Camunda Cloud Architecture Blog Post Series — Part 1

Have you started your first project using process automation as a service with Camunda Cloud? One of your first tasks would be to sketch the basic architecture of your solution, and this blog post will guide you through some important early questions such as how to connect the workflow engine Zeebe with your application or with remote systems? Or what’s a job worker, what should it do, and how many do you need?
This post is the first piece of a series of upcoming blog posts:
- Part 1: Connecting Camunda Cloud With Your World (this post)
- Part 2: Service Interaction Patterns with BPMN and Camunda Cloud (coming soon)
- Part 3: Writing Good Job Worker Code For Camunda Cloud (coming soon)
Connecting the Workflow Engine with Your Application
The workflow engine Zeebe is a remote system for your applications, just like a database. Your application connects with Zeebe via remote protocols, gRPC to be precise, which is typically hidden from you, like when using a database driver based on ODBC or JDBC.
With Camunda Cloud and the Zeebe workflow engine there are two basic options:
- You write some programming code that typically leverages the client library for the programming language of your choice.
- You use some existing connector or bridge (more on terminology later) which just needs a configuration.
As with everything in life both approaches have trade-offs that will be discussed later in this post, but let’s describe the options first.
Programming Glue Code
In order to write code that connects to the workflow engine Zeebe, you typically embed the Zeebe client library into your application, which of course can also be a service or microservice. If you have multiple applications that connect to Zeebe all of them will require the client library. If you want to use a programming language where no such client library exists, you can generate a gRPC client yourself.
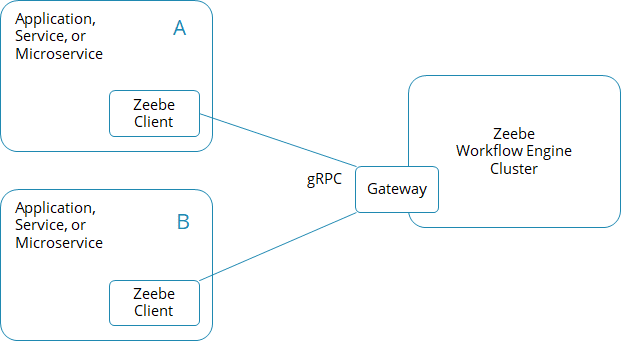
Your application can basically do two things with the client:
- Actively call Zeebe , for example, to start process instances, correlate messages, or deploy process definitions.
- Subscribe to tasks created in the workflow engine in the context of BPMN service tasks.
Calling Zeebe
Using the Zeebe client’s API you can communicate with the workflow engine. The two most important API calls are to start new process instances and to correlate messages to a process instance.
Start process instances using the Java Client :
processInstance = zeebeClient.newCreateInstanceCommand()
.bpmnProcessId("someProcess").latestVersion()
.variables( someProcessVariablesAsMap )
.send();
Start process instances using the NodeJS Client :
const processInstance = await zbc.createWorkflowInstance({
bpmnProcessId: 'someProcess',
version: 5,
variables: {
testData: 'something',
}
})
Correlate messages to process instances using the Java Client :
zeebeClient.newPublishMessageCommand() //
.messageName("messageA")
.messageId(uniqueMessageIdForDeduplication)
.correlationKey(message.getCorrelationid())
.variables(singletonMap("paymentInfo", "YeahWeCouldAddSomething"))
.send();
Correlate messages to process instances using the NodeJS Client :
zbc.publishMessage({
name: 'messageA',
messageId: messageId,
correlationKey: correlationId,
variables: {
valueToAddToWorkflowVariables: 'here',
status: 'PROCESSED'
},
timeToLive: Duration.seconds.of(10)
})
This allows you to connect Zeebe with any external system by writing some custom glue code. We will look at common technology examples to illustrate this in a minute.
Subscribing to Tasks Using a Job Worker
In order to implement service tasks of a process model, you can write code that subscribes to the workflow engine. In essence, you will write some glue code that is called whenever a service task is reached (which internally creates a job, hence the name).
Glue code in Java:
class ExampleJobHandler implements JobHandler {
public void handle(final JobClient client, final ActivatedJob job) {
// here: business logic that is executed with every job
client.newCompleteCommand(job.getKey()).send().join();
}
}
Glue code in NodeJS:
function handler(job, complete, worker) {
// here: business logic that is executed with every job
complete.success()
}
Now, this handler needs to be connected to Zeebe, which is generally done by subscriptions, which internally use long polling to retrieve jobs.
Open subscription via the Zeebe Java client:
zeebeClient
.newWorker()
.jobType("serviceA")
.handler(new ExampleJobHandler())
.timeout(Duration.ofSeconds(10))
.open()) {waitUntilSystemInput("exit");}
Open subscription via the Zeebe NodeJS client:
zbc.createWorker({
taskType: 'serviceA',
taskHandler: handler,
})
You can also use integrations in certain programming frameworks, like Spring Zeebe in the Java world, which starts the job worker and implements the subscription automatically in the background for your glue code.
A subscription for your glue code is opened automatically by the Spring integration:
@ZeebeWorker(type = "serviceA")
public void handleJobFoo(final JobClient client, final ActivatedJob job) {
// here: business logic that is executed with every job
client.newCompleteCommand(job.getKey()).send().join();
}
We plan to release a separate post to discuss best practices around writing good job worker code soon.
Technology Examples
Most projects want to connect to specific technologies, at the moment most people ask me for REST, messaging or Kafka. So let’s have a look how you can handle these technologies.
REST
You could build a piece of code that provides a REST endpoint in the language of choice and then starts a process instance.
The Ticket Booking Example contains an example using Java and Spring Boot for the REST endpoint. Similarly you can leverage the Spring Boot extension to startup job workers that will execute outgoing REST calls.

You can find NodeJS sample code for the REST endpoint in the Flowing Retail example.
Messaging
You can do the same for messages, which is often AMQP nowadays.
The Ticket Booking Example contains an example for RabbitMQ, Java and Spring Boot. It provides a message listener to correlate incoming messages with waiting process instances, and glue code to send outgoing messages onto the message broker.

Note that the support for the send task used in this diagram will be introduced with Camunda Cloud 1.1 in July 2021. Prior to the 1.1 version you might have to use a service task as a workaround.
In the next blog post in this series you will learn why I used a send and receive task here, and not simply a service task, which would technically also work (spoiler alert: because the payment service might be long running, think about expired credit cards that need to be updated or wire transfers that need to happen).
The same concept will apply to other programming languages, for example you could use the NodeJS client for RabbitMQ and the NodeJS client for Zeebe to create the same type of glue code as shown above.
Apache Kafka
You can do the same trick with Kafka topics. The Flowing Retail example shows this using Java, Spring Boot and Spring Cloud Streams. There is code to subscribe to a Kafka topic and start new process instances for new records, and there is some glue code to create new records when a process instance executes a service task. Of course, you could also use other frameworks to achieve the same result.

Designing Applications With Glue Code
Typical applications will include multiple pieces of glue code in one codebase.

For example, the onboarding microservice shown in the figure above includes
- A REST endpoint, that starts a process instance (1)
- The process definition itself (2), probably auto-deployed to the workflow engine during the startup of the application
- Glue code subscribing to the two service tasks that shall call a remote REST API (3) and (4).
A job worker will be started automatically as part of the application to handle the subscriptions. In this example, the application is written in Java, but again, it could be any supported programming language.
Using Existing Connectors or Bridges
As you could see, the glue code is relatively simple, but you need to write code. Sometimes you might prefer using an out-of-the-box component connecting Zeebe with the technology you need just by configuration. This component is called a “ connector ” or a “ bridge ” (I added a note about terminology below, you can see both terms as synonyms),
A connector can be uni or bidirectional and is typically one dedicated application that implements the connection that translates in one or both directions of communication. Such a connector might also be helpful in case integrations are not that simple anymore.

For example, the HTTP connector is a one-way connector that contains a job worker that can process service tasks doing HTTP calls as visualized in the example in the following figure.

Another example is the Kafka Connector as illustrated below.

This is a bidirectional connector which contains a Kafka listener for forwarding Kafka records to Zeebe and also a job worker which creates Kafka records every time a service task is executed. This is illustrated by the following example.

Existing Connectors And Their Status
Most connectors are currently community extensions, which basically means that they are not officially supported by Camunda, but by community members (who sometimes are Camunda employees). While this sounds like a restriction, it can also mean there is more flexibility to make progress.
A list of community-maintained connectors can be found at https://awesome.zeebe.io/.
Using Connectors in Camunda Cloud
Currently, connectors are not operated as part of the Camunda Cloud offering, which means you need to operate them yourself in your environment, which might be a private or public cloud.

Pros & Cons of Connectors
In general, connectors are an interesting way to solve complex integrations where little customization is needed , such as the Camunda RPA bridge to connect RPA bots (soon to be available for Camuna Cloud).
Good use of connectors are also scenarios where you don’t need custom glue code , for example when orchestrating serverless functions on AWS with the AWS Lambda Connector. This connector can be operated once and used in different processes.
But there are also common downsides with connectors. First, the possibilities are limited to what the creator of the connector has foreseen. In reality, you might have slightly different requirements and hit a limitation of a connector soon.
Second, the connector requires you to operate this connector in addition to your own application. The complexity associated with this depends on your environment.
Third, testing your glue code gets harder , as you can’t easily hook in mocks into such a connector — as you could in your own glue code.
As a general rule of thumb, prefer custom glue code whenever you don’t have a good reason to go with an existing connector (like the reasons mentioned above).
Reusing Your Own Integration Logic By Extracting Connectors
If you need to integrate with certain infrastructure regularly, like for example your CRM system, you might also want to create your own CRM connector, run it centralized and reuse it in various applications.
In general, we recommend not to start such connectors too early. Don’t forget, that such a connector gets hard to adjust once in production and reused across multiple applications. Also, it is often much harder to extract all configuration parameters correctly and fill them from within the process, than it would be to have bespoke glue code in the programming language of your choice.
So you should only extract a full-blown connector if you understand exactly what you need.
Don’t forget about the possibility to extract common glue code in a simple library that is then used at different places. But note that updating a library that is used in various other applications can be harder than updating one central connector. So as with everything in life, the best approach depends on your scenario.
But whenever you have such glue code running and really understand the implications of making it a connector as well as the value it will bring, it can make a lot of sense.
Glossary
I don’t want to close this post before summarizing the various terms used in this post (you might also be interested to have a look in the Camunda Cloud glossary):
- Bridge : Synonym for “connector”.
- Connector : A piece of software that connects Zeebe with some other system or infrastructure. Might be uni or bidirectional and possibly includes a job worker. The boundary between connector and job worker can be fuzzy, in general connectors connect to other active pieces of software. For example, a ‘DMN connector’ might connect Zeebe to a managed DMN Engine, a ‘DMN worker’ will use a DMN library to execute decisions.
- Glue Code : Any piece of programming code that is connected to the process model (e.g. the handler part of a job worker).
- Job Worker : Active software component that subscribes to Zeebe to execute available jobs (typically when a process instance reaches a service task).
- Worker : Synonym for “job worker”.
Conclusion
This blog post walked you through some basics to connect Zeebe, the workflow engine within Camunda Cloud, with your environment. This will be mostly about writing some custom glue code in the programming language of your choice and use existing client libraries. In some cases, you might also want to leverage existing connectors or bridges, at least as a starting point.
You can find more information about process solution architecture and glue code also in my latest book Practical Process Automation with O’Reilly.
Subscribe to me on Twitter to ensure you see part two of this series, that will be about service interaction patterns with BPMN and Camunda Cloud.
Bernd Ruecker is co-founder and chief technologist of Camunda as well as author or Practical Process Automation with O’Reilly. He likes speaking about himself in the third-person. He is passionate about developer-friendly process automation technology. Connect via LinkedIn or follow him onTwitter. As always, he loves getting your feedback. Comment below orsend him an email.

Top comments (0)