YouTube's algorithm has received considerable attention in the online video communities because it can really make a struggling creator receive considerable more attention. They serve as a really interesting case study in the benefits and the challenges of a constantly changing and uploading community. (Note: The information below was gleaned from Covington, Adams, & Sargin (2016)'s paper on the mechanics of the algorithm.)
Quick detour Or: How I learned to Stop Worrying and Love Models
The quick and dirty understanding of machine learning is that we choose a specific algorithm/math equation to use for the problem to solve. We could want an algorithm to tell us how much a home costs after giving it data on similar homes or whether a medical condition is present given a data on who does or does not have the disease. It can even be used to recognize letters or faces if trained on pictures and labeled correctly.
Essentially, the algorithm creates a model using a data set to accurately predict problems in the future correctly. The key is to choose wisely what features we feed into the almighty algorithm.
Now the Good Stuff
With these details in mind, youtube's recommendation algorithm uses previous user trends and profiles to suggest new videos that the user will potentially click and watch.
A Two Step Process
To maximize the recommendation accuracy, youtube splits the bulk of their task. On the one hand, they winnow down the millions of videos on the site to a more manageable hundred or so "candidates." From here, YouTube can use significantly more video and user features (theme, search history, etc.) to calculate expected watch time
1. Collaborative Filtering
The first algorithm that YouTube uses to eliminate all the "noise" of completely unrelated videos that you don't/won't care about.
HOW??
Suppose you had a group of people that had all seen a specific movie or movies. How could we use this group to guess whether we'd like a movie they'd seen? One way is to liken our tastes to the rest of the group, and base our projected enjoyment on whether others like us enjoyed the movie too. Now what about other movies? In a similar way, we can mathematically calculate how similar movies outside our original data set are to the ones in it. This makes it so that both users and previous movies are collaboratively generating similarities between movies and users, SIMULTANEOUSLY!
In YouTube's case, it might want to know projected view time, probability to click, etc. etc.. In the same way as the movie enjoyment example, youtube will take information about your user profile and its similarity to other profiles to get videos to watch. It will also use the similarities between videos as well. But what sorts of features do they use?
"The candidate generation network only provides broad personalization via collaborative filtering. The similarity between users is expressed in terms of coarse features such as IDs of video watches, search query tokens and demographics" Covington, Adams, & Sargin (2016)
What this means is that your user profile and its history and similarity to other profiles are used to very generally recommend videos to you. Then with the help of a deep neural net to solve the most probable videos the user will watch at a specific time of watching, out pops a grouping of most likely videos to watch. This leaves the second part of the algorithm to take over.
2. Ranking
Now youtube only needs to select from a group of a few hundred and can use much more fine grained features from the group of videos and the user. This also allows youtube to suggest different videos that aren't directly comparable (e.g. Jiu Jitsu videos and Great British Bakeoff highlights). From here the fine points of the algorithm are what features of users and video content they use to suggest for watching.

But How does YouTube know which Features are Valuable?
Machine learning models live and die by how well their features accurately predict an expected output. But there's no way to measure whether the video is the right or wrong one?
"The final determination of the effectiveness of an algorithm or model, we rely on A/B testing via live experiments. In a live experiment, we can measure subtle changes in click-through rate, watch time, and many other metrics that measure user engagement" Covington, Adams, & Sargin (2016)
Essentially, youtube tweaks the algorithm in real time using experiments by measuring how much users are watching, clicking, etc. to know that their algorithm is tuned correctly. These were found to be more valuable than any of their offline measurements (e.g. accurate or precise in predicting watch-time).
Some Interesting Findings
- Video Age
An interesting factor that needs to be considered in the process of suggesting videos is age of upload.
"Machine learning systems often exhibit an implicit bias
towards the past because they are trained to predict future behavior from historical examples... To correct for this, we feed the age of the
training example as a feature during training." Covington, Adams, & Sargin (2016)
Youtube doesn't want to only suggest the same videos over and over again. Especially when their content base is changing by the second. They do this by factoring in age, giving a nice probability distribution favoring new content (shown by the model below).
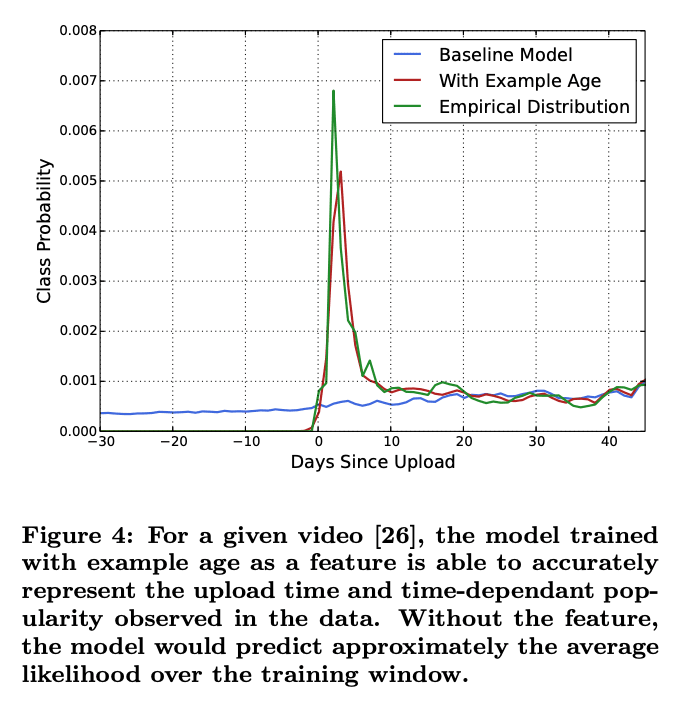
- Watch Time
" Our final ranking objective is constantly being tuned based on live A/B testing results but is generally a simple function of expected watch time per impression. Ranking by click-through rate often promotes deceptive videos that the user does not complete (“clickbait”) whereas watch time better captures engagement" Covington, Adams, & Sargin (2016)
Using watch time over clicks, views, etc. allows the data scientists to parse through videos that would be useless to the viewer. An example
A Case Study: Janelle Eliana
A YouTuber who hit a stroke of luck 3 months ago with her first video. Within one month she grew to over 1 million subscribers. That's a ton! As of now, she's posted 8 videos each averaging over a million views. How's that possible?

Vanlife is cool and all, certainly as consumable content but for Janelle to go as viral as she did requires some serious luck. Her first video had to have been similar to other videos that were popular. That way she'd be flagged for the algorithm to generate it as a candidate and finally as a a ranked. But the task is difficult here given that there is so much vanlife content, which are indistinguishable from one another.
When the algorithm hits on a particular recommendation, it is essentially connecting an audience base with a content creator. Considering all
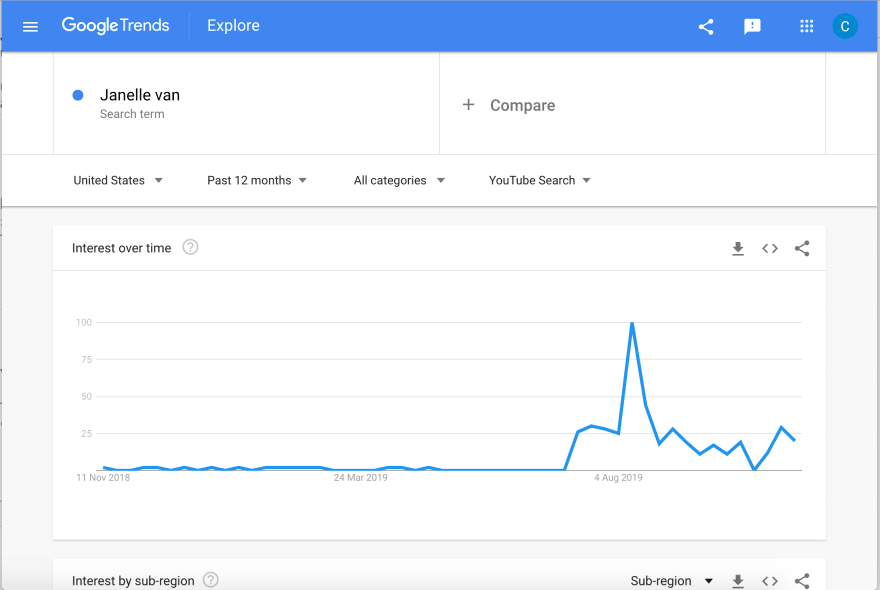
Janelle's first video premiered in July which explains the jump around shown in the graph. However, her major spike in the month of August can be seen as an example of her gaining a following of users that themselves fragmented off into allowed the algorithm to springboard off of into an even larger base. It seems like magic, nonetheless.
Ultimately, what this serves to show is that an algorithm can perpetuate itself. It seemingly chooses content to be suggested, which then feeds forward into it being suggested even further. The algorithm seems to choose itself!

Top comments (0)