
The advancement in technology has reduced our dependence on getting the latest news from the daily newspapers. Popular websites such as Youtube and Twitter have made it convenient for us to get the latest news. However, how credible is the news from these sites?
Fake news mimic real headlines and are deliberately spread to hoax and spread propaganda among people. Marketers also use this as click-baits to attract viewers for their websites.
To solve the problem of credibility of the news on the various websites, we are going to develop a fake news detection model. Machine learning algorithms are going to help us achieve this. We are specifically using Passive-Aggressive Algorithm.
Workflow
The diagram below shows the different stages in creating the model including converting textual data to numerical data, training the model and testing it.

1. Importing Modules
The first step is to import the libraries needed to run our project. The libraries used are numpy, pandas, sklearn and seaborn.
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import PassiveAggressiveClassifier
from sklearn.metrics import accuracy_score, confusion_matrix
import seaborn as sns
2. Load data
Next, we read data from the news csv file into the Pandas DataFrame. This is done using the pd.read('filename.csv') function. Make sure the csv file is in the same folder as the Python code.
.shape function is used to output the size of the dataset.
.head() function outputs the first five records in the dataset.
news_data=pd.read_csv("news.csv")
news_data.shape
news_data.head()
(6335, 4)

3. Data Pre-processing
We need to check for null entries in our data. isnull() function does this for us and gives us the total number of null entries with the help of .sum() function
news_data.isnull().sum()
Unnamed: 0 0
title 0
text 0
label 0
dtype: int64
We then extract the labels column as that is the column with the real or fake tags.
labels=news_data.label
4. Split dataset to train and test data
This is the most essential step in machine learning. Our model is trained using the training dataset and tested using the testing dataset. The train_test_split function from Scikit learn will help us split our data. The splitting will be 80% data for the training set and the remaining 20% data for the testing set.
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(news_data['text'], labels, test_size=0.2, random_state=7)
5. Initialize TF-IDF Vectorizer
TF-IDF denotes to Term Frequency - Inverse Document Frequency.
TfidfVectorizer() is a function in Scikit learn used to convert a textual array into a TF-IDF matrix.
Term Frequency - It is the number of times a word appears in a text divided by the total number of words in the document.
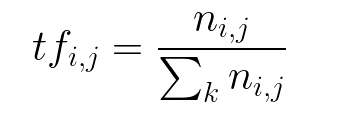
Inverse Document Frequency - It is a measure of how significant a term is in the entire data. It is determined by the weight of the rare words in all the documents in the corpus.
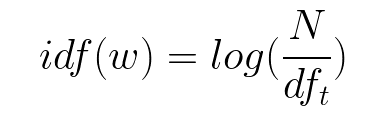
N is the number of documents and df is the number of documents containing the word w.
The TF-IDF Vectorizer formula:
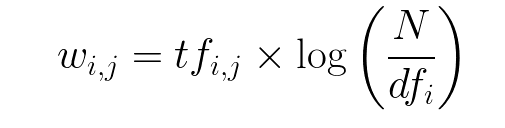
tfidf_vectorizer=TfidfVectorizer(stop_words='english', max_df=1.0)
tfidf_train=tfidf_vectorizer.fit_transform(x_train)
tfidf_test=tfidf_vectorizer.transform(x_test)
Initialize TfidfVectorizer with stop words from the English language and a maximum document frequency of 1.0.
Fit and transform the vectorizer on the train set, and transform the vectorizer on the test set.
6. Train the model with the train set
Let us train the fake news detection model using the Passive-Aggressive algorithm and check the accuracy score of the trained model.
The Passive-Aggressive algorithm is an online-learning algorithm which is used where a huge amount of data is involved and it is computationally infeasible to train the entire dataset because of its size. The algorithm remains passive to correct predictions and responds aggressively to incorrect predictions.
Initialize a Passive-Aggressive Classifier
pac=PassiveAggressiveClassifier(max_iter=20)
pac.fit(tfidf_train,y_train)
7. Test the trained model
We use the 20% test data to test for the efficiency of our trained model through the accuracy score and confusion matrix.
Check the Accuracy Score
y_pred=pac.predict(tfidf_test)
score=accuracy_score(y_test,y_pred)
print("Accuracy: ",round(score*100,2),"%")
Accuracy: 93.45 %
The trained algorithm produces an accuracy of 93.45 %
8. Build a confusion matrix
A confusion matrix is a 2 dimensional array of a classification model performance on the test data comparing predicted category labels to the true label. The binary classification include; True Positive, True Negative, False Positive and False Negative.
The matrix can be calculated from the Scikit learn as follows:
from sklearn.metrics import confusion_matrix
cf_matrix = confusion_matrix(y_test,y_pred)
print(cf_matrix)
[[573 42]
[ 38 614]]
We have 573 true positives, 38 true negatives, 42 false positives, and 614 false negatives.

Top comments (0)