Original post at: https://siderite.dev/blog/using-CTE-to-solve-sudoku-in-SQL
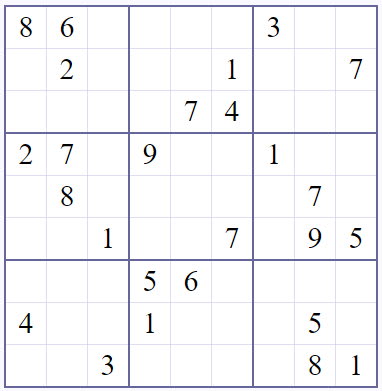 On the SQLite reference page for the WITH clause there is a little example of solving a Sudoku puzzle. Using SQL. I wanted to see it in action and therefore I've translated it into T-SQL.
On the SQLite reference page for the WITH clause there is a little example of solving a Sudoku puzzle. Using SQL. I wanted to see it in action and therefore I've translated it into T-SQL.
You might think that there is a great algorithm at play, something that will blow your mind. I mean, people have blogged about Sudoku solvers to hone their programming skills for ages and they have worked quite a lot, writing lines and lines of how clever they were. And this is SQL, it works, but how do you do something complex in it? But no, it's very simple, very straightforward and also performant. Kind of a let down, I know, but it pretty much takes all possible solutions and only selects for the valid ones using CTEs (Common Table Expressions).
Here is the translation, followed by some explanation of the code:
DECLARE @Board VARCHAR(81) = '86....3...2...1..7....74...27.9..1...8.....7...1..7.95...56....4..1...5...3....81';
WITH x(s,ind) AS
(
SELECT sud,CHARINDEX('.',sud) as ind FROM (VALUES(@Board)) as input(sud)
UNION ALL
SELECT
CONVERT(VARCHAR(81),CONCAT(SUBSTRING(s,1,ind-1),z,SUBSTRING(s,ind+1,81))) as s,
CHARINDEX('.',CONCAT(SUBSTRING(s,1,ind-1),z,SUBSTRING(s,ind+1,81))) as ind
FROM x
INNER JOIN (VALUES('1'),('2'),('3'),('4'),('5'),('6'),('7'),('8'),('9')) as digits(z)
ON NOT EXISTS (
SELECT 1
FROM (VALUES(1),(2),(3),(4),(5),(6),(7),(8),(9)) as positions(lp)
WHERE z = SUBSTRING(s, ((ind-1)/9)*9 + lp, 1)
OR z = SUBSTRING(s, ((ind-1)%9) + (lp-1)*9 + 1, 1)
OR z = SUBSTRING(s, (((ind-1)/3) % 3) * 3
+ ((ind-1)/27) * 27 + lp
+ ((lp-1) / 3) * 6, 1)
)
WHERE ind>0
)
SELECT s FROM x WHERE ind = 0
The only changes from the original code I've done is to extract the unsolved puzzle into its own variable and to change the puzzle values. Also, added a more clear INNER JOIN syntax to replace the obnoxious, but still valid, comma (aka CROSS JOIN) notation. Here is the breakdown of the algorithm, as it were:
- start with an initial state of the unsolved puzzle as a VARCHAR(81) string and the first index of a dot in that string, representing an empty slot - this is the anchor part
- for the recursive member, join the current state with all the possible digit values (1 through 9) and return the strings with the first empty slot replaced by all valid possibilities and the position of the next empty slot
- stop when there are no more empty slots
- select the solutions (no empty slots)
It's that simple. And before you imagine it will generate a huge table in memory or that it will take a huge time, worry not. It takes less than a second (a lot less) to find the solution. Obviously, resource use increases exponentially when the puzzle doesn't have just one solution. If you empty the first slot (. instead of 8) the number of rows is 10 and it takes a second to compute them all. Empty the next slot, too (6) and you get 228 solutions in 26 seconds and so on.
 The magical parts are the recursive Common Table Expression itself and the little piece of code that checks for validity, but the validity check is quite obvious as it is the exact translation of the Sudoku rules: no same digits on lines, rows or square sections.
The magical parts are the recursive Common Table Expression itself and the little piece of code that checks for validity, but the validity check is quite obvious as it is the exact translation of the Sudoku rules: no same digits on lines, rows or square sections.
A recursive CTE has three parts:
- an initial query that represents the starting state, often called the anchor member
- a recursive query that references the CTE itself, called the recursive member, which is UNIONed with the anchor
- a termination condition, to tell SQL when to end the recursion
For us, we started with one unsolved solution, we recursed on all possible valid solutions for replacing the first empty slot and we stopped when there were no more empty slots.
CTEs are often confusing because the notation seems to indicate something else to a procedural programmer. You imagine doing this without CTEs, maybe in an object oriented programming language, and you think of this huge buffer that just keeps increasing and you have to remember where you left off so you don't process the same partial solution multiple times and you have to clean the data structure so it doesn't get too large, etc. SQL, though, is at heart a declarative programming language, very close to functional programming. It will take care not only of the recursion, but also filter the rows by the final condition of no empty slots while (and sometimes before) it makes the computations.
Once you consider the set of possible solutions for a problem as a working set, SQL can do wonders to find the solution, provided you can encode it in a way the SQL engine will understand. This is just another example of the right tool for the right job. Hope you learned something.

Top comments (0)