The Worker module of Apache DolphinScheduler is one of the core components of its distributed scheduling system, responsible for task execution, resource management, and dynamic cluster scheduling. This article will analyze its source code to reveal its design philosophy and implementation details.
1. Worker Receives Master RPC Request Architecture

The Netty service of the Worker provides interfaces that are called by the Master via JDK dynamic proxies. For details, please refer to the explanation for the DolphinScheduler alert module.
Interface Definition:
@RpcService
public interface ITaskInstanceOperator {
@RpcMethod
TaskInstanceDispatchResponse dispatchTask(TaskInstanceDispatchRequest taskInstanceDispatchRequest);
@RpcMethod
TaskInstanceKillResponse killTask(TaskInstanceKillRequest taskInstanceKillRequest);
@RpcMethod
TaskInstancePauseResponse pauseTask(TaskInstancePauseRequest taskPauseRequest);
@RpcMethod
UpdateWorkflowHostResponse updateWorkflowInstanceHost(UpdateWorkflowHostRequest updateWorkflowHostRequest);
}
Interfaces annotated with @RpcService and methods annotated with @RpcMethod are injected into the Worker’s Netty handler and dynamically proxied by the Master.
2. Task Dispatch
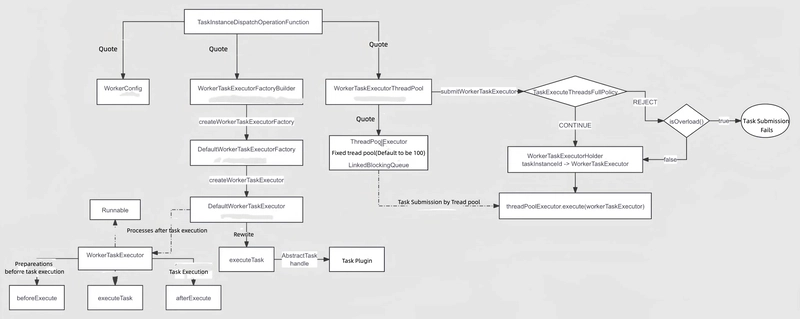
2.1 WorkerConfig
WorkerConfig reads configurations starting with "worker" from application.yaml under the Worker module.
2.2 WorkerTaskExecutorFactoryBuilder
This is a factory builder for task executors, encapsulating DefaultWorkerTaskExecutorFactory, which in turn creates DefaultWorkerTaskExecutor. The parent class of DefaultWorkerTaskExecutor is WorkerTaskExecutor, which itself is a thread.
2.3 WorkerTaskExecutorThreadPool
This is essentially a wrapper around a fixed-thread pool.
2.4 Start from the operator
public TaskInstanceDispatchResponse operate(TaskInstanceDispatchRequest taskInstanceDispatchRequest) {
log.info("Receive TaskInstanceDispatchRequest: {}", taskInstanceDispatchRequest);
TaskExecutionContext taskExecutionContext = taskInstanceDispatchRequest.getTaskExecutionContext();
try {
taskExecutionContext.setHost(workerConfig.getWorkerAddress());
taskExecutionContext.setLogPath(LogUtils.getTaskInstanceLogFullPath(taskExecutionContext));
LogUtils.setWorkflowAndTaskInstanceIDMDC(
taskExecutionContext.getProcessInstanceId(),
taskExecutionContext.getTaskInstanceId());
if (!ServerLifeCycleManager.isRunning()) {
log.error("Server is not running. Reject task: {}", taskExecutionContext.getProcessInstanceId());
return TaskInstanceDispatchResponse.failed(taskExecutionContext.getTaskInstanceId(),
"Server is not running");
}
TaskMetrics.incrTaskTypeExecuteCount(taskExecutionContext.getTaskType());
WorkerTaskExecutor workerTaskExecutor = workerTaskExecutorFactoryBuilder
.createWorkerTaskExecutorFactory(taskExecutionContext)
.createWorkerTaskExecutor();
if (!workerTaskExecutorThreadPool.submitWorkerTaskExecutor(workerTaskExecutor)) {
log.info("Submit task: {} to wait queue failed", taskExecutionContext.getTaskName());
return TaskInstanceDispatchResponse.failed(taskExecutionContext.getTaskInstanceId(),
"WorkerManagerThread is full");
} else {
log.info("Submit task: {} to wait queue success", taskExecutionContext.getTaskName());
return TaskInstanceDispatchResponse.success(taskExecutionContext.getTaskInstanceId());
}
} finally {
LogUtils.removeWorkflowAndTaskInstanceIdMDC();
}
}
LogUtils.getTaskInstanceLogFullPath(taskExecutionContext) analysis
org.apache.dolphinscheduler.plugin.task.api.utils.LogUtils#getTaskInstanceLogFullPath: Get the full path of task logs.
/**
* Get task instance log full path.
*
* @param taskExecutionContext task execution context.
* @return task instance log full path.
*/
public static String getTaskInstanceLogFullPath(TaskExecutionContext taskExecutionContext) {
return getTaskInstanceLogFullPath(
DateUtils.timeStampToDate(taskExecutionContext.getFirstSubmitTime()),
taskExecutionContext.getProcessDefineCode(),
taskExecutionContext.getProcessDefineVersion(),
taskExecutionContext.getProcessInstanceId(),
taskExecutionContext.getTaskInstanceId());
}
org.apache.dolphinscheduler.plugin.task.api.utils.LogUtils#getTaskInstanceLogFullPath:Splicing the full path of task logs.
/**
* todo: Remove the submitTime parameter?
* The task instance log full path, the path is like:{log.base}/{taskSubmitTime}/{workflowDefinitionCode}/{workflowDefinitionVersion}/{}workflowInstance}/{taskInstance}.log
*
* @param taskFirstSubmitTime task first submit time
* @param workflowDefinitionCode workflow definition code
* @param workflowDefinitionVersion workflow definition version
* @param workflowInstanceId workflow instance id
* @param taskInstanceId task instance id.
* @return task instance log full path.
*/
public static String getTaskInstanceLogFullPath(Date taskFirstSubmitTime,
Long workflowDefinitionCode,
int workflowDefinitionVersion,
int workflowInstanceId,
int taskInstanceId) {
if (TASK_INSTANCE_LOG_BASE_PATH == null) {
throw new IllegalArgumentException(
"Cannot find the task instance log base path, please check your logback.xml file");
}
final String taskLogFileName = Paths.get(
String.valueOf(workflowDefinitionCode),
String.valueOf(workflowDefinitionVersion),
String.valueOf(workflowInstanceId),
String.format("%s.log", taskInstanceId)).toString();
return TASK_INSTANCE_LOG_BASE_PATH
.resolve(DateUtils.format(taskFirstSubmitTime, DateConstants.YYYYMMDD, null))
.resolve(taskLogFileName)
.toString();
}
org.apache.dolphinscheduler.plugin.task.api.utils.LogUtils#getTaskInstanceLogBasePath: Read the configuration in logback-spring.xml and get the basic path of the task instance log. In fact, it is to get the /logs-based path in the root directory.
/**
* Get task instance log base absolute path, this is defined in logback.xml
*
* @return
*/
public static Path getTaskInstanceLogBasePath() {
return Optional.of(LoggerFactory.getILoggerFactory())
.map(e -> (AppenderAttachable<ILoggingEvent>) (e.getLogger("ROOT")))
.map(e -> (SiftingAppender) (e.getAppender("TASKLOGFILE")))
.map(e -> ((TaskLogDiscriminator) (e.getDiscriminator())))
.map(TaskLogDiscriminator::getLogBase)
.map(e -> Paths.get(e).toAbsolutePath())
.orElse(null);
}
worker的 logback-spring.xml :
<configuration scan="true" scanPeriod="120 seconds">
<property name="log.base" value="logs"/>
...
<appender name="TASKLOGFILE" class="ch.qos.logback.classic.sift.SiftingAppender">
<filter class="org.apache.dolphinscheduler.plugin.task.api.log.TaskLogFilter"/>
<Discriminator class="org.apache.dolphinscheduler.plugin.task.api.log.TaskLogDiscriminator">
<key>taskInstanceLogFullPath</key>
<logBase>${log.base}</logBase>
</Discriminator>
<sift>
<appender name="FILE-${taskInstanceLogFullPath}" class="ch.qos.logback.core.FileAppender">
<file>${taskInstanceLogFullPath}</file>
<encoder>
<pattern>
[%level] %date{yyyy-MM-dd HH:mm:ss.SSS Z} - %message%n
</pattern>
<charset>UTF-8</charset>
</encoder>
<append>true</append>
</appender>
</sift>
</appender>
...
<root level="INFO">
<appender-ref ref="STDOUT"/>
<appender-ref ref="TASKLOGFILE"/>
</root>
</configuration>
The final adess is:
/opt/dolphinscheduler/worker-server/logs/20240615/13929490938784/1/1815/1202.log
2.5 Explanation of DefaultWorkerTaskExecutor
TaskInstanceDispatchOperationFunction#operate
// TODO Create a WorkerTaskExecutor using WorkerTaskExecutorFactoryBuilder
WorkerTaskExecutor workerTaskExecutor = workerTaskExecutorFactoryBuilder
.createWorkerTaskExecutorFactory(taskExecutionContext)
.createWorkerTaskExecutor();
// TODO Directly submit the task
if (!workerTaskExecutorThreadPool.submitWorkerTaskExecutor(workerTaskExecutor)) {
log.info("Submit task: {} to wait queue failed", taskExecutionContext.getTaskName());
return TaskInstanceDispatchResponse.failed(taskExecutionContext.getTaskInstanceId(),
"WorkerManagerThread is full");
} else {
log.info("Submit task: {} to wait queue success", taskExecutionContext.getTaskName());
return TaskInstanceDispatchResponse.success(taskExecutionContext.getTaskInstanceId());
}
Directly submits the task using:
workerTaskExecutorThreadPool.submitWorkerTaskExecutor(workerTaskExecutor)
WorkerTaskExecutor is a thread
Since it is a thread, let's check its run method:
public void run() {
try {
// TODO Set process and task instance ID in MDC (similar to ThreadLocal usage)
LogUtils.setWorkflowAndTaskInstanceIDMDC(
taskExecutionContext.getProcessInstanceId(),
taskExecutionContext.getTaskInstanceId());
// TODO Set task log path in MDC
LogUtils.setTaskInstanceLogFullPathMDC(taskExecutionContext.getLogPath());
// TODO Print task header
TaskInstanceLogHeader.printInitializeTaskContextHeader();
// TODO Initialize the task (set start time and taskAppId)
initializeTask();
// TODO If in DRY_RUN mode, skip execution and mark success
if (DRY_RUN_FLAG_YES == taskExecutionContext.getDryRun()) {
taskExecutionContext.setCurrentExecutionStatus(TaskExecutionStatus.SUCCESS);
taskExecutionContext.setEndTime(System.currentTimeMillis());
WorkerTaskExecutorHolder.remove(taskExecutionContext.getTaskInstanceId());
// TODO Send result message
workerMessageSender.sendMessageWithRetry(taskExecutionContext,
ITaskInstanceExecutionEvent.TaskInstanceExecutionEventType.FINISH);
log.info("The current execute mode is dry run, stopping further execution.");
return;
}
// TODO Print task plugin header
TaskInstanceLogHeader.printLoadTaskInstancePluginHeader();
// TODO Pre-execution steps
beforeExecute();
// TODO Create callback function
TaskCallBack taskCallBack = TaskCallbackImpl.builder()
.workerMessageSender(workerMessageSender)
.taskExecutionContext(taskExecutionContext)
.build();
TaskInstanceLogHeader.printExecuteTaskHeader();
// TODO Execute the task
executeTask(taskCallBack);
TaskInstanceLogHeader.printFinalizeTaskHeader();
// TODO Post-execution cleanup
afterExecute();
closeLogAppender();
} catch (Throwable ex) {
log.error("Task execution failed due to an exception", ex);
afterThrowing(ex);
closeLogAppender();
} finally {
LogUtils.removeWorkflowAndTaskInstanceIdMDC();
LogUtils.removeTaskInstanceLogFullPathMDC();
}
}
2.5.1 Dry Run Mode
If the task is in dry run mode, it is marked as successful without execution:
if (DRY_RUN_FLAG_YES == taskExecutionContext.getDryRun()) {
taskExecutionContext.setCurrentExecutionStatus(TaskExecutionStatus.SUCCESS);
taskExecutionContext.setEndTime(System.currentTimeMillis());
WorkerTaskExecutorHolder.remove(taskExecutionContext.getTaskInstanceId());
workerMessageSender.sendMessageWithRetry(taskExecutionContext,
ITaskInstanceExecutionEvent.TaskInstanceExecutionEventType.FINISH);
log.info("The current execute mode is dry run, stopping further execution.");
return;
}
2.5.2 Pre-Execution Setup (beforeExecute())
This phase sets up the task execution environment, such as reporting to the Master, creating a working directory, downloading necessary resources, and initializing the task.
protected void beforeExecute() {
taskExecutionContext.setCurrentExecutionStatus(TaskExecutionStatus.RUNNING_EXECUTION);
workerMessageSender.sendMessageWithRetry(taskExecutionContext,
ITaskInstanceExecutionEvent.TaskInstanceExecutionEventType.RUNNING);
log.info("Sent task status RUNNING_EXECUTION to master: {}", taskExecutionContext.getWorkflowInstanceHost());
TaskExecutionContextUtils.createTaskInstanceWorkingDirectory(taskExecutionContext);
log.info("WorkflowInstanceExecDir: {} check successfully", taskExecutionContext.getExecutePath());
TaskChannel taskChannel = Optional.ofNullable(taskPluginManager.getTaskChannelMap()
.get(taskExecutionContext.getTaskType()))
.orElseThrow(() -> new TaskPluginException("Task plugin not found"));
log.info("Create TaskChannel: {} successfully", taskChannel.getClass().getName());
ResourceContext resourceContext = TaskExecutionContextUtils.downloadResourcesIfNeeded(taskExecutionContext);
taskExecutionContext.setResourceContext(resourceContext);
task = taskChannel.createTask(taskExecutionContext);
log.info("Task plugin instance: {} created successfully", taskExecutionContext.getTaskType());
task.init();
log.info("Successfully initialized task plugin instance.");
task.getParameters().setVarPool(taskExecutionContext.getVarPool());
log.info("Set taskVarPool: {} successfully", taskExecutionContext.getVarPool());
}
2.5.3 Task Execution (executeTask())
TaskCallBack taskCallBack = TaskCallbackImpl.builder()
.workerMessageSender(workerMessageSender)
.taskExecutionContext(taskExecutionContext)
.build();
TaskInstanceLogHeader.printExecuteTaskHeader();
executeTask(taskCallBack);
Execution involves replacing parameters, setting up the shell script, and running it in a process:
process = iShellInterceptor.execute();
Shell execution logs are parsed and monitored:
parseProcessOutput(this.process);
2.5.4 Post-Execution Cleanup (afterExecute())
protected void afterExecute() {
sendAlertIfNeeded();
sendTaskResult();
WorkerTaskExecutorHolder.remove(taskExecutionContext.getTaskInstanceId());
clearTaskExecPathIfNeeded();
}
Key Logics in Explanation
1. Result Log Printing
protected LinkedBlockingQueue<String> logBuffer;
public AbstractCommandExecutor(Consumer<LinkedBlockingQueue<String>> logHandler,
TaskExecutionContext taskRequest) {
this.logHandler = logHandler;
this.taskRequest = taskRequest;
this.logBuffer = new LinkedBlockingQueue<>();
this.logBuffer.add(EMPTY_STRING);
if (this.taskRequest != null) {
// set logBufferEnable=true if the task uses logHandler and logBuffer to buffer log messages
this.taskRequest.setLogBufferEnable(true);
}
}
The logBuffer temporarily stores log messages, which are then consumed by the parseProcessOutputExecutorService thread.
Log Production Side
while ((line = inReader.readLine()) != null) {
// TODO Log buffer
logBuffer.add(line);
// TODO Parses taskOutputParams, such as parsing `echo '${setValue(output=1)}'`
// Essentially extracting the string `${setValue(output=1)}`
taskOutputParameterParser.appendParseLog(line);
}
Here, the log messages are added to logBuffer and processed for extracting specific output parameters.
Log Consumption Side
this.shellCommandExecutor = new ShellCommandExecutor(this::logHandle, taskExecutionContext);
public void logHandle(LinkedBlockingQueue<String> logs) {
StringJoiner joiner = new StringJoiner("\n\t");
while (!logs.isEmpty()) {
joiner.add(logs.poll());
}
log.info(" -> {}", joiner);
}
while (logBuffer.size() > 1 || !processLogOutputIsSuccess || !podLogOutputIsFinished) {
if (logBuffer.size() > 1) {
logHandler.accept(logBuffer);
logBuffer.clear();
logBuffer.add(EMPTY_STRING);
} else {
// TODO If there is no log output, wait for 1 second by default
Thread.sleep(TaskConstants.DEFAULT_LOG_FLUSH_INTERVAL);
}
}
-
Logs are continuously polled from
logBufferand formatted before being output. - If
logBufferhas more than one line, it is consumed and cleared, with an empty string added back. - If no new log messages are available, the system waits for one second before checking again.
Shell Task Log Output Example
Since shell task logs are prefixed with ->, a sample log output looks like this:
[INFO] 2024-06-24 09:35:44.678 +0800 - ->
.
├── 1893_1321.sh
└── input_dir
├── test1
│ └── text.txt
└── test2
└── text.txt
3 directories, 3 files
test1 message
test2 message
This ensures that all shell execution logs are formatted consistently for better readability and debugging.
2. Parsing the Variable Pool
while ((line = inReader.readLine()) != null) {
// TODO Log buffer
logBuffer.add(line);
// TODO Parses taskOutputParams, such as parsing `echo '${setValue(output=1)}'`
// Essentially extracting the string `${setValue(output=1)}`
taskOutputParameterParser.appendParseLog(line);
}
org.apache.dolphinscheduler.plugin.task.api.parser.TaskOutputParameterParser#appendParseLog
public void appendParseLog(String logLine) {
if (logLine == null) {
return;
}
// TODO Initially, this part won't execute
if (currentTaskOutputParam != null) {
if (currentTaskOutputParam.size() > maxOneParameterRows
|| currentTaskOutputParamLength > maxOneParameterLength) {
log.warn(
"The output param expression '{}' is too long, the max rows is {}, max length is {}, will skip this param",
String.join("\n", currentTaskOutputParam), maxOneParameterLength, maxOneParameterRows);
currentTaskOutputParam = null;
currentTaskOutputParamLength = 0;
return;
}
// Continue parsing the rest of the line
int i = logLine.indexOf(")}");
if (i == -1) {
// The end of the variable pool is not found
currentTaskOutputParam.add(logLine);
currentTaskOutputParamLength += logLine.length();
} else {
// The end of the variable pool is found
currentTaskOutputParam.add(logLine.substring(0, i + 2));
Pair<String, String> keyValue = parseOutputParam(String.join("\n", currentTaskOutputParam));
if (keyValue.getKey() != null && keyValue.getValue() != null) {
// TODO Once parsed, store it in `taskOutputParams`
taskOutputParams.put(keyValue.getKey(), keyValue.getValue());
}
currentTaskOutputParam = null;
currentTaskOutputParamLength = 0;
// Continue parsing the remaining part of the line
if (i + 2 != logLine.length()) {
appendParseLog(logLine.substring(i + 2));
}
}
return;
}
int indexOfVarPoolBegin = logLine.indexOf("${setValue(");
if (indexOfVarPoolBegin == -1) {
indexOfVarPoolBegin = logLine.indexOf("#{setValue(");
}
if (indexOfVarPoolBegin == -1) {
return;
}
currentTaskOutputParam = new ArrayList<>();
appendParseLog(logLine.substring(indexOfVarPoolBegin));
}
Once parsing is complete, the extracted values are stored in taskOutputParams.
Updating Process ID (Reporting to Master)
// Update process ID before waiting for execution to complete
if (null != taskCallBack) {
// TODO Update task instance information
taskCallBack.updateTaskInstanceInfo(processId);
}
Timeout Handling
long remainTime = getRemainTime();
private long getRemainTime() {
long usedTime = (System.currentTimeMillis() - taskRequest.getStartTime()) / 1000;
long remainTime = taskRequest.getTaskTimeout() - usedTime;
if (remainTime < 0) {
throw new RuntimeException("task execution time out");
}
return remainTime;
}
......
// Waiting for execution to finish
// TODO This is essentially a timeout wait; if no timeout is set, it will wait indefinitely
boolean status = this.process.waitFor(remainTime, TimeUnit.SECONDS);
If execution time exceeds the allowed limit, an exception is thrown.
Handling Exit Codes
// TODO Set exit code
// If SHELL task exits normally
if (status && kubernetesStatus.isSuccess()) {
// SHELL task exit status
result.setExitStatusCode(this.process.exitValue());
} else {
log.error("Process failed, task timeout value: {}, preparing to kill...",
taskRequest.getTaskTimeout());
result.setExitStatusCode(EXIT_CODE_FAILURE);
cancelApplication();
}
int exitCode = this.process.exitValue();
String exitLogMessage = EXIT_CODE_KILL == exitCode ? "Process has been killed." : "Process has exited.";
log.info("{} execute path:{}, processId:{} ,exitStatusCode:{} ,processWaitForStatus:{} ,processExitValue:{}",
exitLogMessage, taskRequest.getExecutePath(), processId, result.getExitStatusCode(), status, exitCode);
- If the process finishes successfully and Kubernetes reports success, the exit status is stored.
- Otherwise, the process is terminated and marked as failed.
Processing Execution Results and Output Parameters
// TODO Store exit status code
setExitStatusCode(commandExecuteResult.getExitStatusCode());
// TODO Store process ID
setProcessId(commandExecuteResult.getProcessId());
// TODO `shellCommandExecutor.getTaskOutputParams()` returns values such as `output -> 123`
shellParameters.dealOutParam(shellCommandExecutor.getTaskOutputParams());
org.apache.dolphinscheduler.plugin.task.api.parameters.AbstractParameters#dealOutParam
public void dealOutParam(Map<String, String> taskOutputParams) {
// TODO If `localParams` is empty, output parameters will not be processed
if (CollectionUtils.isEmpty(localParams)) {
return;
}
// TODO Filter out parameters where `localParams` is set to `OUT`
List<Property> outProperty = getOutProperty(localParams);
if (CollectionUtils.isEmpty(outProperty)) {
return;
}
// TODO If `taskOutputParams` is empty, store output parameters in `varPool`
if (MapUtils.isEmpty(taskOutputParams)) {
outProperty.forEach(this::addPropertyToValPool);
return;
}
// TODO Match `outProperty` with `taskOutputParams` keys and update values accordingly
// TODO Finally, store in the variable pool
for (Property info : outProperty) {
String propValue = taskOutputParams.get(info.getProp());
if (StringUtils.isNotEmpty(propValue)) {
info.setValue(propValue);
addPropertyToValPool(info);
} else {
log.warn("Cannot find the output parameter {} in the task output parameters", info.getProp());
}
}
}
-
Filters Output Parameters: Extracts parameters from
localParamsthat are marked asOUT. -
Stores in Variable Pool: If
taskOutputParamsis empty, the extracted values are placed invarPool. -
Updates Values: If
taskOutputParamscontains matching keys, it updatesoutPropertyaccordingly.
Updating the Variable Pool and Reporting to Master
At this stage, the system matches keys in outProperty and taskOutputParams, updating the corresponding values in taskOutputParams. These values are then stored in the TaskInstance variable pool before being reported to the Master.
2.5.4 Post-Execution Cleanup
protected void afterExecute() throws TaskException {
if (task == null) {
throw new TaskException("The current task instance is null");
}
// TODO Determine whether to send an alert via RPC communication using JDK dynamic proxy
// Calls the alert module `AlertBootstrapService`
sendAlertIfNeeded();
// TODO Send execution results
sendTaskResult();
WorkerTaskExecutorHolder.remove(taskExecutionContext.getTaskInstanceId());
// TODO If `development.state=false` in `common.properties` (default is false)
// TODO If set to `true`, DolphinScheduler will not delete scripts and JAR files
log.info("Remove the current task execution context from worker cache");
clearTaskExecPathIfNeeded();
}
Sending Task Execution Results
protected void sendTaskResult() {
taskExecutionContext.setCurrentExecutionStatus(task.getExitStatus());
taskExecutionContext.setProcessId(task.getProcessId());
taskExecutionContext.setAppIds(task.getAppIds());
// TODO Sending the variable pool (this is where the variable pool is transmitted)
taskExecutionContext.setVarPool(JSONUtils.toJsonString(task.getParameters().getVarPool()));
taskExecutionContext.setEndTime(System.currentTimeMillis());
// Upload output files and modify the "OUT FILE" property in the variable pool
// TODO Upload output files and update them in the variable pool
TaskFilesTransferUtils.uploadOutputFiles(taskExecutionContext, storageOperate);
log.info("Upload output files: {} successfully",
TaskFilesTransferUtils.getFileLocalParams(taskExecutionContext, Direct.OUT));
// TODO Send the task execution result
workerMessageSender.sendMessageWithRetry(taskExecutionContext,
ITaskInstanceExecutionEvent.TaskInstanceExecutionEventType.FINISH);
log.info("Send task execution status: {} to master : {}",
taskExecutionContext.getCurrentExecutionStatus().name(),
taskExecutionContext.getWorkflowInstanceHost());
}
- Set Task Status: Updates the task’s execution status, process ID, and application IDs.
-
Store Variable Pool Data: Converts the variable pool into JSON format and stores it in
taskExecutionContext. - Upload Output Files: Transfers any output files and updates their references in the variable pool.
- Report Results to Master: Sends the execution status and variable pool data to the Master node for further processing.
Shell Exit Codes: A Quick Note
[root@node opt]# vim test.sh
[root@node opt]# sh test.sh
me is journey
[root@node opt]# echo $?
0
[root@node opt]# vim test.sh
[root@node opt]# sh test.sh
test.sh: line 2: echo1: command not found
[root@node opt]# echo $?
127
[root@node opt]# vim test.sh
[root@node opt]# sh test.sh
me is 10.253.26.85
Killed
[root@node opt]# echo $?
137
Summary:
- A normal exit for a Shell task returns 0.
- If the task fails due to a missing command, the exit code is 127.
- If the process is killed, the exit code is 137.
- Any other exit codes indicate an unexpected error.
Task Status Code Determination Logic
taskExecutionContext.setCurrentExecutionStatus(task.getExitStatus());
org.apache.dolphinscheduler.plugin.task.api.AbstractTask#getExitStatus
// If the exit code is 0, the task is marked as SUCCESS;
// If the exit code is 137, it is marked as KILL;
// Any other exit code is considered FAILURE.
public TaskExecutionStatus getExitStatus() {
switch (getExitStatusCode()) {
case TaskConstants.EXIT_CODE_SUCCESS:
return TaskExecutionStatus.SUCCESS;
case TaskConstants.EXIT_CODE_KILL:
return TaskExecutionStatus.KILL;
default:
return TaskExecutionStatus.FAILURE;
}
}
This method determines the final execution status of the task based on the exit code received from the execution process.
-
Exit Code
0→ Task is successful -
Exit Code
137→ Task was killed - Any other exit code → Task failed
The exit status is set during the execution of executeTask().
Uploading Output Files to the Resource Center
org.apache.dolphinscheduler.server.worker.utils.TaskFilesTransferUtils#uploadOutputFiles
public static void uploadOutputFiles(TaskExecutionContext taskExecutionContext,
StorageOperate storageOperate) throws TaskException {
List<Property> varPools = getVarPools(taskExecutionContext);
// Create a map from varPools for quick lookup
Map<String, Property> varPoolsMap = varPools.stream().collect(Collectors.toMap(Property::getProp, x -> x));
// Get OUTPUT FILE parameters
List<Property> localParamsProperty = getFileLocalParams(taskExecutionContext, Direct.OUT);
if (localParamsProperty.isEmpty()) {
return;
}
log.info("Uploading output files ...");
for (Property property : localParamsProperty) {
// Get local file path
String path = String.format("%s/%s", taskExecutionContext.getExecutePath(), property.getValue());
// TODO `packIfDir` and `crc`:
// If the output is a directory, it will be compressed into a zip file and a CRC (checksum) is generated.
// If it is a file, only a CRC will be generated.
String srcPath = packIfDir(path);
// Get the CRC file path
String srcCRCPath = srcPath + CRC_SUFFIX;
try {
FileUtils.writeContent2File(FileUtils.getFileChecksum(path), srcCRCPath);
} catch (IOException ex) {
throw new TaskException(ex.getMessage(), ex);
}
// Get the remote file path
// TODO Storage structure:
// `DATA_TRANSFER/DATE/ProcessDefineCode/ProcessDefineVersion_ProcessInstanceID/TaskName_TaskInstanceID_FileName`
String resourcePath = getResourcePath(taskExecutionContext, new File(srcPath).getName());
String resourceCRCPath = resourcePath + CRC_SUFFIX;
try {
// Upload file to storage
// TODO For example, in HDFS:
// HDFS base path: `/tenantCode/resources/DATA_TRANSFER/DATE/ProcessDefineCode/ProcessDefineVersion_ProcessInstanceID/TaskName_TaskInstanceID_FileName`
String resourceWholePath =
storageOperate.getResourceFullName(taskExecutionContext.getTenantCode(), resourcePath);
String resourceCRCWholePath =
storageOperate.getResourceFullName(taskExecutionContext.getTenantCode(), resourceCRCPath);
log.info("{} --- Local:{} to Remote:{}", property, srcPath, resourceWholePath);
storageOperate.upload(taskExecutionContext.getTenantCode(), srcPath, resourceWholePath, false, true);
log.info("{} --- Local:{} to Remote:{}", "CRC file", srcCRCPath, resourceCRCWholePath);
storageOperate.upload(taskExecutionContext.getTenantCode(), srcCRCPath, resourceCRCWholePath, false, true);
} catch (IOException ex) {
throw new TaskException("Upload file to storage error", ex);
}
// Update varPool
Property oriProperty;
// If the property is not already in varPool, add it
if (varPoolsMap.containsKey(property.getProp())) { // This branch should theoretically never be executed
oriProperty = varPoolsMap.get(property.getProp());
} else {
oriProperty = new Property(property.getProp(), Direct.OUT, DataType.FILE, property.getValue());
// TODO Add to variable pool
varPools.add(oriProperty);
}
// TODO Assign the task name as a prefix to the property name
oriProperty.setProp(String.format("%s.%s", taskExecutionContext.getTaskName(), oriProperty.getProp()));
// TODO This is crucial: The resource's relative path is stored as the value in the variable pool
oriProperty.setValue(resourcePath);
}
// TODO Store FILE-related variables in the variable pool
taskExecutionContext.setVarPool(JSONUtils.toJsonString(varPools));
}
Breakdown of Output File Upload Process
-
Retrieve Output Files
- Extracts OUTPUT FILE parameters from the task context.
-
Check if Directory or File
- If a directory, it is compressed into a zip file, and a CRC checksum is generated.
- If a file, only the CRC checksum is generated.
-
Determine Storage Path
- The path follows a structured format:
DATA_TRANSFER/DATE/ProcessDefineCode/ProcessDefineVersion_ProcessInstanceID/TaskName_TaskInstanceID_FileName
- The storage location depends on the system (e.g., HDFS or other storage solutions).
-
Upload File and CRC Checksum
- Uploads both the file and its CRC checksum to the remote storage.
-
Update Variable Pool
- The uploaded file's relative path is stored in the variable pool, which is later sent to the Master.
Sending Task Execution Results
workerMessageSender.sendMessageWithRetry(taskExecutionContext,
ITaskInstanceExecutionEvent.TaskInstanceExecutionEventType.FINISH);
This ensures that the task execution result is reliably reported to the Master.
3. Role of the WorkerMessageSender Component

4. Task Kill Logic
org.apache.dolphinscheduler.server.worker.runner.operator.TaskInstanceKillOperationFunction#operate
public TaskInstanceKillResponse operate(TaskInstanceKillRequest taskInstanceKillRequest) {
log.info("Receive TaskInstanceKillRequest: {}", taskInstanceKillRequest);
// TODO Task Instance
int taskInstanceId = taskInstanceKillRequest.getTaskInstanceId();
try {
LogUtils.setTaskInstanceIdMDC(taskInstanceId);
// TODO Worker Task Executor
WorkerTaskExecutor workerTaskExecutor = WorkerTaskExecutorHolder.get(taskInstanceId);
if (workerTaskExecutor == null) {
log.error("Cannot find WorkerTaskExecutor for taskInstance: {}", taskInstanceId);
return TaskInstanceKillResponse.fail("Cannot find WorkerTaskExecutor");
}
// TODO Task Execution Context
TaskExecutionContext taskExecutionContext = workerTaskExecutor.getTaskExecutionContext();
LogUtils.setTaskInstanceLogFullPathMDC(taskExecutionContext.getLogPath());
// TODO Kill process execution
boolean result = doKill(taskExecutionContext);
// TODO `Process.destroy()` in Java terminates the subprocess associated with this `Process` object.
this.cancelApplication(workerTaskExecutor);
int processId = taskExecutionContext.getProcessId();
// TODO If `processId == 0`, mark the task as KILL and report it accordingly.
// TODO Note: This does not necessarily mean the process was actually killed, but ensures DS has the correct status.
if (processId == 0) {
workerManager.killTaskBeforeExecuteByInstanceId(taskInstanceId);
taskExecutionContext.setCurrentExecutionStatus(TaskExecutionStatus.KILL);
// TODO The task might have been executed, but the process ID is 0.
WorkerTaskExecutorHolder.remove(taskInstanceId);
log.info("The task has not been executed and has been cancelled, task id:{}", taskInstanceId);
return TaskInstanceKillResponse.success(taskExecutionContext);
}
// TODO If successful, Worker will detect the task was killed and report it in `sendResult FINISH`.
taskExecutionContext
.setCurrentExecutionStatus(result ? TaskExecutionStatus.SUCCESS : TaskExecutionStatus.FAILURE);
WorkerTaskExecutorHolder.remove(taskExecutionContext.getTaskInstanceId());
// TODO Remove retry messages
messageRetryRunner.removeRetryMessages(taskExecutionContext.getTaskInstanceId());
return TaskInstanceKillResponse.success(taskExecutionContext);
} finally {
LogUtils.removeTaskInstanceIdMDC();
LogUtils.removeTaskInstanceLogFullPathMDC();
}
}
Killing the Process and Yarn/Kubernetes Tasks
// TODO Kill process execution
boolean result = doKill(taskExecutionContext);
org.apache.dolphinscheduler.server.worker.runner.operator.TaskInstanceKillOperationFunction#doKill
private boolean doKill(TaskExecutionContext taskExecutionContext) {
// Kill system process
// TODO Kill the Shell-related process
boolean processFlag = killProcess(taskExecutionContext.getTenantCode(), taskExecutionContext.getProcessId());
// TODO Kill Yarn or Kubernetes application
try {
ProcessUtils.cancelApplication(taskExecutionContext);
} catch (TaskException e) {
return false;
}
return processFlag;
}
org.apache.dolphinscheduler.server.worker.runner.operator.TaskInstanceKillOperationFunction#killProcess
This function kills the main process and its child processes.
Note: Unlike the official documentation, this implementation has been modified. If an exception occurs, only a warning is logged instead of failing entirely. This is because some environments do not grant permissions to kill all processes.
Killing the Process (Including Child Processes)
killProcess(String tenantCode, Integer processId)
protected boolean killProcess(String tenantCode, Integer processId) {
// TODO Directly interrupt the process
if (processId == null || processId.equals(0)) {
return true;
}
try {
String pidsStr = ProcessUtils.getPidsStr(processId);
if (!Strings.isNullOrEmpty(pidsStr)) {
String cmd = String.format("kill -9 %s", pidsStr);
cmd = OSUtils.getSudoCmd(tenantCode, cmd);
log.info("process id:{}, cmd:{}", processId, cmd);
OSUtils.exeCmd(cmd);
}
} catch (Exception e) {
log.warn("kill task error", e);
}
return true;
}
- If
processIdis null or 0, the function returns immediately, assuming no process needs to be killed. - It retrieves the list of process IDs using
ProcessUtils.getPidsStr(processId). - If valid process IDs are found, it constructs a
kill -9command and executes it usingOSUtils.exeCmd(cmd). - Any exceptions during process termination only trigger warnings instead of causing a failure.
Killing YARN/Kubernetes Jobs
org.apache.dolphinscheduler.plugin.task.api.utils.ProcessUtils#cancelApplication
public static void cancelApplication(TaskExecutionContext taskExecutionContext) {
try {
// TODO Handle Kubernetes-based tasks
if (Objects.nonNull(taskExecutionContext.getK8sTaskExecutionContext())) {
if (!TASK_TYPE_SET_K8S.contains(taskExecutionContext.getTaskType())) {
// Set an empty container name for Spark on K8S tasks
applicationManagerMap.get(ResourceManagerType.KUBERNETES)
.killApplication(new KubernetesApplicationManagerContext(
taskExecutionContext.getK8sTaskExecutionContext(),
taskExecutionContext.getTaskAppId(), ""));
}
} else {
// TODO Handle YARN-based tasks
String host = taskExecutionContext.getHost();
String executePath = taskExecutionContext.getExecutePath();
String tenantCode = taskExecutionContext.getTenantCode();
List<String> appIds;
// TODO If failover occurred, use the stored app IDs
if (StringUtils.isNotEmpty(taskExecutionContext.getAppIds())) {
appIds = Arrays.asList(taskExecutionContext.getAppIds().split(COMMA));
} else {
String logPath = taskExecutionContext.getLogPath();
String appInfoPath = taskExecutionContext.getAppInfoPath();
if (logPath == null || appInfoPath == null || executePath == null || tenantCode == null) {
log.error("Kill YARN job error, missing required parameters: host: {}, logPath: {}, appInfoPath: {}, executePath: {}, tenantCode: {}",
host, logPath, appInfoPath, executePath, tenantCode);
throw new TaskException("Cancel application failed!");
}
log.info("Extracting appIds from worker {}, taskLogPath: {}", host, logPath);
// TODO Use regex to extract app IDs from logs
appIds = LogUtils.getAppIds(logPath, appInfoPath,
PropertyUtils.getString(APPID_COLLECT, DEFAULT_COLLECT_WAY));
taskExecutionContext.setAppIds(String.join(TaskConstants.COMMA, appIds));
}
// TODO If no appIds were found, return immediately
if (CollectionUtils.isEmpty(appIds)) {
log.info("The appId list is empty.");
return;
}
ApplicationManager applicationManager = applicationManagerMap.get(ResourceManagerType.YARN);
applicationManager.killApplication(new YarnApplicationManagerContext(executePath, tenantCode, appIds));
}
} catch (Exception e) {
log.error("Cancel application failed.", e);
}
}
Key Process for Killing YARN Jobs
-
Kubernetes Task Handling
- If the task is running on Kubernetes, it fetches the KubernetesApplicationManager and kills the corresponding container or pod.
-
YARN Task Handling
- If the task is running on YARN, it determines whether it is part of a failover scenario.
- If no
appIdsare available, it extracts them from task logs using regex parsing (LogUtils.getAppIds()). - The list of appIds is then passed to
ApplicationManager, which attempts to terminate them.
Extracting YARN App IDs from Logs
appIds = LogUtils.getAppIds(logPath, appInfoPath,
PropertyUtils.getString(APPID_COLLECT, DEFAULT_COLLECT_WAY));
public List<String> getAppIds(String logPath, String appInfoPath, String fetchWay) {
if (!StringUtils.isEmpty(fetchWay) && fetchWay.equals("aop")) {
log.info("Start finding appId in {}, fetch way: {} ", appInfoPath, fetchWay);
// TODO If using AOP-based interception, read from the app info file
return getAppIdsFromAppInfoFile(appInfoPath);
} else {
log.info("Start finding appId in {}, fetch way: {} ", logPath, fetchWay);
// TODO Extract App IDs from logs using regex
return getAppIdsFromLogFile(logPath);
}
}
- By default, app IDs are extracted from logs instead of using AOP-based interception.
- The function
getAppIdsFromLogFile(logPath)scans the log file for YARN application IDs using regular expressions.
Executing YARN Kill Command
applicationManager.killApplication(new YarnApplicationManagerContext(executePath, tenantCode, appIds));
org.apache.dolphinscheduler.plugin.task.api.am.YarnApplicationManager#killApplication
public boolean killApplication(ApplicationManagerContext applicationManagerContext) throws TaskException {
YarnApplicationManagerContext yarnApplicationManagerContext =
(YarnApplicationManagerContext) applicationManagerContext;
String executePath = yarnApplicationManagerContext.getExecutePath();
String tenantCode = yarnApplicationManagerContext.getTenantCode();
List<String> appIds = yarnApplicationManagerContext.getAppIds();
try {
String commandFile = String.format("%s/%s.kill", executePath, String.join(Constants.UNDERLINE, appIds));
String cmd = getKerberosInitCommand() + "yarn application -kill " + String.join(Constants.SPACE, appIds);
execYarnKillCommand(tenantCode, commandFile, cmd);
} catch (Exception e) {
log.warn("Kill YARN application {} failed", appIds, e);
}
return true;
}
Executing the Kill Command
private void execYarnKillCommand(String tenantCode, String commandFile, String cmd) throws Exception {
StringBuilder sb = new StringBuilder();
sb.append("#!/bin/sh\n");
sb.append("BASEDIR=$(cd `dirname $0`; pwd)\n");
sb.append("cd $BASEDIR\n");
// TODO Set the default environment source, e.g., `/etc/profile`
if (CollectionUtils.isNotEmpty(ShellUtils.ENV_SOURCE_LIST)) {
// TODO Add environment files from `ENV_SOURCE_LIST` to `systemEnvs`
ShellUtils.ENV_SOURCE_LIST.forEach(env -> sb.append("source " + env + "\n"));
}
sb.append("\n\n");
sb.append(cmd);
File f = new File(commandFile);
if (!f.exists()) {
org.apache.commons.io.FileUtils.writeStringToFile(new File(commandFile), sb.toString(),
StandardCharsets.UTF_8);
}
String runCmd = String.format("%s %s", Constants.SH, commandFile);
runCmd = org.apache.dolphinscheduler.common.utils.OSUtils.getSudoCmd(tenantCode, runCmd);
log.info("Kill command: {}", runCmd);
org.apache.dolphinscheduler.common.utils.OSUtils.exeCmd(runCmd);
}
- Constructs a shell script to execute the
yarn application -killcommand. - Ensures environment variables are correctly set before execution.
- Uses
OSUtils.exeCmd(runCmd)to execute the termination command with the required privileges.
Summary
-
If the task is running on a process (e.g., Shell, Java)
- It retrieves child process IDs and kills them using
kill -9.
- It retrieves child process IDs and kills them using
-
If the task is running on Kubernetes
- It terminates the container or pod associated with the task.
-
If the task is running on YARN
- It extracts YARN app IDs using log analysis.
- Executes
yarn application -killto terminate the job.
-
If the kill operation succeeds
- The WorkerTaskExecutor detects the termination and reports KILL status.
- If the task is already completed (
PID=0), the task context is updated, and the thread is removed.
5. Pause
public class TaskInstancePauseOperationFunction
implements
ITaskInstanceOperationFunction<TaskInstancePauseRequest, TaskInstancePauseResponse> {
@Override
public TaskInstancePauseResponse operate(TaskInstancePauseRequest taskInstancePauseRequest) {
try {
LogUtils.setTaskInstanceIdMDC(taskInstancePauseRequest.getTaskInstanceId());
log.info("Receive TaskInstancePauseRequest: {}", taskInstancePauseRequest);
log.warn("TaskInstancePauseOperationFunction is not support for worker task yet!");
return TaskInstancePauseResponse.success();
} finally {
LogUtils.removeTaskInstanceIdMDC();
}
}
}
Key points:
In fact, for a Worker, nothing happens when pausing. It’s not possible either. If you really think about it, can a task be paused? Unless the engine program has control, like MR, SPARK, and FLINK, which cannot be paused. The core logic of pausing is to send a notification to the process instance, telling the process instance that I’m going to pause the process, and let the next task running in the process pause. Of course, if there is only one task, the task cannot be paused, and it will ultimately succeed. Another case is if it is the last task, it cannot be paused. There is also the situation where the task is executing very quickly, and just when you try to pause it, the program is about to proceed, but there are no more tasks downstream. These are cases where pausing is not possible.
6. Update process instance host
This is fault tolerance, which will be explained in more detail in the fault tolerance section.

Top comments (0)