for an hour, and repeats steps 2 through 5 for as many times as there are words in the word-list.
Where's the code
Why, on GitHub of course. Where else?
Why this bot again?
Because other resources - bot tweets, emailed WOTDs, non-bot tweets - are either boring or overwhelming. The design goals for this bot were:
- do not overwhelm the noob
- tie a word to a fun context that every noob follower will likely know.
So, that was the story about my first tweet bot. What do you think?
Note 1.
alfaaz is an Urdu word that means 'words'. (Urdu has a different word for the singular word 'word'; it is lafz.)
Note 2.
Oxford Dictionaries API documentation
Note 3.
In its spoken form, Urdu is practically indistinguishable from Hindi. However, for writing, the two languages use different scripts. Hindi uses Devanagari; Urdu uses Nastaliq. The sentences in each language would be exactly the same, but written in two totally different writing styles, whose major differences are these:
- Nastaliq is written right-to-left; Devanagari, left-to-right.
- Nastaliq often does not use vowel markers; Devanagari is invariably phonetic and always with vowel markers.
Note 4.
John Platt's Dictionary of Urdu, Classical Hindi, and English
Note 5.
Transliterate Urdu to Roman Urdu In Python

Top comments (0)