Parte da série sobre o resumo do livro Designing Data Intensive Apps.
No Capítulo 1 foi falado sobre características de sistemas de dados, e no Capítulo 2 sobre modelos de dados. Agora no capítulo 3 será abordado o tema de armazenamento de dados.
Durante muito tempo, me perguntei como exatamente os dados do banco eram armazenados. Quando usava SQL Server reparava que havia os arquivos .mdf e .ldf de cada database, mas tinha a curiosidade de descobrir como funcionava esses arquivos. Enfim, dívidas técnicas da graduação.
No livro, o autor explica algumas técnicas mais comuns utilizadas por DBs conhecidos.
Por que storage dos dados?
Em toda aplicação, os dados são armazenados inicialmente em memória, em alguma estrutura de dados, seja um mapa, lista, fila, árvore, etc.. Essa estruturas de dados formam como se fosse uma "in-memory database" temporária. Temporária por que memória RAM é volátil e não compartilhada com outros processos e/ou servidores. Em algum momento precisamos persistir esses dados de forma mais permanente, ou arriscamos perder todos os dados à qualquer crash da aplicação ou servidor.
Uma estratégia poderia ser serializar a estrutura de dados inteira em algum formato (JSON por exemplo) em um arquivo. Porém, temos que carregar o arquivo inteiro em memoria para podermos trabalhar sobre os dados. Em conjuntos de dados pequenos (de alguns MBs até alguns GBs) pode ser até possível. Mas isso não escala pois memória RAM tem um certo limite e preço alto. Armazenamento em disco é muito mais barato.
Como armazenar os dados?
Como escrever e ler todos os dados de uma vez é muito ineficiente, precisamos de alguma forma ganhar eficiencia nessas duas operações.
Um exemplo bem rudimentar de um banco de um key-value store pode ser criado da seguinte forma:
#!/bin/bash
db_set () {
echo "$1,$2" >> database
}
db_get () {
grep "^$1," database | sed -e "s/^$1,//" | tail -n 1
}
A função db_set insere um dado com uma chave e um valor. A função db_get retorna o valor associado a uma determinada chave.
$ db_set 42 '{"name":"San Francisco","attractions":["Golden Gate Bridge"]}'
$ db_get 42
{"name":"San Francisco","attractions":["Golden Gate Bridge"]}
Repare que a função db_set faz somente um append no arquivo (com o uso do operador >>). Fazer append em algum arquivo funciona de maneira bem eficiente e mais rápida que uma escrita randômica, ou seja, em uma posição aleatória do arquivo.
Porém, a função db_get já tem alguns problemas. Fazer uma pesquisa por uma chave no arquivo requer percorrer potencialmente todo o arquivo (o que é comumente conhecido como full-table scan). Quem já trabalhou com qualquer banco de dados sabe que a solução para full-table scans é um índice.
Hashmap Index
Digamos que voce tenha os seguintes dados em disco:

Podemos construir um índice usando um Hashmap Index, que é uma estrutura de dados que contêm pares chave e valor, ordenados por chave, e o índice funcionaria mapeando as chaves para um offset de bytes no arquivo.
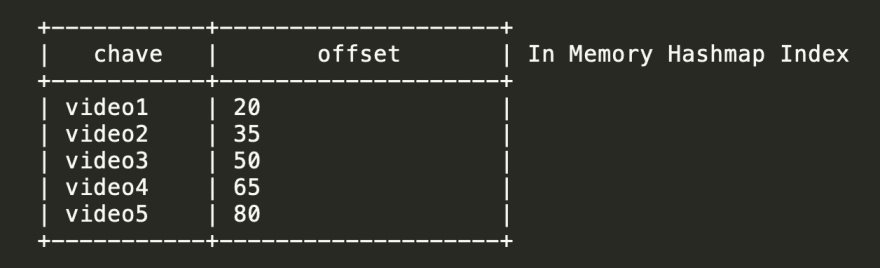
Como dissemos antes, para mantermos performance, escritas são um simples append no arquivo. Porém, se formos adicionando dados no nosso arquivo para sempre, muito rápido ele fica enorme. Além disso, precisamos também de operações de update e delete, além de insert.

A ideia é escrever até que o tamanho do arquivo atinga um certo valor (64KB digamos), e quando esse tamanho for atingido, cria-se um novo segmento de escrita. De tempos em tempos, roda-se um algoritmo que faz compacta esses segmentos com um merge das chaves, geralmente assumindo-se que os últimos valores escritos são os mais atuais, e descartando-se os valores antigos.
Obs: não confunda os dois key-value pairs. Um é armazenado em disco e contém os dados em si. O índice (que armazena os offsets em disco) é armazenado em memória.
Otimização com LSM Tree
Vamos ver agora uma estrutura mais robusta para construção de índices construída em cima dessa ideia de um Hashmap Index.
A ideia é ter duas estruturas de dados separadas. Uma chamada Memtable e outra chamada Sorted String Table (SSTable).
A Memtable é alguma estrutura de dados ordenada, geralmente alguma árvore balanceada como Red-Black Tree ou AVL Tree. Ambas possuem boa eficiencia nas operações de inserção e busca, O(log n). Então podemos manter essa estrutura em memória que irá manter as atualizações mais recentes. Quando essa estrutura chegar a um tamanho limite definido, os dados são escritos em disco, em uma Sorted String Table (SSTable).
A estrutura da SSTable é bem parecida com a descrita acima do Hashmap Index, com a diferença que ao invés dos dados estarem em ordem de escrita, eles são ordenados por chave. Isso aumenta a eficiencia da compactação dos segmentos, pois os dados já estão ordenados. Além disso, o índice em memória não precisa necessariamente conter todas as chaves, pois os dados em disco estão sempre ordenados, caso uma chave não esteja no índice, é possível achar uma chave de valor mais próximo e fazer o scan em disco a partir desse ponto, e assim não ter que fazer um full-table scan em disco, que seria muito custoso.

Essa estrutura de dados dualizada tem o nome de Log-Structured Merge Tree (LSM Tree).
Alguns problemas ainda existem com essa solução:
Crash recovery: caso haja algum crash no servidor ou aplicação, podemos perder os dados da Memtable que ainda não foram persistidos em disco. Para contornar esse problema, ao mesmo tempo que inserimos dados na Memtable, salvamos uma réplica desses dados em disco em ordem de escrita, assim é possível recuperar a Memtable com os dados em disco depois de uma falha.
Outro problema de performance que pode ocorrer é numa busca por uma chave que não existe. Para não ter que fazer uma busca tanto na Memtable quanto na SSTable inteiras, podemos utilizar Bloom Filters, que é uma estrutura de dados probabilística que pode dizer de maneira eficiente que um dado talvez exista no conjunto, mas que diz que um dado com certeza não existe no conjunto.
B-Trees
Índice com LSM Tree é uma técnica até recente. E a técnica mais comum e mais utilizada é diferente: B-Trees.
B-Tree é uma estrutura de dados interessante pois permite que cada nó da arvore tenha mais de um elemento. Isso permite que a arvore tenha uma altura não muito grande, possibilitando armazenar muitos dados de maneira eficiente.
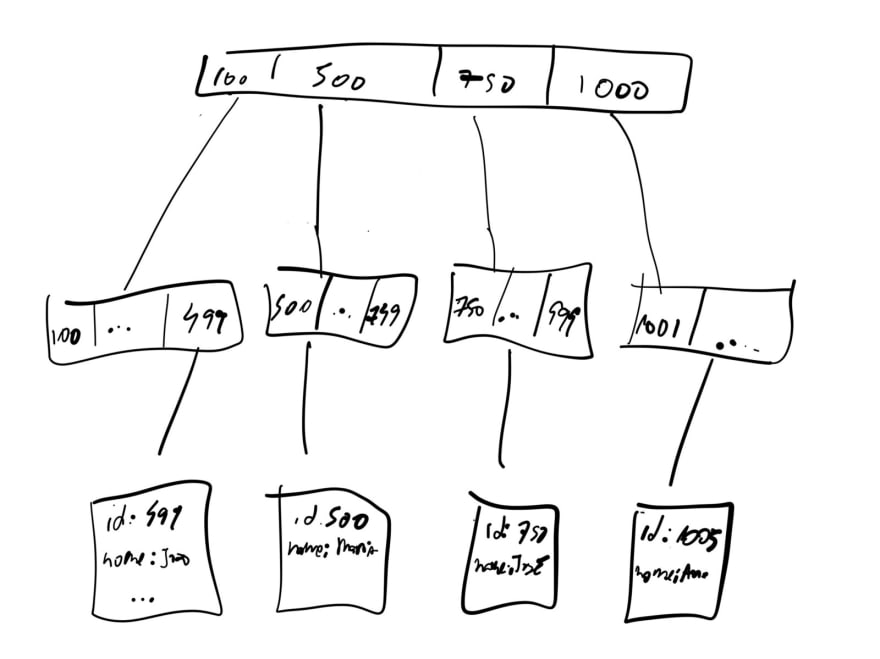
Na B-Tree, os dados em si são armazenados nas folhas. Esses dados podem estar armazenados em memória ou em disco. E os nós, podem servir de índice para esses dados. Como cada nó possui mais de um elemento, é possível carregar blocos de dados de uma vez para serem processados mais eficientemente em memória e depois persistidos em disco novamente.
Armazenando dados com B-Trees também requer um log append-only, similar ao da LSM-Tree, geralmente chamado de Write-Ahead log (WAL), para evitar perda de dados em caso de falhas, com a diferença que os dados são escritos primeiro no WAL, depois persistidos na árvore.
Vantagens e desvantagens de cada abordagem
LSM Trees costumam ter performance de escrita maior, pois os dados podem ser persistidos mais rapidamente na Memtable, e as escritas em disco de SSTables são sequenciais. Apesar de que configurações ruins de merge e compactação de SSTables podem impactar negativamente a performance de escrita.
B-Trees têm a desvantagem de ter que sempre escrever os dados duas vezes (no WAL e na arvore) e tem maior incidencia de escritas randômicas em diferentes segmentos da árvore, que é bem menos eficiente que escrita sequencial, principalmente em discos magnéticos ao invés de SSDs.
Ao contrário de LSM-Trees que podem ter as chaves na Memtable e nas SSTables, B-Tree possuem as chaves existem somente em um lugar, o que é uma enorme vantagem para manutenção de dados consistentes e isolamento de transações.
Esse é um assunto bem extenso e complexo e aqui eu só dei uma resumida bem rápida e de alto nível. O livro aborda outros assuntos como storage para bancos de dados de analytics, column storage, múltiplos índices. Para não tornar esse post muito longo, recomendo a leitura do livro e de literatura adicional sobre o assunto.
originalmente publicado em: https://medium.com/@breno_ferreira/designing-data-intensive-apps-cap%C3%ADtulo-3-eeec8782ab22
Conteúdo sob a licensa CC-BY-NC

Top comments (0)