
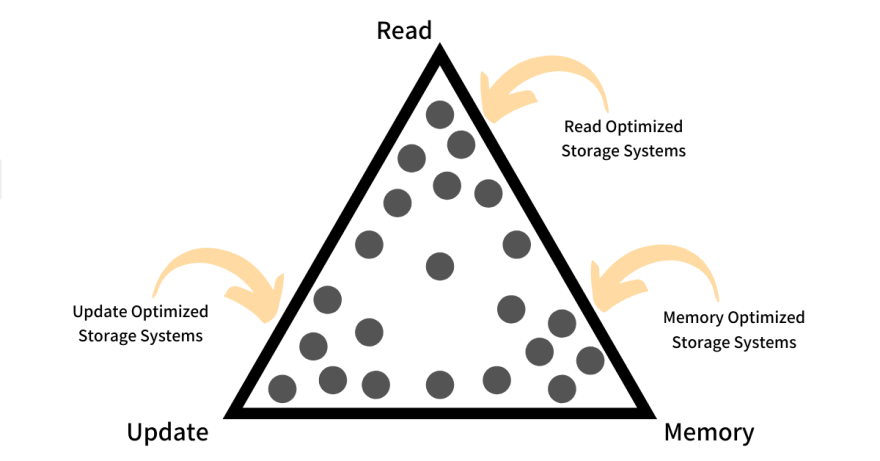
The RUM Conjecture states that we cannot design an access method for a storage system that is optimal in all the following three aspects - Reads, Updates, and, Memory. The conjecture puts forth that we always have to trade one to make the other two optimal and this makes the three constitutes a competing triangle, very similar to the famous CAP theorem.
Access Method
Data access refers to an ability to access and retrieve data stored within a storage system driven by an optional storage engine. Usually, a storage system is designed to be optimal for serving a niche use case and achieve that by carefully and judiciously deciding the memory and disk storage requirements, defining well-structured access and retrieval pattern, designing data structures for primary and auxiliary data and picking additional techniques like compression, encryption, etc. These decisions define, and to some extent restricts, the possible ways the storage engine can read and update the data in the system.
RUM Overheads
An ideal storage system would be the one that has an access method that provides lowest Read Overhead, minimal Update Cost, and does not require any extra Memory or Storage space, over the main data. In the real-world, achieving this is near impossible and that is something that is dictated by this conjecture.
Read Overhead
Read Overhead occur when the storage engine performs reads on auxiliary data to fetch the required intended main data. This usually happens when we use an auxiliary data structure like a Secondary Index to speed up reads. The reads happening on this auxiliary structure constitutes read overheads.
Read Overhead is measured through Read Amplification and it is defined as the ratio between the total amount of data read (main + auxiliary) and the amount of main data intended to be read.
Update Overhead
Update Overhead occur when the storage engine performs writes on auxiliary data or on some unmodified main data along with intended updates on the main data. A typical example of Update Overheads is the writes that happen on an auxiliary structure like Secondary Index alongside the write happening on intended main data.
Update Overhead is measured through Write Amplification and it is defined as the ratio between the total amount of data written (main + auxiliary) and the amount of main data intended to be updated.
Memory Overhead
Memory overhead occurs when the storage system uses an auxiliary data structure to speed up reads, writes, or to serve common access patterns. This storage is in addition to the storage needs of the main data.
Memory Overhead is measured through Space Amplification and it is defined as the ratio between the space utilized for auxiliary and main data and space utilized by the main data.
The Conjecture
The RUM Conjecture, in a formal way, states that
An access method that can set an upper bound for two out of the read, update, and memory overheads, also sets a lower bound for the third overhead.
This is not a hard rule that is followed and hence it is not a theorem but a conjecture - widely observed but not proven. But we can safely keep this in mind while designing the next big storage system serving a use case.
Categorizing Storage Systems
Now that we have seen RUM overheads and the RUM Conjecture we take a look at examples of Storage Systems that classify into one of the three types.
Read Optimised
Read Optimised storage systems offer very low read overhead but require some extra auxiliary space to gain necessary performance that again comes at a cost of updates required to keep auxiliary data in sync with main data which adds to update overheads. When the updates, on main data, become frequent the performance of a read optimized storage system takes a dip.
A fine example of a read optimized storage system is the one that supports Point Indexes, also called Hash-based indexes, offering constant time access. The systems that provide logarithmic time access, like B-Trees and Skiplists, also fall into this category.
Update Optimised
Update Optimised storage systems offer very low Update Overhead by usually using an auxiliary space holding differential data (delta) and flushing them over main data in a bulk operation. The need of having an auxiliary data to keep track of delta to perform a bulk update adds to Memory Overhead.
A few examples of Update Optimised systems are LSM Trees, Partitioned B Trees, and FD Tree. These structures offer very good performance for an update-heavy system but suffer from an increased read and space overheads. While reading data from LSM Tree, the engine needs to perform read on all the tiers and then perform a conflict resolution, and maintaining tiers of data itself is a huge Space Overhead.
Memory Optimised
Memory Optimised storage systems are designed to minimize auxiliary memory required for access and updates on the main data. To be memory-optimized the systems usually use compress the main data and auxiliary storages, or allow some error rate, like false positives.
A few examples of Memory Optimises systems are lossy index structures like Bloom Filters, Count-min sketches, Lossy encodings, and Sparse Indexes. Keeping either main or auxiliary data compressed, to be memory efficient, the system takes a toll on writes and reads as they now have additionally performed compression and decompressions adding to the Update and Read overheads.
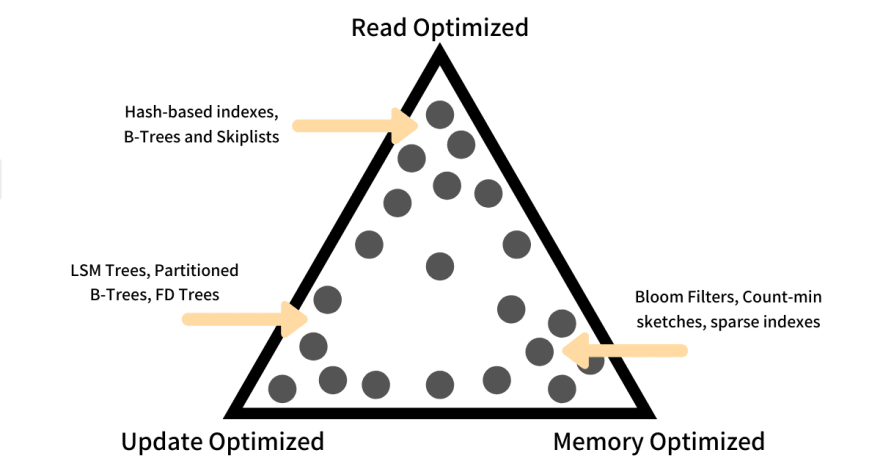
Storage System examples for RUM Conjecture
Block-based Clustered Indexing
Block-based Clustered Indexing, sits comfortably between these three optimized systems types. It is not read Read efficient but also efficient on Updates and Memory. It builds a very short tree for its auxiliary data, by storing a few pointers to pages and since the data is clustered i.e. the main data itself is stored in the index, the system does not go to fetch the main data from the main storage and hence provides a minimal Read overhead.
Being RUM Adaptive
Storage systems have always been rigid with respect to the kind of use cases it aims to solve. the application, the workload, and the hardware should dictate how we access our data, and not the constraints of our systems. Storage systems could be designed to be RUM Adaptive and they should possess an ability to be tuned to reduce the RUM overheads depending on the data access pattern and computation knowledge. RUM Adaptive storage systems are part of the discussion for some other day.
Conclusion
There will always be trade-offs, between Read, Update, and Memory, while either choosing one storage system over others; the RUM conjecture facilitates and to some extent formalizes the entire process. Although this is just a conjecture, it still helps us disambiguate and make an informed, better and viable decision that will go a long way.
This essay was heavily based on the original research paper introducing The RUM Conjecture.
References
Other articles that you might like
- Copy-on-Write Semantics
- What makes MySQL LRU cache scan resistant
- Isolation Forest algorithm for anomaly detection
- Everything that you need to know about Image Steganography
If you liked what you read, consider subscribing to my weekly newsletter at arpit.substack.com were, once a week, I write an essay about programming languages internals, or a deep dive on some super-clever algorithm, or just a few tips on building highly scalable distributed systems.
You can always find me browsing through twitter @arpit_bhayani.

Top comments (0)