
Background
In September 2019, AWS announced the general availability of QLDB, a fully managed centralised ledger database. At the heart of QLDB is its append-only journal. All requests go through the journal first, and it only contains committed transactions. This data is immutable, and creates a complete audit trail of every single change ever made - essential in a digital world that needs trust in the data, and must meet regulatory compliance.
The challenge was how to support use cases such as analytics and downstream event processing, or tasks better supported by other purpose built database, whilst retaining QLDB as the source of truth. This has been answered with the recent release of real-time streaming for Amazon QLDB. This is a major new feature for QLDB, so let's jump in and take a closer look.
QLDB Streams
QLDB Streams is a feature that allows changes made to the journal to be continuously written in near real time to a destination Kinesis Data Stream. Consumers can subscribe to the stream, and take appropriate action. There are a number of advantages of this approach:
- QLDB Streams provides a continuous flow of data from a specified ledger in near real time
- QLDB Streams provides an at-least-once delivery guarantee
- Multiple streams can be created with different start/end dates and times. This provides the ability to go back and replay all document revisions from a specific point in time.
- Up to 20 consumers (soft limit) can be configured to consume data from a Kinesis Data Stream
The best way to learn about QLDB streams is to try them out for yourself. We built a demo application in Nodejs that is available on GitHub - QLDB Simple Demo.
The entirely serverless architecture of the demo is shown in the diagram below:
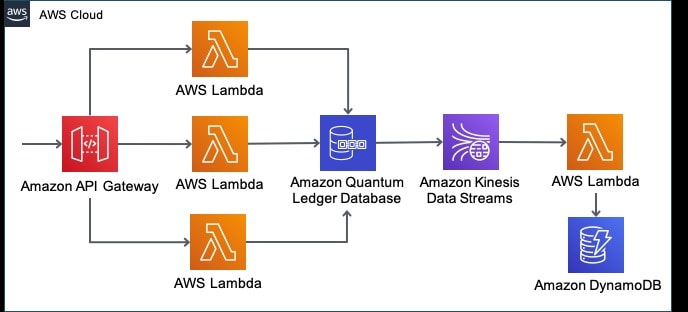
One stack builds out the backend exposing APIs through AWS API Gateway that invoke AWS Lambda functions that interact with QLDB. A separate stack supports a QLDB stream which includes an AWS Lambda function triggered by Kinesis. This function updates a table in DynamoDB with a subset of the QLDB data, with all personally identifiable information (PII) removed.
QLDB Stream Record Types
There are three different types of records written by QLDB. All of them use a common top-level format consisting of the QLDB Stream ARN, the record type, and the payload:
{
qldbStreamArn: string,
recordType: CONTROL | BLOCK | REVISION_DETAILS,
payload: {
// data
}
}
CONTROL Record
A CONTROL record is the first record written to Kinesis, and the last record written when an end date/time is specified. The payload simply states whether this is the first event 'CREATED' or the last event 'COMPLETED'.
{
controlRecordType:"CREATED/COMPLETED"
}
BLOCK Record
A block summary record represents the details of a block that has been committed to QLDB as part of a transaction. All interaction with QLDB takes place within a transaction. In the demo application, when a new Bicycle Licence is created, there are 3 steps carried out:
- A lookup is made on the table to check the provided email address is unique
- A new licence record is created
- The licence record is updated to include the document ID generated and returned by QLDB in step 2
The resulting BLOCK record for this is shown below:
{
blockAddress: {...},
...
transactionInfo: {
statements: [
{
statement: "SELECT Email FROM BicycleLicence AS b WHERE b.Email = ?\",
startTime: 2020-07-05T09:37:11.253Z,
statementDigest: {{rXJNhQbB4tyQLAqYYCj6Ahcar2D45W3ySfxy1yTVTBY=}}
},
{
statement: "INSERT INTO BicycleLicence ?\",
startTime: 2020-07-05T09:37:11.290Z,
statementDigest: {{DnDQJXtKop/ap9RNk9iIyrJ0zKSFYVciscrxiOZypqk=}}
},
{
statement: "UPDATE BicycleLicence as b SET b.GUID = ?, b.LicenceId = ? WHERE b.Email = ?\",
startTime: 2020-07-05T09:37:11.314Z,
statementDigest: {{xxEkXzdXLX0/jmz+YFoBXZFFpUy1H803ph1OF2Lof0A=}}
}
],
documents: {...}
},
revisionSummaries: [{...}]
}
All of the PartiQL statements executed are included in the BLOCK record, including SELECT statements, as they form part of the same transaction. If multiple tables are used, then statements against all tables carried out in the same transaction will appear in the BLOCK record.
REVISION_DETAILS record
The REVISION_DETAILS record represents a document revision that is committed to the ledger. The payload contains the latest committed view, along with the associated table name and Id. If three tables are updated within one transaction, this will result in one BLOCK record and three REVISION_DETAILS records. An example of one of the records is shown below:
{
tableInfo: {
tableName: "Orders",
tableId: "LY4HO2JU3bX99caTIXJonG"
},
revision: {
blockAddress: {...},
hash: {{hrhsCwsNPzLjCsOBHRtSkMCh2JGrB6q0eOGFswyQBPU=}},
data: {
OrderId: "12345",
Item: "ABC12345",
Quantity: 1
},
metadata: {
id: "3Ax1in3Mt7L0YvVb6XhYyn",
version: 0,
txTime: 2020-07-05T18:22:14.019Z,
txId: "84MQSpihZfxFzpQ4fGyXtX"
}
}
}
Processing Events in AWS Lambda
By default, the QLDB Stream is configured to support record aggregation in Kinesis Data Streams. This allows QLDB to publish multiple stream records in a single Kinesis Data Stream record. This can greatly improve throughput, and improve cost optimisation as pricing for PUTs are by 25KB payload “chunks”, and so we wanted to use this feature.
The demo application makes use of the Nodejs Kinesis Aggregation and Disaggregation Modules. A Kinesis record event consists of an array of Kinesis records in the structure below:
{
Records: [
{
kinesis: {
...
data: '...',
approximateArrivalTimestamp: 1593728523.059
},
...
}
]
};
Inside the handler of the AWS Lambda function, the records passed in are processed one at a time for each element in the array using the map() function. Each record calls out to promiseDeaggregate and then to processRecords.
await Promise.all(
event.Records.map(async (kinesisRecord) => {
const records = await promiseDeaggregate(kinesisRecord.kinesis);
await processRecords(records);
})
);
The promiseDeaggregate function uses the deaggregateSync interface which handles the record aggregation, with each deaggregated record being returned as a resolved Promise.
const promiseDeaggregate = (record) =>
new Promise((resolve, reject) => {
deagg.deaggregateSync(record, computeChecksums, (err, responseObject) => {
if (err) {
//handle/report error
return reject(err);
}
return resolve(responseObject);
});
});
Once returned, the record is then processed. This involves decoding the base64 encoded data. The payload is the actual Ion binary record published by QLDB to the stream. This is loaded into memory using ion-js, and then any relevant processing can take place. In the case of the demo, the only record types processed were REVISION_DETAILS with all others being skipped.
async function processRecords(records) {
await Promise.all(
records.map(async (record) => {
// Kinesis data is base64 encoded so decode here
const payload = Buffer.from(record.data, "base64");
// payload is the actual ion binary record published by QLDB to the stream
const ionRecord = ion.load(payload);
// Only process records where the record type is REVISION_DETAILS
if (JSON.parse(ion.dumpText(ionRecord.recordType)) !== REVISION_DETAILS) {
console.log(`Skipping record of type ${ion.dumpPrettyText(ionRecord.recordType)}`);
} else {
// process record
}
})
);
}
Top Tips
Add unique document Id to data
When a new document is created in QLDB, the guaranteed unique identifier is the id field found in the metadata section. In the demo app, this value is retrieved and then populated in the application data section. This is critical, as if the record is deleted (note that it will still remain in the journal as it is immutable), an empty data section is sent in the REVISION_DETAILS message. This record will still have the id of the document available in the metadata section which can be retrieved as follows:
// retrieve the id from the metadata section of the message
const id = ion
.dumpText(ionRecord.payload.revision.metadata.id)
.replace(/['"]+/g, "");
This allowed the record to identified and deleted from the table in DynamoDB
Handling duplicate and out-of-order records
QLDB streams guarantees at-least-once delivery. This means it can publish duplicate and out-of-order records to Kinesis Data Streams.
Each BLOCK record includes the blockAddress:
blockAddress: {
strandId: "GJMmYanMuDRHevK9X6MX3h",
sequenceNo: 3
}
This details the sequence number of the block within the ledger. As QLDB is immutable, each block gets appended to the end of the journal.
Each REVISION_DETAILS record includes the version number of the document in the metadata section. Each document uses an incrementing version number with the creation of the record being version 0.
If necessary, the use of one or both of these values can help to handle duplicate or out-of-order records.
Want to know more
A curated list of guides, development tools and resources for QLDB can be found at awesome-QLDB
An online guide to QLDB which is continually updated can be found at QLDB Guide

Top comments (0)