Did you land here searching for a way to reduce MTTR as a DevOps/SRE or reliability engineer? If yes, then you are in the right place. If not, you should still read on if you care about the reliability of the system you are building.

MTTR - or Mean Time To Resolve is a widely used metric in the realm of systems reliability. However, people tend to interpret MTTR differently. A temporary patch to get systems up and running may be considered a resolution in some teams, even if the root cause requires a more long-term fix. Regardless of its different definitions, MTTR is a crucial metric because its a measure of operational resilience and is closely linked to your uptime. And most importantly, there is a universal need to keep this number down as it has a direct impact on revenue and customer happiness.
A recent study conducted by devops.com tries to measure the impact of downtime and the numbers are quite staggering
- For the Fortune 1000, the average total cost of unplanned application downtime per year is $1.25 billion to $2.5 billion.
- The average hourly cost of an infrastructure failure is $100,000 per hour.
- The average cost of a critical application failure per hour is $500,000 to $1 million.
It stands to reason, then, that engineering teams should strive to decrease their overall MTTR. But one of the biggest challenges that DevOps and IT teams face today is the inability to quickly take obvious mitigation actions when an incident has been detected - this, in turn, leads to increased TTR.
The time taken to detect a problem or an incident depends on:
- A variety of logs, monitoring tools and other solutions in place
- The efficacy, and accessibility of these tools and
- Dependencies on other teams and systems.
Once an incident is detected, taking the right actions automatically and immediately is the easiest step to make a sustainable and measurable improvement to your MTTR.
Now this means not just alerting the right responder on time, but also triggering certain scripts and failsafes based on incident severity and context to minimize end-user impact.
So, we thought - what if you could get push notification alerts for events, and you can just swipe those notifications to acknowledge and take basic mitigation actions. You don't need to get to your laptop, or run stuff on the terminal, or log in to a bunch of other tools like CI/CD, Infra automation or Testing platforms. Sounds intriguing? Check out how it works.
Introducing Squadcast Actions
Often, despite the DevOps/SRE/on-call team being alerted immediately about a major incident, and despite them knowing in a matter of seconds what actions need to be taken to minimize end-user impact, it still takes a few minutes and sometimes hours to recover due to human factors. This is especially true if the SRE/on-call engineer is outside work hours, or away from their computer.
Needless to say, actual incident resolution can take many hours or even days depending on the triage time, access to key data/information, cooperation from other colleagues. But in cases like this, a quick recovery to a state where the end-user impact is inconsequential should be the only acceptable behavior. Empowering on-call teams to quickly take obvious and necessary actions can save the day (and most importantly, avoid those dreadful 3 AM calls!)
This is why we built Squadcast Actions - a convenient and practical way to respond to incidents on time. At Squadcast, we obsess about improving the on-call experience and reducing the inherent stress of dealing with incidents.
Squadcast Actions allow you to take actions directly from within the platform. You can take quick actions such as
- Acknowledging or resolving an incident
- Rebuilding a project
- Rebooting a server
- Rolling back a feature
- Running custom scripts and much more
All this with just a tap, thus making it easy to do tasks that are otherwise manual and repetitive. Or in other words - Reducing toil for your team.
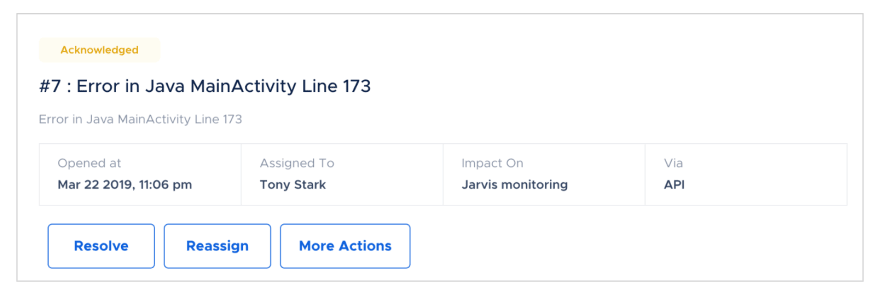
For instance, one of the actions that you can take is *"Rebuilding CircleCI" *projects directly from the incident page by clicking on the More actions button. (Note that in order do this, CircleCI Integration with Squadcast must be first completed)

You can also see the actions performed listed in chronological order as part of the Incident timeline. The incident timeline is intended to serve as your single source of truth of who did what and when, while the incident was live.

Incident response on the go - Squadcast Actions on Mobile

The best part about taking actions is doing it on the go - be it while you are enjoying a scrumptious meal with your colleagues at lunch or during your tiring commute to and fro from work.Our fully functional native apps on both Android and iOS platforms make it easy to respond to critical incidents with pre-defined actions.
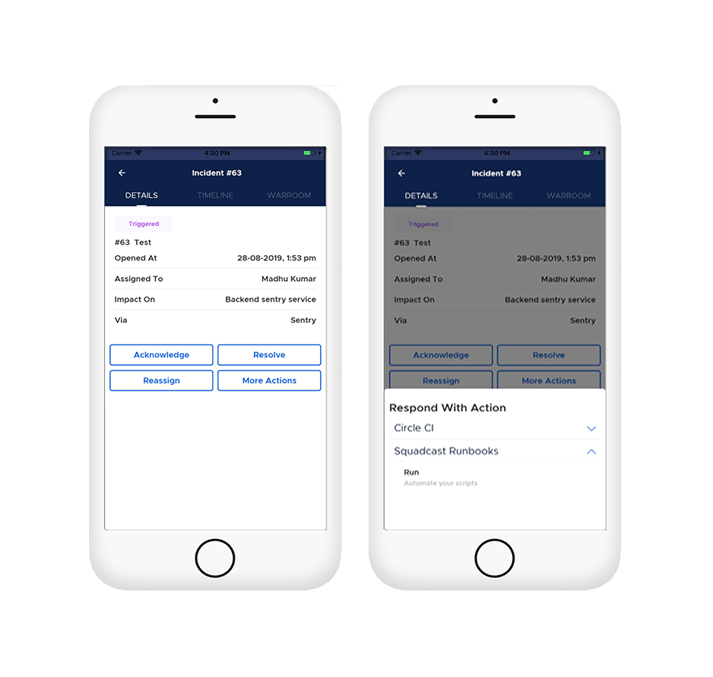
Here's a quick sneak peek
Effective incident management not only requires sending the right information to the right on-call responders but also enabling your team with the right tools to act swiftly. Combining Squadcast with an existing incident management workflow allows DevOps/SRE professionals to efficiently track, analyze and resolve incidents.
Enjoyed this? If you have come this far then you should definitely check out some cool new features that we are currently working on, available on our product road map.
We love your comments. What do you struggle with as a DevOps/SRE? Do you have ideas on how incident response could be done better in your organization?
We would love to hear from you! Leave us a comment or reach out over a DM via Twitter and let us know your thoughts.

Learn more about Squadcast

Top comments (0)