
Let's build an email extractor application in AWS!
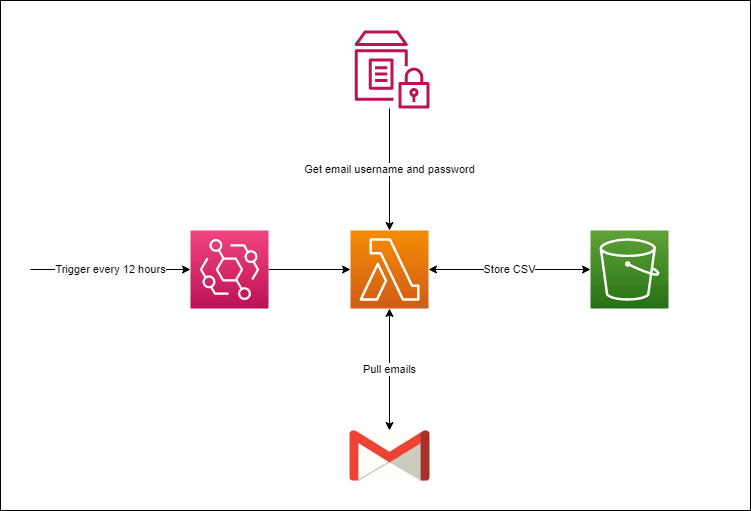
Our goal is to extract emails from our Google Mail and store the data (e.g. Email ID, Subject, Date, etc.) in a CSV file for further processing. This application will be executed every 12 hours.
Setup our Google Mail Account
Let's secure our access in our google mail account. First, we need to generate an App Password for our application, we will then use this generated key for login instead of using our usual google mail password.
Create a Lambda function
Authentication
We'll use the imaplib library to help with the connection and authentication in our google mail account. Using the imaplib IMAP4_SSL, we can established a SSL connectivity with gmail imap url imap.gmail.com, we can then pass the our email and the generated app password for our login.
imap = imaplib.IMAP4_SSL('imap.gmail.com')
try:
imap.login(email_username, email_pwd)
except Exception as e:
print(f"Unable to login due to {e}")
else:
print("Login successfully")
Extract
After authentication, we can now extract the email data. For this, I selected my Inbox and get all the email id's and iterate through them one by one.
imap.select('inbox')
data = imap.search(None, 'ALL')
mail_ids = data[1]
id_list = mail_ids[0].split()
first_email_id = int(id_list[0])
latest_email_id = int(id_list[-1])
for email_ids in range(latest_email_id, first_email_id, -1):
raw_data = imap.fetch(str(email_ids), '(RFC822)' )
for response_part in raw_data:
arr = response_part[0]
if isinstance(arr, tuple):
msg = email.message_from_string(str(arr[1],'utf-8'))
email_subject = msg['subject']
email_from = msg['from']
email_date = msg['Date']
You noticed that we split the mail id's because we need to remove a character so we can easily iterate through them. Google mail id's are incremental numbers, the lowest number is the oldest mail and the highest number will be the most recent mail in your mailbox.
Store
At this point we're able to extract the needed details from our emails, we're now ready to store them. For this, we're gonna use the CSV library that is included in Python standard library to easily manage our data's inside a .csv file.
with open('/tmp/<your_file>.csv', 'a', newline='') as file:
writer = csv.writer(file)
writer.writerow([email_ids, email_from, email_subject, email_date])
Transformation
Our lambda function has a /tmp directory for temporary storage of our data. Let's use this as a storage for our extracted data and transform the data using the power of Pandas Library before uploading it to S3.
Note:
/tmpis a512MBstorage in our Lambda function. This directory will not be wiped after each invocation it actually preserve itself for 30 minutes or so .. to anticipate any subsequent invocations.
Upload
Let's now upload our .csv file to our S3 Bucket.
try:
response = s3_client.upload_file("/tmp/<your_file>.csv", s3_bucket, "<file_name_in_s3>")
except Exception as e:
print(f"Unable to upload to s3, ERROR: {e}")
else:
print("Uploaded file to s3")
Control Flow
Let's add a control flow to determine whether we're inserting a whole new data initially or just need to append the most recent data on our .csv file because after all, this process is scheduled to execute every 12 hours.
If our .csv file does not exists in our AWS S3 Bucket then we'll extract all of the existing emails in our account. We can use the boto3 library to interact with AWS resources.
If it does exists, we can just append the new emails in our data.
What if there's no new email received? Let's then compare the latest_email_id from our gmail and the latest_email_id from our .csv file, also using these variables we can substitute them in our Extract code to control the range of email data that we're gonna extract and append in our .csv file.
try:
s3_resource.Object(s3_bucket, 'emails.csv').load()
except botocore.exceptions.ClientError as e:
if e.response['Error']['Code'] == "404":
# The object does not exist.
print("Excel file not found.. Initial Insert")
#create csv
create_csv()
#insert initial values
initial_insert(imap, latest_email_id, first_email_id)
#store to s3
else:
#compare
if latest_email_id != last_email_id_from_csv:
#append data
update_insert(imap, last_email_id_from_csv, latest_email_id)
else:
#dont append anything
print("Nothing is inserted")
That's it! You can now view your .csv file on your S3 Bucket.
Schedule Actions
Let's leverage AWS EventsBridge and configure it to execute our Lambda function every 12 hours.
Deployment and Security
I created all of the resources using an AWS Cloudformation template and use it's Paremeters section to provide email and app generated password and store them in AWS SSM Parameter Store.
Overall, here's the diagram of our application.
If you happen encountered some issues, just hit me up in the comments.
You'll see the full implementation and codebase in my repository
You can reach me at:

Top comments (0)