](https://res.cloudinary.com/practicaldev/image/fetch/s--L6kC5NKx--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1.medium.com/max/2560/1%2ACEwJ9Ai7LEytGq-tPmMafg.jpeg)
Originally published at Medium on
Microsoft announced ML.NET last May, and as an advocate user of the .NET framework with experience in Machine Learning, I knew that I’d have to give it a try knowingly that Python various frameworks (such as scikit-learn) rule this domain.
ML.NET is a free, cross-platform, open source machine learning framework explicitly made for .NET developers. The preview release includes learners to handle binary classification, multi-class classification, and regression tasks. Additional ML tasks like a recommendation system, clustering, anomaly detection, ranking models, and deep learning architectures have been added.
In this blog-post, my purpose is to play along with ML.NET capabilities and eventually demonstrating its ease of use. My goal is to predict a heart disease for a given patient based on an opensource dataset.

Getting started
Assuming Visual Studio 2017 is installed on your system, open a new console application (.NET core) project:
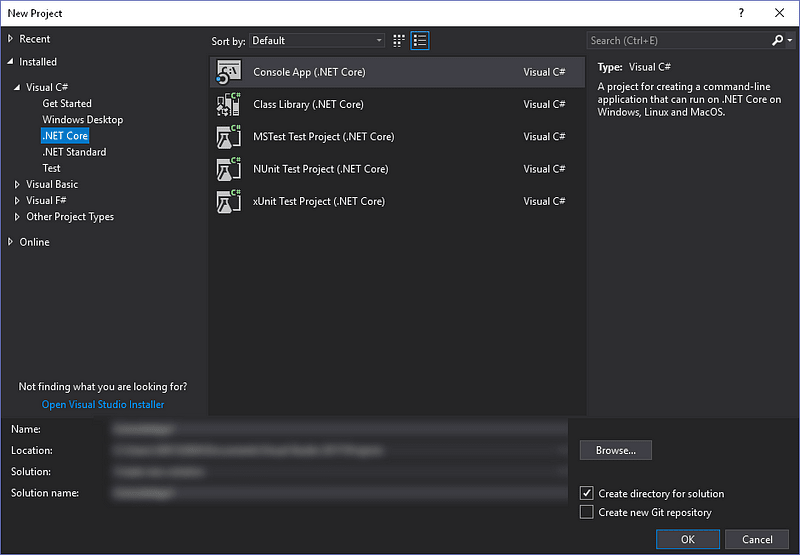
Afterward, go to the ‘Tools’ menu and choose ‘Manage NuGet Packages for Solution…’:
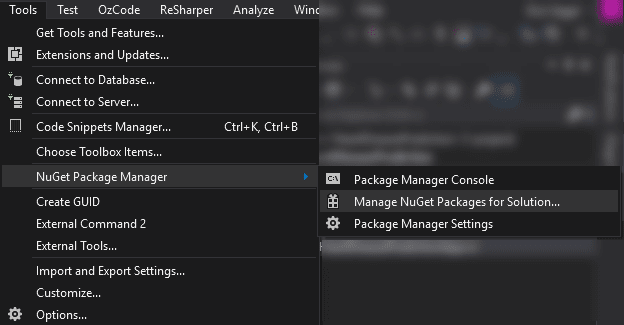
There, browse for ‘Microsoft.ML’ and choose the latest stable version (at the time of writing these lines, the stable version is 0.11.0) to install it for the current solution. As a side note, if you prefer using the package manager console, just run the following command:
Install-Package Microsoft.ML -Version 0.11.0
Now that all prerequisites are in place, we can start doing some machine learning magic.
The Heart Disease Dataset
For the binary classification task, I used the Heart Disease UCI dataset from Kaggle datasets; It contains 14 columns and 303 records.

Heart Disease Dataset Columns (screenshot is taken from Kaggle)
I’ve manually split the CSV file into two files, smaller one for the test data and a larger one for the training data. Below, the test data CSV as an example.
Test Data CSV
ML.NET provides mapping attributes to model the dataset structure. It means each header is mapped to a LoadColumn attribute as follows:
Training the model
Training a model based on a given dataset requires to define a context as an entry point or as defined by ML.NET API:
The MLContext is a starting point for all ML.NET operations. It is instantiated by the user, provides mechanisms for logging and entry points for training, prediction, model operations, etc.
Afterward, the training and test datasets are loaded using the context, based on the mapped structure.
Transform the data and add a learning algorithm for this task numeric values are assigned to text because only numbers can be processed during model training. In this case, the problem I try to predict is a type of Binary Classification (two classes, has and hasn’t diseased). The selected model is based on Decision Trees because they can be easily interpreted (by humans) as rules, have excellent performance and don’t require any assumptions on the data.
Eventually, the model is trained by using the fit method:
We’ve trained our model with a few steps, as simple as that.
BTW, the framework provides capabilities for saving your model. According to the tutorial it is recommended to save it as a ZIP file.
Testing
Given the trained model, prediction can be made.
For that purpose, a sample class containing a list of patients is given as input to the model for prediction.
The result prediction structure shall be defined too, as follows:
In the below gist, I load the model from disk, create a prediction engine based on the resulting structure (defined above) and using the engine I predict the probability for heart disease on the list of patients.
Which returns the following (Prediction Output):
In terms of the result accuracy, the code hits 78.95% accuracy, below are more evaluation parameters generated by the model’s Evaluate method:
Overall, ML.NET has it all, flexible, robust and supported by a big company that provides the engineering vision behind it. I recommend you to try it too, and for sure I’ll use it again soon.
This blog-post was written based on the Heart disease Classification coding sample with some modification; more ML.NET Samples can be found at:

Top comments (0)