Get it? Cause we're mocking stuff? Anyway.
Write tests. Not too many. Mostly integration. - Kent C. Dodds - Guido van Rossum
Have you ever played Dungeons & Dragons? I've tried a few times but at least of the party can't seem to stay as invested as I. It sucks. I'm hoping once all this blows over I can try playing again in person. Anyway, the reason I ask is, have you ever felt like a character in a movie? How about a game? A book? A d&d campaign? Are you the dungeon master or the player? Who are you really? I'm really tired. It's only Tuesday (upon writing this first iteration) and I'm already burned out. Might be losing my mind slowly.
Anyway, on this week's campaign adventure... lab, we're experimenting with unit testing and continuous integration, a lab I've been waiting for this entire semester. I've always enjoyed the devops side a lot as I'm always tinkering with hardware or new software applications, and I've always wanted to do some software testing too, so naturally, I'm excited.
We are to integrate unit tests into our personal projects, add unit tests, add unit tests to another student's project, and finally add CI to our GitHub repo.
Naturally, the first step was to investigate testing frameworks for Python (as my project is written in Python.) I actually discovered that Python has a built in unit tests framework creatively named unittest... well, at least it's not a stupid descriptively clever yet relatable name. So I started with that, but I found the syntax and output kind of clunky so I decided to see what the new hotness was: enter Pytest. (Honestly, I chose it because some dudes on reddit told me it was great. I'm a novice student, sue me.)

I started my adventure doing the hello world of unit tests which worked out well. Then I tried to apply my learnings to my project and set up my environment, which is where I ran into some weird issues with how Python structures their directories and code. You see, Pytest likes things a certain way. Tests filenames must begin with a test_ prefix, directories must contain an __init__.py file, and tests cannot be in a directory higher than the directory you test in (e.g. tests cannot be in a folder in the source folder... which seems counter-intuitive, alas Python was as stable as Charles Manson (Once Upon a Time in Hollywood was wonderful, go watch it.)) I also had to do some weird hack which I haven't figured a work around for, as Python yelped that it could not find a library sometimes and othertimes it could. With my environment set up I set out to do some tests.
I decided to begin by writing a test for a small file loader function in my project. The function takes in two files: an HTML page containing links to check the status of, and a text file of links you don't want to check the status of in the HTML file. So I think the first test to see if this function is actually working as expected is to give it bad files to check.
def test_file_check_ignored_empty_files():
with pytest.raises(FileNotFoundError):
fio.file_check_ignored("", "")
The function prints a message and throws an error should this happen... so uh, why didn't my test show that? Turns out you actually need to call raise if you want to throw a specific error... with that fixed in my function the test now runs correctly. Awesome! Now let's make a test to ensure that the output matches, i.e. that the function actually works properly:
def test_file_check():
tested_output = '<!DOCTYPE html>\n\n<html>\n<head>\n<title>Header</title>\n<meta charset="utf-8"/>\n</head>\n<body>\n<a href="https://github.com/chrispinkney"> Working link here </a>\n<a href="https://senecacollege.ca"> However, this line (and link) should be ignored. </a>\n</body>\n</html>\n'
soup = fio.file_check("tests/test1.html")
assert str(soup) == tested_output
And here is the actual HTML we're comparing against:
<!DOCTYPE html>
<html>
<head>
<title>Header</title>
<meta charset='utf-8' />
</head>
<body>
<a href="https://github.com/chrispinkney"> Working link here </a>
<a href="https://senecacollege.ca"> However, this line (and link) should be ignored. </a>
</body>
</html>
Great! This one matches the HTML and passes, meaning the file is read properly by the function. Should anything go wrong with how files are processed, this test will let us know as there will be differences in output causing the test to fail. Now let's move onto something more interesting: mocking networking responses to ensure that a 404 response is actually read as a 404 response by the program, but first we have to learn a bit about what a fixture is, and a bit about monkies.
A fixture is kind of like an environment. A fixture would get set up prior to tests being run, as each function must be tested in a repeatable, yet identical testing environment. For example, if we're testing a function which adds a post to a website, we have to set up the environment to mimic the post being inserted into the database such that all relatable information (time posted, date, post contents, etc.) about this post can be accounted and tested for. Essentially, we have to set the world up to a specific state, then test, then return to the original state after testing. In order to properly utilize our fixture, we have to monkeypatch our test.
Monkeypatching is changing a piece of a program dynamically at run time so the conditions of the environment is reflected when testing. If a fixture is like creating a room for testing, then monkeypatching would be decorating the room so the monkey being tested has the same (and useful) experience each time. You are the monkey. Get back to work. Monkeypatching is especially useful for mimicing (mocking) external library calls. So getting back to the task at hand, how do we make our program think it's testing a website? Easily: we create an environment that simulates an unsuccessful response call (404.):
- Make a class that contains a status_code member equal to 404 (the response code we want.)
- Create a function that calls that class
- Set the response of the
.getmethod from the requests library to usemock_getinstead (this gets reset to normal after exiting the function) - Call our function normally and check if the response code is 404 (spoilers: it will be because we ordain it.)
Here's what that looks like in action:
import requests
def test_get_request_404(monkeypatch):
"""
Monkeypatches a version of hdj_linkchecker.py's single_link_check() function,
suchthat the request is always 404 for a given link.
"""
# Create a mocked object with an http status_code of 404.
class MockResponse:
def __init__(self):
self.status_code = 404
# Serve the object when called using a monkeypatch
def mock_get(url):
return MockResponse()
# Create a monkeypatch fixture
monkeypatch.setattr(requests, "get", mock_get)
assert lc.single_link_check("https://google.ca") == 404
And here's the actual function being tested:
def single_link_check(url):
req = requests.get(url)
return req.status_code
Funny how a test function ends up being 4 times longer than the actual function.
Cool, so that works. We can try to change 404 to something else, like 666, which, while being heavenly in natural, is not actually a real response code. Using 666 makes the test fail as our monkeypatch is now asserting something different than what was expected.
And now with that our of the way, time for storytime:
On a relatively clear, somewhat dark night, which was otherwise quite particular and not very ominous, a student (with a full head of hair) set out to test another function. He quickly ran into a brick wall: "WHY! Why aren't you removing links like you're supposed to??" he screamed. You see, the function had one simple job (or so he thought): take a list of links, remove a link from an html file if it matches the link, and then test whatever is left. "SO WHY AREN'T YOU REMOVING ANY LINKS? YOU WORK JUST FINE WHEN CALLED NORMALLY!" But you see, dear Humph, that he was deceived, for another function was made. In the land of Mordor Toronto, in the fires of Mount Doom Seneca College, the Dark Lord Sauron... uh wait, nevermind. There was actually another function all together which wrapped around this function and did the removal... so naturally this function would return the same output as input, all it does is return links. Not remove them. "My hubris. My greed." he thought as he cursed the fool who wrote this program. The moral of the story, you really should know how your program works.
tl;dr: If you write a function which does x and has another function that does y, write a test for x instead of blindly approaching y. Write one for y too, just make sure you're testing for the actual output and not what you think it should output.
So that was like 2 hours wasted. Could have been watching Lord of the Rings. Or looking at pretty charts.
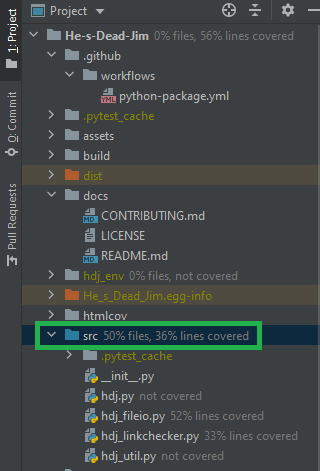
Speaking of pretty charts, let's generate a code coverage report to see how much (little?) work we've done. Surprisingly I thought that Pytest would have this built in, but rather it relies on an external library called pytest-cov, which can do some pretty neat things like exporting the report to HTML for publication later on. scribles down...
With the library now installed, I ran pytest --cov-report term-missing --cov=src tests/ to generate a coverage report on my src directory:
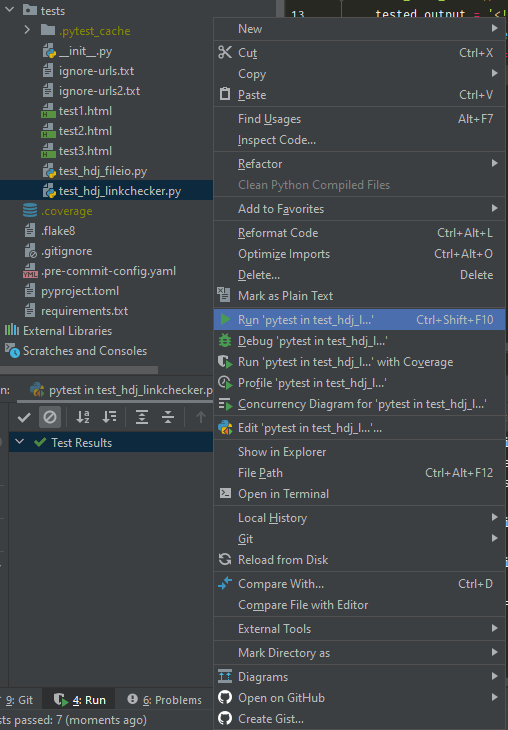
Amazingly, PyCharm has a built in coverage tool which shows you how much of your source code is covered by tests in the file explorer pane to the left (just right click on your test folder and hit Run 'pytest' in tests). I also added several project configurations to PyCharm so right clicking on any test file allows you to run it and display the output, rather than opening a console and typing pytest (though I also added a button for that, which can be toggled with shift+f10).

Cool. Now we have some tests, and a coverage report. What's next? Well, let's add a GitHub action to our repo so we can run these tests every time a pull request is made on our code.
The process was, frankly, really easy. Disappointingly easy if I'm being honest. I simply went to the Actions page on my repo and added a workflow for my Python application:
It then generated a python-package.yml file that I customized it to my liking. I specified to use only Python 3.6, 3.7, 3.8, and 3.9 as the minimum version that my project will work with is Python 3.6. I also told the action to run flake8, black, and pytest on every commit:
# This workflow will install Python dependencies, run tests and lint with a variety of Python versions
# For more information see: https://help.github.com/actions/language-and-framework-guides/using-python-with-github-actions
name: Python package
on:
push:
branches: [ master ]
pull_request:
branches: [ master ]
jobs:
build:
runs-on: ubuntu-latest
strategy:
matrix:
python-version: [3.6, 3.7, 3.8, 3.9]
steps:
- uses: actions/checkout@v2
- name: Set up Python ${{ matrix.python-version }}
uses: actions/setup-python@v2
with:
python-version: ${{ matrix.python-version }}
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install flake8 pytest
if [ -f requirements.txt ]; then pip install -r requirements.txt; fi
- name: Code Format with black
run: |
# stop the build if there are any code formatting issues
black --check .
- name: Lint with flake8
run: |
# stop the build if there are Python syntax errors or undefined names
flake8 . --count --select=E9,F63,F7,F82 --show-source --statistics
# exit-zero treats all errors as warnings. The GitHub editor is 127 chars wide
flake8 . --count --exit-zero --max-complexity=10 --max-line-length=127 --statistics
- name: Test with pytest
run: |
pytest
Then I simply pushed it to my repo, and just like magic, it worked:
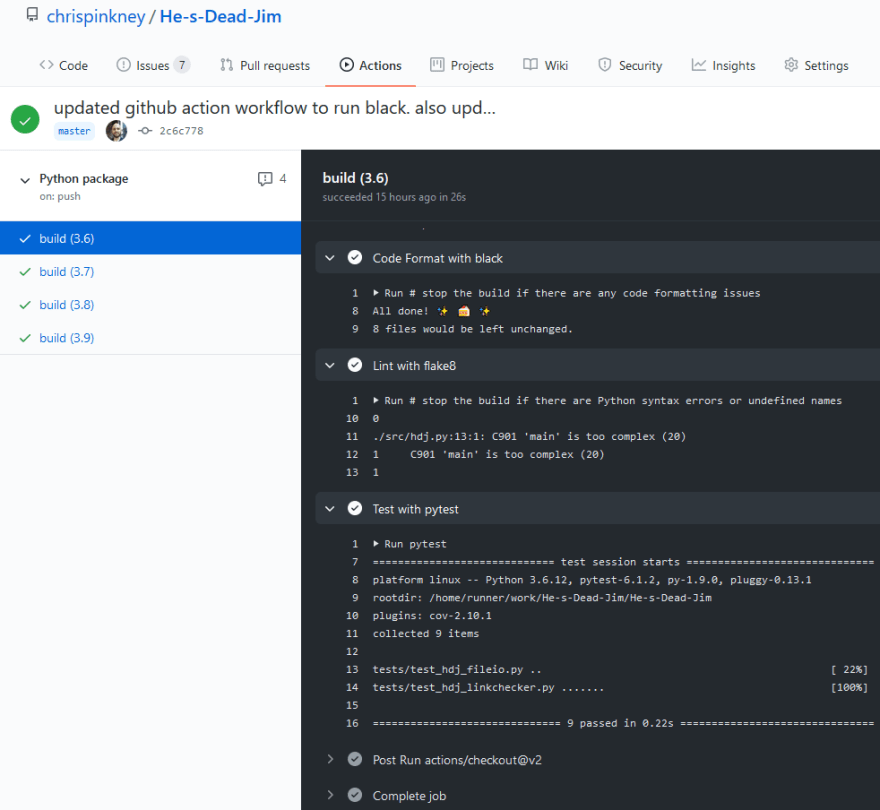
Woohoo.
I actually set this up before having any tests, which prompted me getting spammed by GitHub that all my tests were failing, haha. The reason it was failing was because I had no tests... duh. But once I did that sweet, sweet rebase, merge, commit and push, it started to run my tests and give that delicious green checkmark✔️.
With everything updated and working, my final task was to update my CONTRIBUTING.md file so that other developers will know how my project is structured, and how testing works.
With my project taken care of, it's now time to add tests to another student's project. Time to hit the ol' dusty Plamen for some more Java experience.
I wasn't too sure where to start with testing Plamen's link checker program, as it has changed a lot since he and I last worked together. After giving myself a quick refresher, I saw that a big portion of his project was not being tested (specifically, the argument parser). Since I worked on this in a previous lab I was fairly familiar with the concept of how it worked, but I did ask for a bit of a refresher.
In the class I am testing the fileArgParser and urlArgParser functions. since Plamen re-factored his code in lab 6, He has moved them to another file and changed them up a bit. Now the functions need a passed in WebDriver argument, so I figured that I needed to mock the WebDriver. I had to discuss this approach with him a bit.
It was difficult to find out how exactly to mock the WebDriver with all the properties, but I figured I just needed to pass it in with a default "mocked" properties since it was not being used in the actual logic of parsing arguments. I actually did something similar to this in my own project here. I made a quick google search of how to mock WebDriver and found this. Basically, before tests are ran the function createMocks() mocks the WebDriver:
@Before
public void createMocks() {
webdriver = mock(WebDriver.class);
}
I suggested the idea, he liked it and we tried it out together. I analyzed how exactly the mocking of WebDriver was to be done, and modeled my solution to write tests based on that. Much to my surprise, it worked flawlessly.
Now that the web driver is mocked it's only a matter of writing the actual tests to test all the branch cases for both functions I am testing. Once everything was setup it was just a matter of asserting the return flag of the functions to what each branch was actually returning. There really is not much to it beyond basic string assertions. Once that was done I made my PR.
Feels good, man. I haven't checked yet if the PR was accepted; my Java isn't great at all, so hopefully there are no issues and I did everything right.
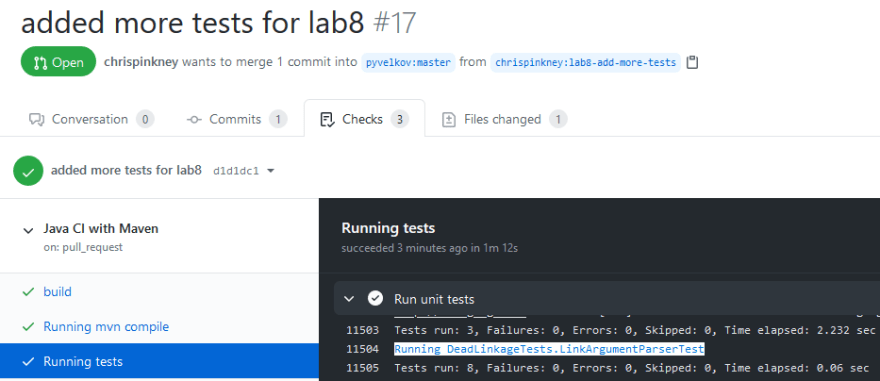
Overall, from the little testing that I've done using both Python and JavaScript, I found the Jest testing library on JavaScript to be more intuitive and easier to use, which is not to say that I hate pytest at all. It's a fine library and does everything I want it to, it just doesn't have the same feel that Jest does for me. I can't explain it. And this is coming from someone who isn't much of a JS fan. Maybe I'll have more experience one day to form an actual opinion.
Something I've always wanted to adopt in my code was a TDD method of writing code- though I have to say this lab has me finally understand why most developers don't really care for writing tests. It's complicated, cumbersome, often times clunky, and feels like a chore. I do think it's a necessary evil though, so I think it's better to adopt early this methodology as early as possible in any project. I'm looking forward to learning more about it, and writing some tests for my capstone project next semester, which will, undoubtedly, piss off my group members.
Really enjoyed this lab and I look forward to the next one.
Unrelated to schooling, I recently reached out to a developer on twitter about how I could get involved in a large emulation project. My C++ isn't great and anything lower level than that is... well, nonexistent. As is my mathematical background. I'm going to post his advice for me here in case anyone is curious:
my only advice would be to never stop being curious.
it sounds like a super canned response, but really, the reason I got into emulation was because I was very curious about how systems worked and wanted to try making things better.
When I started working on Dolphin I had basically no experience with C++, I only really had knowledge about Java and C#. When you start having fun working on stuff, whether or not you know something isn't really something to worry about; you'll gain that knowledge over time as you try and contribute to a project.
You could try reading all the C++ articles and books in the world and I'm sure you would also learn from that, but without anything to drive learning that material, it's going to be a good way to get burnt out.
In terms of contributing to projects like Dolphin, citra, or yuzu, you don't need to know everything in the world about the emulator or the system to start contributing. All it takes is an "oh, [thing] about this software can probably be improved by doing [x]", thought.
Great guy. Or gal, with some great advice. Maybe we could grab a drink one day, that'd be fun.
I also recently discovered the wonders of programming with rainy mood + lofi hip hop radio. Highly recommend it paired with a bottle of wine and a candle, so you can feel bourgeois (while writing poor code in your underwear because nobody leaves their houses anymore).
Finally, Typora is amazing for writing these blogs. Think I might just migrate from Evernote to this because Evernote somehow manages to get worse and worse as the days go by. Also highly recommend it.

Top comments (0)