When most companies search for an online SaaS solution, Service Level Agreements (SLA) play a crucial role in influencing the sale. Downtime surrounding a company’s SLA typically contain calculations around minutes of uptime for the service over some time. One sure-fire way you can provide adequate, and actionable SLA numbers are by implementing Site Reliability Engineering methodologies (SRE) and Error Budgeting.
As defined by Google:
SRE begins with the idea that a prerequisite to success is availability. A system that is unavailable cannot perform its function and will fail by default. Availability, in SRE terms, defines whether a system is able to fulfill its intended function at a point in time. In addition to being used as a reporting tool, the historical availability measurement can also describe the probability that your system will perform as expected in the future.
There are 3 tools at your disposal to help you identify and measure your SRE efforts.
SLA: The Service Level Agreement is a contract that the service provider promises customers on service availability, performance.
SLO: The Service Level Objective is a goal for a component that a service provider wants to reach. The SLO is not shared with the customer but is instead an internal goal.
SLI: The Service Level Indicator is a measurement the service provider uses for the SLO goal.(A Measurement that defines “Good Enough.” We should have enough “Good Enough” s to meet our SLO)
Utilizing an example service that provides a REST API to send out an SMS, we need to identify customers and a successful journey.
Example User and Service:
- What is my service?
The service is an API that sends an SMS.
- Who uses my service?
The users consist of businesses that like to communicate via SMS to their customers.
Example Journey:
A business user can make a REST request to our API and send an SMS to a mobile phone. The SMS should respond to, and the inbound SMS can be forwarded to a URL endpoint when received.
If I now rewrite this journey by using something measurable, I can create something that could be tracked and monitored.
Define your SLI
When a customer initiates a request to the SendSMS API endpoint, the amount of time to get a response back (response time), as measured by the time to send a response back to the customer.
Calculating SLI
When calculating reliability with your SLI, most take the approach of defining availability as:
Availability = (Number of minutes a system is working well / Total minutes) * 100
What you end up with is a fraction that defines your uptime percentage. This method of calculating reliability has some positives, but it also has some negatives. It’s straightforward for a human to understand the percentage and gauge reliability since the metric is binary. The service is up, or the service is down. The downside is that this process doesn’t work in distributed systems where multiple systems and servers are involved in contributing to this calculation.
A better approach to calculating SLI is to track events between your systems and not minutes.
Availability = (Number of good events / Total events) * 100
What happens here is that you gain some additional benefits by tracking events across servers versus tracking just time up and down. The number of servers in this scenario is irrelevant as you are measuring events that affect customers and their journey directly. This helps in situations where you use managed instance groups or preemptible machines in a cloud environment.
Define your SLO
An example SLO could be something as simple as, “99% of SMS requests return in under 300ms”. As you create the SLO, understand that this number is not static. Over time, your customers help define the true metric and decide if it needs to be adjusted upward. You should adjust your calculations to match the level of the outage. As an example, if your outage is considered degraded, multiply your error budget consumption for the incident by 0.25. If your outage is considered partial, multiply your error budget consumption for the incident by 0.5. Understanding the basics of making calculations across your infrastructure will help guide your decisions, but sometimes these calculations should be modified to meet specific goals. One example is to apply a force multiplier to specific customers that pay more for your services, or a force divider if a “bad” event occurs off-hours.
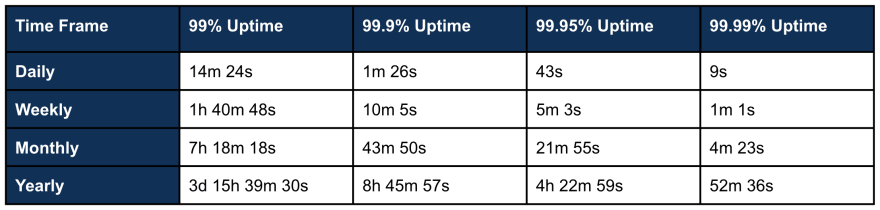
A 99% uptime allows for 14m 24s of downtime per day. This downtime is roughly 1h 40m, 7h 18m, and 3d 15h of downtime per week, month, and a year, respectively. These times calculated through your SLO target is your “Error Budget.” The error budget is your downtime, and the least allowable time you are willing to deal with lowered performance over 30 days and should be lower than your public SLA. Calculate your SLO through your various SLIs. Each time your SLI fails, and an event returns bad, you are consuming a portion of your allowed error budget.
It’s important to remember that technology services are complex, and those complex systems fail. Embracing failure is essential to growth as long as that failure in the system is understood, and effort is taken to fix the cause. Using this thought process of complexity in systems, we can say that 100% reliability does not exist. As long as you are within your budget, failure is OK. It’s important to monitor as much you can as this helps you gain insight into systems, and you can only improve upon what you measure.
If you find you are all quickly eating up your budget because a service is having problems, it’s time to re-prioritize your team to fix the budget eater. It provides guidance to stakeholders that reducing efforts on non-reliability features and refocusing on reliability features and infrastructure. One key benefit of utilizing error budgets is the reduction of paging alert fatigue for engineers. Error budgeting makes it easier to set paging alerts based on the amount of error budget consumed in X minutes versus the traditional method of paging someone every time a failure is noticed.
As you work to stay within your error budget, you will start to notice better reliability. Better reliability translates to increased uptime and an SLO that can be increased upward. Furthermore, as reliability increases, so does customer satisfaction, and this directly translates to increased revenue.
Do you have error budgeting and SRE all figured out? Try shutting down a random server or zone and see what happens.
This article was originally posted on Medium:


Top comments (0)