
Query optimization is an expensive process that needs to explore multiple alternative ways to execute the query. The query optimization problem is NP-hard, and the number of possible plans grows exponentially with the query's complexity. For example, a typical TPC-H query may have up to several thousand possible join orders, 2-3 algorithms per join, a couple of access methods per table, some filter/aggregate pushdown alternatives, etc. Combined, this could quickly explode the search space to millions of alternative plans.
This blog post will discuss memoization - an important technique that allows cost-based optimizers to consider billions of alternative plans in a reasonable time.
The Naïve Approach
Consider that we are designing a rule-based optimizer. We want to apply a rule to a relational operator tree and produce another tree. If we insert a new operator in the middle of the tree, we need to update the parent to point to the new operator. Once we've changed the parent, we may need to change the parent of the parent, etc. If your operators are immutable by design or used by other parts of the program, you may need to copy large parts of the tree to create a new plan.
This approach is wasteful because you need to propagate changes to parents over and over again.
Indirection
We may solve the problem with change propagation by applying an additional layer of indirection. Let us introduce a new surrogate operator that will store a reference to a child operator. Before starting the optimization, we may traverse the initial relational tree and create copy of operators, where all concrete inputs are replaced with references.
When applying a transformation, we may only change a reference without updating other parts of the tree. When the optimization is over, we remove the references and reconstruct the final tree.

You may find a similar design in many production-grade heuristic optimizers. In our previous blog post about Presto, we discussed the Memo class that manages such references. In Apache Calcite, the heuristic optimizer HepPlanner models node references through the class HepRelVertex.
We realized how references might help us minimize change propagation overhead. But in a cost-based optimization, we need to consider multiple alternative plans at the same time. We need to go deeper.
MEMO
In cost-based optimization, we need to generate multiple equivalent operators, link them together, and find the cheapest path to the root.
Two relational operators are equivalent if they generate the same result set on every legal database instance. How can we encode equivalent operators efficiently? Let's extend our references to point to multiple operators! We will refer to such a surrogate node as a group, which is a collection of equivalent operators.
We start the optimization by creating equivalence groups for existing operators and replacing concrete inputs with relevant groups. At this point, the process is similar to our previous approach with references.
When a rule is applied to operator A, and a new equivalent operator B is produced, we add B to A's equivalence group. The collection of groups that we consider during optimization is called MEMO. The process of maintaining a MEMO is called memoization.
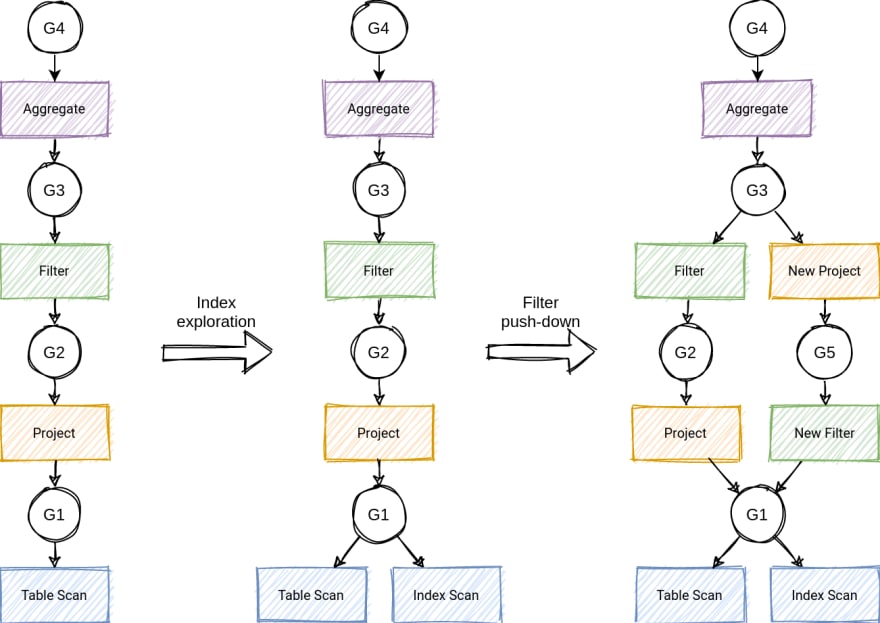
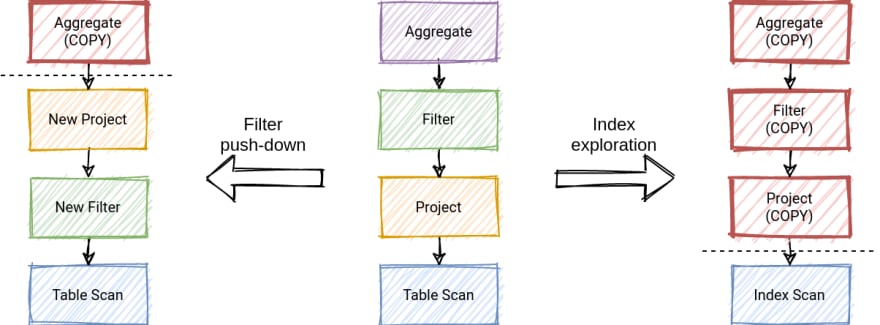
MEMO is a variation of the AND/OR graph. Operators are AND-nodes representing the subgoals of the query (e.g., applying a filter). Groups are OR-nodes, representing the alternative subgoals that could be used to achieve the parent goal (e.g., do a table scan or an index scan).
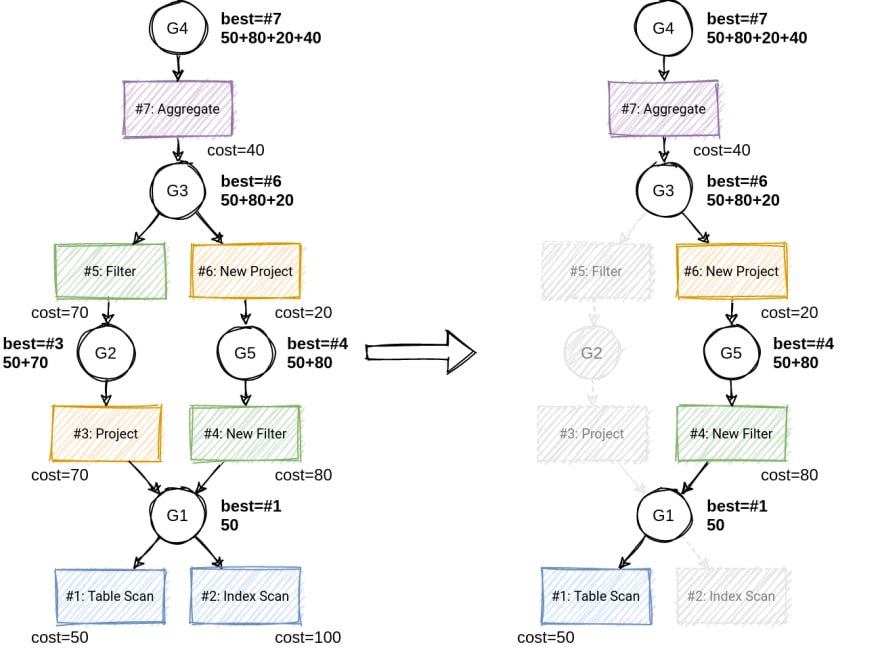
When all interesting operators are generated, the MEMO is said to be explored. We now need to extract the cheapest plan from it, which is the ultimate goal of cost-based optimization. To do this, we first assign costs to individual operators via the cost function. Then we traverse the graph bottom-up and select the cheapest operator from each group (often referred to as "winner"), combining costs of individual operators with costs of their inputs.
Practical optimizers often maintain groups' winners up-to-date during the optimization to allow for search space pruning, which we will discuss in future blog posts.

When the root group's cheapest operator is resolved, we construct the final plan through a top-down traverse across every group's cheapest operators.
Memoization is very efficient because it allows for the deduplication of nodes, eliminating unnecessary work. Consider a query that has five joins. The total number of unique join orders for such a query is 30240. If we decide to create a new plan for every join order, we would need to instantiate 30240 * 5 = 151200 join operators. With memoization, you only need 602 join operators to encode the same search space - a dramatic improvement!
The memoization idea is simple. Practical implementations of MEMO are much more involved. You need to design operator equivalence carefully, decide how to do the deduplication, manage the operator's physical properties (such as sort order), track already executed optimization rules, etc. We will cover some of these topics in future blog posts.
Summary
Memoization is an efficient technique that allows you to encode the large search space in a very compact form and eliminate duplicate work. MEMO data structure routinely backs modern cost-based rule-based optimizers.
In future posts, we will discuss the design of MEMO in practical cost-based optimizers. Stay tuned!
We are always ready to help you with your query optimizer design. Just let us know.

Top comments (0)