Reproducibility is a pillar in science, and version control via git has been a blessing to it. For pure Software Engineering it works perfectly. However, machine learning projects are not just only about code, but rather also about the data. The same model trained with two distinct data sets can produce completely different results.
So it comes with no surprise when I stumble with csv files on git repos of data teams, as they struggle to keep track of code and metadata. However this cannot be done for today's enormous datasets. I have seen several hacks to solve this problem, none of them bullet proof. This post is not about those hacks, rather about an open source solution for it: DVC.
Let us exemplify by using a kaggle challenge: predicting house prices with Advanced Regression Techniques
Now clone the repo:
git clone git@github.com:diogoaurelio/kaggle-house-prices.git
cd kaggle-house-prices
In this post we be needing several python packages - such as dvc, boto3, and machine learning related packages - so we are going to exemplify how to configure a local anaconda and install all dependencies required for this tutorial:
conda install -n kaggle python=3.6 -y
source activate kaggle
pip install -r pip_requirements.txt
conda install -c conda-forge --file conda_requirements.txt
Alternatively, if you just want to install DVC, you can do, for example, also via pip:
pip install dvc
Coming back to the git repository, you will notice that there is a directory named ".dvc".
.dvc/
├── cache
└── config
1 directory, 1 file
This was created when I locally ran the command "dvc init", which is meant to be abstracted away from the user (as the dot in the directory name would suggest).
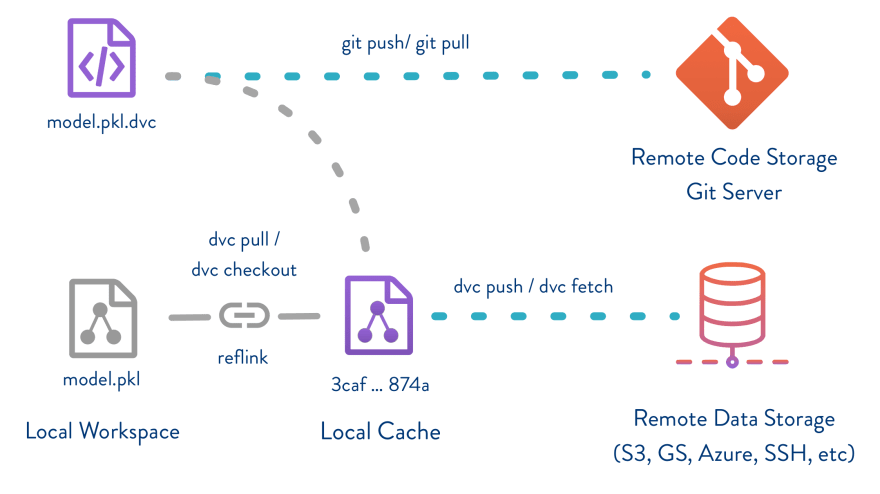
Now comes the interesting part. DVC has the concept of a remote data store, which is used to share and version data. Currently in practice can be of six types: local directory, AWS S3, Google Cloud Storage, Azure Blob Storage, SSH, or HDFS. To configure a remote data store simply map a local directory to the remote data store. In this case I mapped the "data" directory - which is git ignored - to the remote store as follows:
dvc remote add -d data s3://kaggle-datasets-store/house-prices
Next let us download data from kaggle house prices competition into the "data" directory, such as the "train.csv". You can also download from the terminal using the following command:
kaggle competitions download -c house-prices-advanced-regression-techniques
Now let us add it to our data versioned store:
dvc add data/train.csv
# you should see an output similar to the following:
Adding 'data/train.csv' to 'data/.gitignore'.
Saving 'data/train.csv' to cache '.dvc/cache'.
Created 'hardlink': .dvc/cache/80/ccab65fb115cbad143dbbd2bcd5577 -> data/train.csv
Saving information to 'data/train.csv.dvc'.
As you can see in the standard output, this command will generate a "train.csv.dvc" file, which contains a metadata about our "train.csv" file. Essentially a md5 hash of a pointer to the file.
To push this data into S3 is simple:
dvc push -r data
Note that I am specifying the "data" repository. If you want to check out dvc configuration, just have a look at .dvc/config file. You will notice that I have a AWS profile configured, which matches my local aws CLI credentials file. Here is how you can configure your local aws credentials to access S3 bucket:
aws configure
This will prompt you for the credentials plus default region and output format, and store them in "~/.aws/config" and "~/.aws/credentials". If you would like to have credentials for multiple AWS accounts, then aws cli allows you to configure "profiles" to store these. Simply do as follows:
aws configure --profile
If you look at my ".dvc/config" you will notice that I have configured my AWS profile with alias "diogo" for my own AWS account.
I did not find documentation how to explicitly do this configuration, so in case you are wondering which other configurations you can change, you can do as I did and just have a look at the DVC source code.
After pushing the data to S3 you will be able to share it with other colleagues. They simply need to run:
dvc pull
Note that in our case you will not be able to download from my S3 bucket, as it is not configured for public access, which will also be the same case for your company data.
Let us now tie everything together, namely our models with the data. For this I used the code from a python notebook using XGBoost from DanB. DVC has the run command, in which you are able to specify which dependencies as well as required outputs. In our case:
dvc run -d data/train.csv --file xgboost_base_model.dvc -O data/xgboost_base.pkl python src/xgboost_base.py
This will create a file named "xgboost_base_model.dvc" containing something similar to:
cmd: python src/xgboost_base.py
deps:
- md5: 80ccab65fb115cbad143dbbd2bcd5577
path: data/train.csv
md5: e10b323ae9bb3887626a7dc97d6a64d6
outs:
- cache: false
md5: d53d8021c4c362b88da61c347af52196
path: data/xgboost_base.pkl
Note that this dvc file contains a hash of both our "xgboost_base.py" script, along with a hash of the data. Now the beauty of this is that we can now simply "dvc repro xgboost_base_model.dvc" and it will detect if either the data or the script have changed. If no change has occured, then it will simply output: "Pipeline is up to date. Nothing to reproduce."
After having completed this, we would now be ready to add all our code to .git, including "dvc repro xgboost_base_model.dvc". This allows other people to also be able to reproduce the same results.
This example was fairly simple. However more interesting is chaining dvc run command with several steps in order to build pipelines - a multi-stage operations that define your full Machine Learning process. We strongly encourage you to have a look at DVC's own tutorial about pipelines.

Top comments (0)