Top 10 Lessons Learned in Last 10 Years
 on [Unsplash](https://unsplash.com/s/photos/code-editor?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText)](https://res.cloudinary.com/practicaldev/image/fetch/s--zbobiNfH--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1.medium.com/max/12000/1%2Aq1Lvf1cVxpD34B9l3cYG9w.jpeg) Photo by Tudor Baciu on Unsplash
Photo by Tudor Baciu on Unsplash
The way to pick good mentors is to always look for people who have successfully been through the same path you are about to embark on. Ask what they did, why and how?
This was the advice I got as a young engineer. I had the pleasure of working with some great mentors and it comes naturally to me to want to repay the debt of gratitude. In this post, I will be sharing full-stack engineering lessons I’ve learned in my career so far.
Gracias
Before we do that, a big Thank You to all my mentors, managers & colleagues who are responsible for teaching me these lessons and being part of my career journey thus far. You know who you are and I am grateful for the time we got to spend together.
Why Me, Why Now?
I’ve been in the tech industry and Silicon Valley for 10 years. In this time I’ve worked at high growth startups and ridden all the highs and lows that come part and parcel with that. Building nextgen email client to scaling electric vehicles worldwide to online shopping checkout, I’ve learned a lot. You can find my bio at the bottom if you are interested to learn more about these companies. As I look back on lessons learned, mistakes made and opportunities missed, I couldn’t help but think that some of these are very avoidable and hence I wanted to share them with you.
The Mechanics
This was a hard list to compile but I can assure you I’ve rummaged through every todo list software (google keep, mac notes, Evernote, Gmail) and journal entries from the last decade. I’ve distilled it to the top 10 lessons learned based on what I believe will stand the test of time and stay true for some years to come. The list starts from the frontend, followed by backend APIs& databases and ends with engineering best practices/processes.
Lessons Learned:
CSS Specificity
Design State From Component Hierarchy
Backend Spaghetti to Lasagne to Ravioli
Postgres in Production
Move Slow, Test Things
Invest in Automation
Master Your Tools
MVP
Research-Backed Development
Scientific Debugging
1. CSS Specificity
Mistake: My CSS is not applying. I am going to use !important
Lesson: Using !important should be reserved for special cases because they break the whole CSS hierarchy and force a particular style. Instead, learn about CSS specificity.
CSS specificity is the set of rules a browser applies to determine which CSS styling is more specific. Think of this as a point-based system that determines which CSS style gets priority and is ultimately applied to a DOM element.
If you ever wonder why your CSS is not being applied, its got to do with CSS specificity. This is a very common problem in larger projects where preprocessors like SCSS are used with complex CSS hierarchies. Understanding CSS specificity will help you reserve using !important only for rare overriding situations for example when you want to override CSS libraries or have iframes override host site styling.


Essentially ID selectors > Class selectors > Type selectors is the precedence order. !important and in-line style attributes override all CSS. For each CSS that applies to an element, you can then easily figure out which style will take effect. For example, if you load the HTML above:

In this example, the ID selector takes precedence over the type selector. If the clashing CSS selectors have the same precedence, then the last one in the CSS file will be chosen. Finally, Chrome DevTools (why would you use any other browser :)) will show you the specificity order as shown in the image above. If you can’t get your CSS to apply, look at the specificity order that Chrome uses, then add a more specific selector (id, class, type) to make your CSS more specific and indicate to the browser to select it. If you don’t want to do this mentally, check this specificity calculator: https://specificity.keegan.st/
2. Design State From Component Hierarchy
Mistake: I need to add this new state, I’m just going to put it in this reducer…hmm not sure why this reducer has all this other state…Oh well!
Lesson: Mismanaged redux state can cause confusion amongst developers and lead to bugs. If you use react and redux to structure your frontend applications, then you may consider this visualizing technique to build state and reducer hierarchies from the UI component hierarchy. There are 3 steps to go from nothing to a uniform component-state hierarchy:
Visualize the UI in a wireframe
Visualize the State hierarchy to mirror the UI
Build the reducer hierarchy to mirror the state hierarchy
Let’s look at an example where we are building a blog website that has 2 pages one for a list of blogs and another for an individual blog:
Step1: Visualize the UI in a wireframe
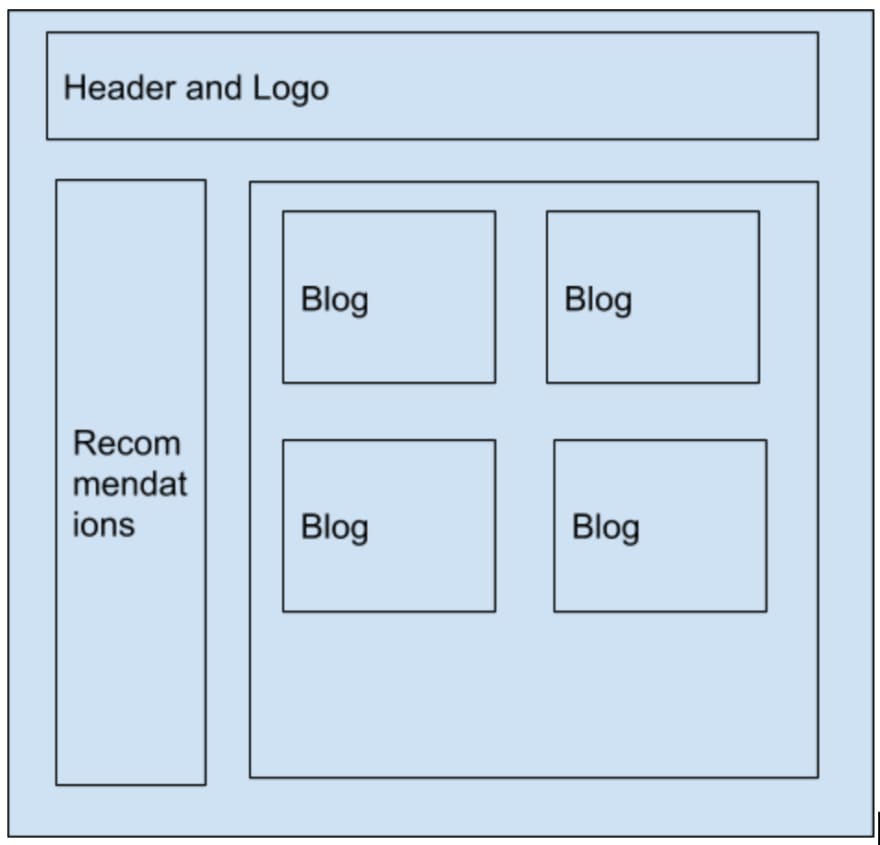
 Home Page and Individual Blog Page
Home Page and Individual Blog Page
Step2: Visualize the State hierarchy to mirror the UI
The corresponding state hierarchy diagram would look like this:
 State hierarchy
State hierarchy
Notice how the common Header state has been pulled out into the root state. Similarly, any shared state can bubble up in the hierarchy so it’s clear the child components share that state.
Step3: Build the reducer hierarchy to mirror the state hierarchy
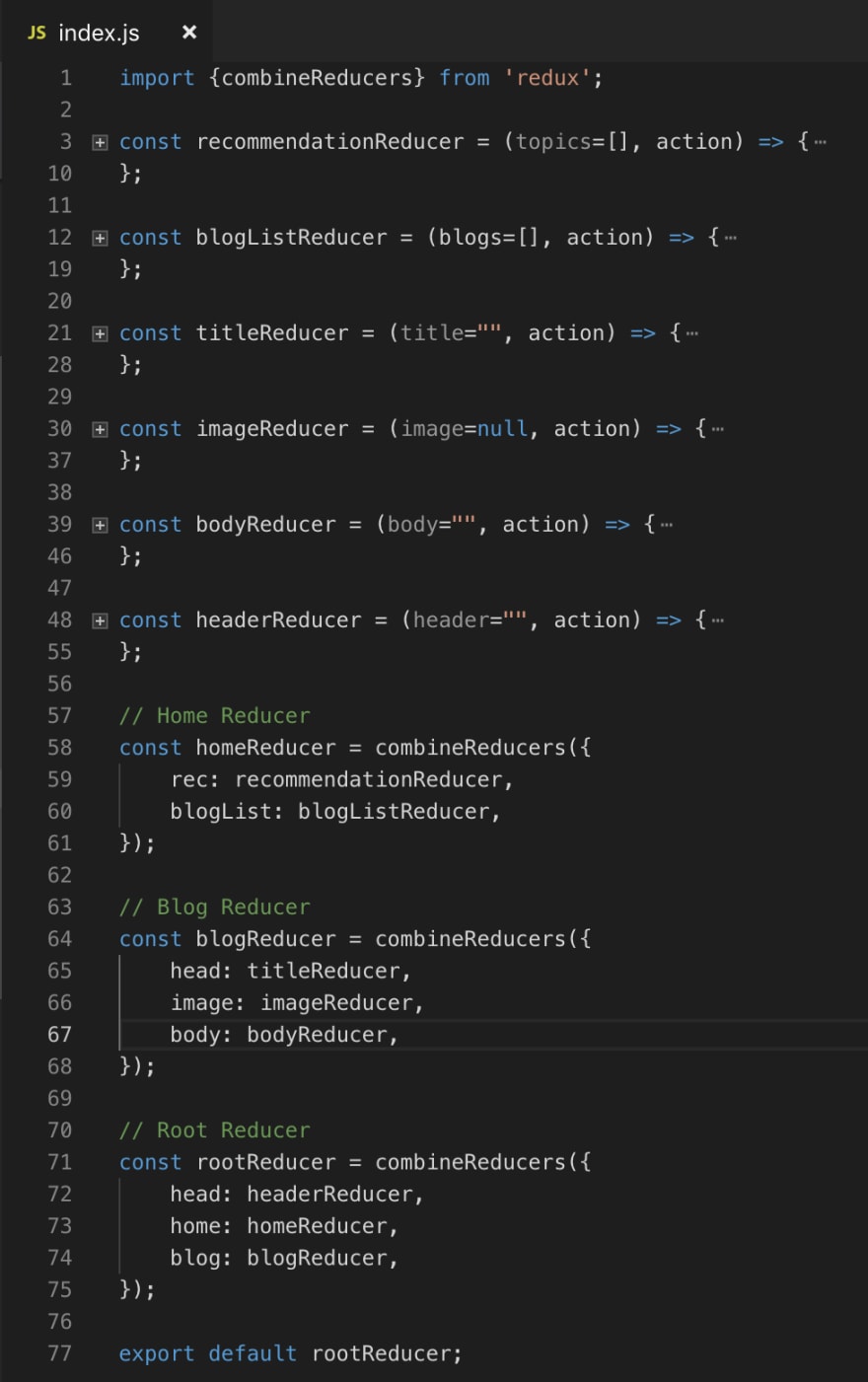 Reducer hierarchy
Reducer hierarchy
This is a simple yet powerful example that shows how to structure your state and reducer hierarchy to match the UI. This process can easily scale for complex applications and large teams. Finally, you can build actions and presentation layer on top of this structure.
3. Backend Spaghetti to Lasagne to Ravioli
 on [Unsplash](https://unsplash.com/s/photos/ravioli?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText)](https://res.cloudinary.com/practicaldev/image/fetch/s--HxqOTCs8--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1.medium.com/max/8960/1%2Aqw2VhBrFGOR2rfXctma0DA.jpeg) Photo by Lindsay Lenard on Unsplash
Photo by Lindsay Lenard on Unsplash
Mistake: How is this codebase organized? Maybe I can just add this file here seems like all other repository code lives here.
Lesson: I have written all three Italian varieties of code. And honestly, I think mini-lasagna inside a ravioli is the way to go. Organizing and training all developers to build this way keeps the codebase maintainable, testable and most importantly agile. You can easily change the implementation details of a particular ravioli a.k.a feature without affecting other features.
Lasagne is:
layered architecture
I/O in outer layers pure data structures in inner layers
Dependencies are injected inwards
Inner layers don’t depend on outer layers
Prefer composition over inheritance
Ravioli is:
Slice vs layered
Spatial locality for folders and files
Can be microservices
Put them together, you get a scalable & maintainable codebase. If you can figure out a way to structure your folders by feature names (an individual ravioli) and within each feature implement the clean architecture methods, it will last you a long time.
4. Postgres in Production
Mistake: Why is this query slow? I think Postgres is slow. I need to shard or I think it’s the ORM or maybe I need a different database Postgres is not working out for me.
Lesson: If you run Postgres in production then you **are **dealing with slow queries, table locks, infinitely waiting migrations, errors. If you are not, then good for you and also how did you do that? That doesn’t mean Postgres is no longer the right tool, it means you need to lift the curtain and see what’s happening underneath.
The best tool I’ve discovered thus far to wrangle almost all Postgres problems is pgbadger. It’s a Perl command-line tool that takes Postgres (RDS if you are on AWS) logs as input and spits out a report. The report is only as good as the logs you have enabled on Postgres. So as a first step you might want to enable these logs:
log_checkpoints = on
log_connections = on
log_disconnections = on
log_lock_waits = on
log_temp_files = 0
log_autovacuum_min_duration = 0
log_error_verbosity = default
log_min_duration_statement = 1s
In addition, you may also want to enable pg_stat_statements to analyze queries live and auto_explain to automatically explain analyze slow running queries in the log.
Running the report:
pgbadger --prefix '%m %u@%d %p %r %a : ' /pglog/postgresql.log
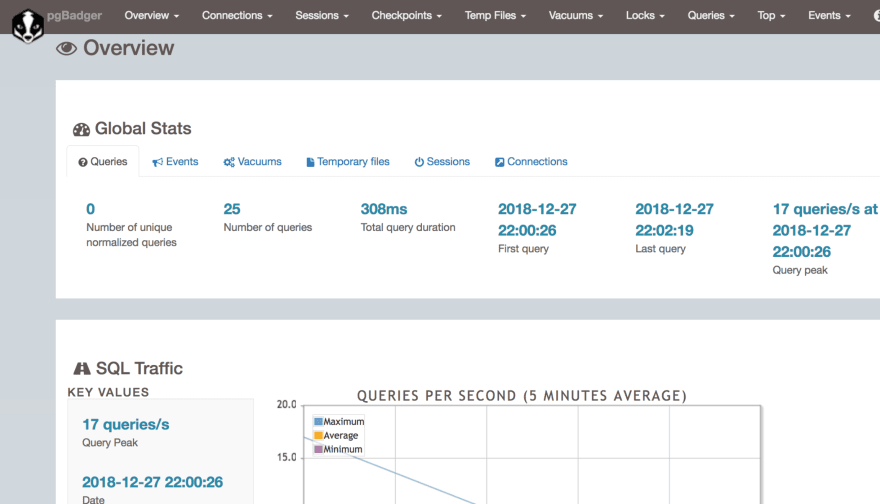
This report will aggregate data and provide a host of information about what Postgres has been up to. You will find information about errors, top slowest queries, top waiting queries, types of locks acquired, whether temp files were used for sorting or not, how often did checkpoints run, how often did vacuums run and other such information. Armed with this data you can identify and fix slow running queries & improve Postgres performance via tuning.
You can run this report on an ongoing basis (the CLI support incremental mode) and thereby stay on top of new issues.
As a bonus, if you are looking to understand the explain output you can use this tool: https://tatiyants.com/pev/#/plans/new. The tool takes explain JSON and the original query as input and will explain the explain output in a visual tree graph like below. :
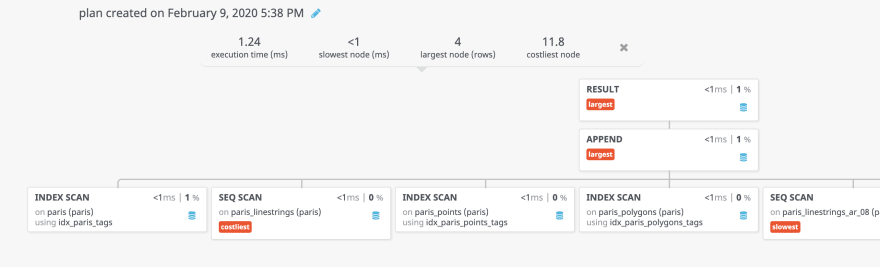
As you can see nodes will have tags for largest, slowest, costliest and so on. This will help you optimize the query based on how Postgres is executing it.
Finally, if building up competency in Postgres is not feasible I recommend hiring a DB consultancy like Percona.
5. Move Slow, Test Things
Mistake: LGTM let’s ship it!
Lesson:
](https://res.cloudinary.com/practicaldev/image/fetch/s--bWCOCDwJ--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1.medium.com/max/4744/1%2AUK8Jz_r__2nJcbLNosHMhw.png) From wikipedia: https://en.wikipedia.org/wiki/List_of_system_quality_attributes
From wikipedia: https://en.wikipedia.org/wiki/List_of_system_quality_attributes
In the era of move fast and break things this might not seem like the most popular advice but taking it slow will pay dividends. It’s better to be methodic and slow with little to no production bugs than to move fast and ship bad code.
Good engineers take into consideration all the ‘ilities of a software system. They care about not just code coverage but also weird inputs that might break the same code path. With a layered architecture, they implement mock layers and test only the layer under consideration. They not only implement unit tests but also implement integration and functional tests or if your team has a QA engineer, works with them to test those cases.
It’s okay to be slow. It’s better to be right.
6. Invest in Automation
Mistake: We hand deploy to staging and sandbox, ad-hoc. Production is also deployed by hand but once a day.
Lesson: Having a CI/CD system manage deploys means more predictable outcomes. Software moves through the pipeline in a promotional strategy and ad hoc deploys are relegated to special circumstances. This ensures the stability and reliability of the software you are shipping, which is the primary responsibility of an engineering team.
Invest in:
Training team members on how to do code reviews. You may have a varied skillset in your team and not everyone will know how to do a good code review. Invest in learning and teaching best practices for code reviews.
Using automated code review systems like peril and hound. Peril can inspect code changes and flag warnings and fail builds based on pre-configured settings. For example, you can fail a pull request if a database migration file is missing a statement_timeout or contains an unnecessary DEFAULT NULL . You can write many such checks and team-specific rules and have peril be the gatekeeper for changes. HoundCI can do similar things and the rules are fully configurable.
- Setup a CI/CD pipeline with an automated promotion strategy using tools like CircleCI . Over time, optimize build and deploy pipelines.
7. Master Your Tools
Mistake: Oh I need to find the interface for this implementation, let me just search for it. It used to be in this folder. Eh, not anymore huh. Let’s look there….let’s just ask someone.
Lesson: Not knowing how to operate your tools makes you unproductive. Can you imagine a tailor who is sloppy using a sewing machine? It’s not just about the outcome of your code, it’s also about how efficiently you build software.
](https://res.cloudinary.com/practicaldev/image/fetch/s--9vcQeAJL--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1.medium.com/max/2996/1%2AF-2_zyX8pst2F-_MtbG6Qw.png)
Know your tools, learn shortcuts. Your code editor is probably the first tool to master. This is your bread and butter. You should know how to setup tab sorting, in place source code exploration, forward and backward code depth traversal, open last editing file, navigate to interface/implementation, read file structure within a file, display call graph. If you use a text-based editor without a GUI, that’s fine too. There’s plenty of useful tricks to master with editors like Vim.
Pay attention to common operations you do manually and learn to do them via shortcuts. An easy way to accomplish that is to maintain notes on 5 shortcuts, master them until they become muscle memory then move on to the next 5.
Other common tools full-stack engineers touch daily and should master are terminal, docker, tableplus/pgadmin/some other database client UI, chrome dev tools.
8. MVP
Mistake: I think the feature will be useful. I am going to use a distributed-fault tolerant-replicated-highly available datastore. I will also build a plugin-based architecture that will make this software super extensible.
Lesson: Before building something ensure that it is the right thing to build. This is where MVP’s come in.
An ideal MVP should minimally touch all the layers, not just one layer. This is an exercise in de-risking. It’s better to build all layers minimally than to perfect a single layer. MVP does not mean tech debt or bad coding or lack of testing. It’s not throw-away code.
If an MVP is taking too long (for some measure of long) then it is probably wrong and there is probably a simpler solution.
Other things being equal, simpler explanations are generally better than more complex ones — Occam’s razor
 on [Unsplash](https://unsplash.com/s/photos/cupcake-vs-cake?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText)](https://res.cloudinary.com/practicaldev/image/fetch/s--N79kkqhH--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1.medium.com/max/9980/1%2AR_bg3K1YVS57Y1SgeZvQDQ.jpeg) Photo by Conor Brown on Unsplash
Photo by Conor Brown on Unsplash
This cupcake metaphor is another way to explain MVP. Instead of trying to build a big cake or build a perfect base layer, build a cupcake, get feedback and iterate. At the least, you’d know if people liked this new flavor.
9. Research-Backed Development
Mistake: I (engineer) think this is what we should build
Lesson: Development should be preceded by strong research to back a claim. Instead of following your intuition, perform a user study. Understand what the user needs are by interviewing them in-person or on video, run surveys, look at logs. This will help you understand your users better. You can then come up with a hypothesis and run experiments. When forming a hypothesis, use inversion to counter your own claims. Invest in an A/B testing framework that will let you run experiments.
Time is valuable. Use it wisely.** **The smartest engineers try to optimize for something that should not exist. Asking the right questions early on is very important.
10. Scientific Debugging
Mistake: There is a bug. Hmm, I think it’s because of this code change. Let me look into this file. Or maybe its a memory issue. It can be a combination of both too.
Lesson: As an engineer, you will be debugging problems with software whether as part of an incident or in your local environment. If not done via structured reasoning, debugging can be painful and slow.
How can we systematically find out why a program fails? And how can we do so without vague concepts of “intuition”, “sharp thinking,” and so on? What we want is a method of finding an explanation for the failure — a method that:
Does not require prior knowledge
Is systematic
And one that we can be sure to find the root cause and reproduce at will
Applying the scientific method to debugging problems is an unbiased way to develop a theory about the failure. The steps for scientific debugging are as follows:
Reproduce the error (Often some combination time, data, user, OS, debugger)
Observe the facts (thoroughly read logs, error traces, etc.)
Explicitly state the hypothesis in a logbook instead of doing it mentally
If you’ve identified a section of the program as being buggy, use a structured approach to narrow down the bug eg binary search
Test the hypothesis: Use logging, breakpoints, asserts
If validated, apply the fix and ensure no new breakages
If invalidated, redo steps #3 to #6
This might seem like an overkill for simple debugging situations but for complex distributed systems involving many teams, a systematic scientific debugging process provides the necessary structure to ambiguity.
Bonus
If you have reached here, you might as well read on to the 3 bonus learnings. These cover soft/personal-growth aspects.
1. Share Learnings and Serve Others
 on [Unsplash](https://unsplash.com/s/photos/sharing?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText)](https://res.cloudinary.com/practicaldev/image/fetch/s--hyAT3u73--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1.medium.com/max/4940/1%2AQy2RAaqFAQEsU0qyaRtKVA.jpeg) Photo by Pop & Zebra on Unsplash
Photo by Pop & Zebra on Unsplash
Extra-ordinary behavior is helping others grow. There is a certain level of clarity of thought you gain in the knowledge that you need to explain something in a way that someone else can understand.
Share thoughtful links on slack every day, run brown-bag sessions, demos, compliment others on positive behavior, challenge unclear decisions and give constructive feedback when you wish a different direction from someone or a decision. You can use the “Thanks for ABC….Wish that XYZ” syntax for giving feedback with a 3:1 average ratio between things you are thankful for and things you wish.
In doing so you can build a personal brand for yourself and thereby gain career capital. Research has shown that people who have a strong personal brand, online presence and track record of helping others have success and more importantly, satisfactory careers.
2. Shape Your Own World
 on [Unsplash](https://unsplash.com/s/photos/world?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText)](https://res.cloudinary.com/practicaldev/image/fetch/s--eE3QuNM9--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1.medium.com/max/12032/1%2AOw0dHCP8q0eHlZ8C3nYY-A.jpeg) Photo by Ben White on Unsplash
Photo by Ben White on Unsplash
You don’t need to accept the world the way it is. You can shape the world you perceive by taking the driver’s seat.
This might mean vocalizing your opinions during design discussions and code reviews or fixing that critical flaky test. A lot of people will tell you to speak more and get visibility to grow within a company but they never explain how. The best way to do this is to have strong opinions and the confidence to pull people in your direction. Don’t be afraid to assemble small swat teams to build/improve things. Don’t surrender power to your fears. Speak up, as long as you are not being disrespectful, you can say it.
Negative emotions are great motivators for change. If something bugs you ask yourself why and figure out how you can lead the change. If you treat every day as an avenue for growth, then life becomes an exercise.
3. Meet people
 on [Unsplash](https://unsplash.com/s/photos/collaboration?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText)](https://res.cloudinary.com/practicaldev/image/fetch/s--5qrrwFHD--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1.medium.com/max/10944/1%2ARMW1dCkork-oiUBEDgQNKA.jpeg) Photo by Perry Grone on Unsplash
Photo by Perry Grone on Unsplash
If you are like me and are trying to figure out what truly matters to you, then meet loads of people, especially the ones who interest you in unclear ways. This might mean going to conferences, participating in online communities, collaborating on hackathons & projects or any such activities. This exposure will help you figure out what you want to do. That will allow you to say no to things that don’t matter to you and be open to opportunities that matter to you.
Many successful people who feel lucky and say they were in the right place at the right time, knew what they wanted to begin with. This allowed them to be spontaneous and latch onto opportunities and minimize regrets. Default to saying **yes **when it comes to meeting smart people.
In doing this, I found out that I prefer breadth over depth, value creativity, and freedom, enjoy variety & informal relationships. Structured repetitive work, routine, stability & security are things I am not suited for. This allows me to pick projects and people that align and compliment accordingly.
If you know what you want the world will give you the information that you need.
Full Stack programming is fun. It’s a constantly evolving landscape and there is a sea of learning to surf on. Don’t take yourself or your mistakes too seriously. Share them and keep growing.
If these learning resonated with you let me know which ones did. If not, that’s okay too, still, let me know. What are some interesting things you’ve learned in your full-stack career (short or long)? Please share them below in the comments. If you feel inspired to write your own top 10 learnings, I’d encourage it.
Resources:
CSS specificity calculator: https://specificity.keegan.st/
The Clean Architecture: https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html
Screaming Architecture: https://blog.cleancoder.com/uncle-bob/2011/09/30/Screaming-Architecture.html
pgbadger: https://github.com/darold/pgbadger
Postgres query explain tool: https://tatiyants.com/pev/#/plans/new
‘ilities of software: https://codesqueeze.com/the-7-software-ilities-you-need-to-know/
HoundCI: https://github.com/houndci/hound
CircleCI: https://circleci.com/
MVP cupcake metaphor: https://www.intercom.com/blog/start-with-a-cupcake/
Inversion mental model: https://fs.blog/2013/10/inversion/

Top comments (0)