
Building an application is never been easy, you need to consider a lot of aspects for it to be suitable for your business or for your specific use cases. In order for the applications deliver a value they need to have a well-defined plans and sturdy foundations that you can hold onto when things go wrong.
The AWS Well-Architected Framework is a set of guidelines that will let you know what strategies are appropriate for you or for your business in order to build a secure, long-running, high-performance, resilient, and efficient infrastructure.
AWS Well-Architected Framework has its well-known 5 Pillars that you can balance or make trade-offs base on your business constraints. These are:
- Operational Excellence
- Cost Optimization
- Reliability
- Performance Efficiency
- Security
In this part, let's dive deeper in the Operational Excellence realm to gain knowledge on what are the key areas, what questions you must conquer and what are the key phases involve in this pillar for us to satisfy it's standards.
Operational Excellence
... is the ability to run systems and gain insight into their operations in order to deliver business value, and to continuously improve supporting processes and procedures.
In other words, does your architecture work? Will it continue to?
To satisfy this pillar, your architecture needs to meet these key areas:
- All operations are code
- Documentations is updated automatically
- Make smaller changes so you can roll back
- Iterate a lot
- Expect things to go sideways
- Learn from failure and success
Phases
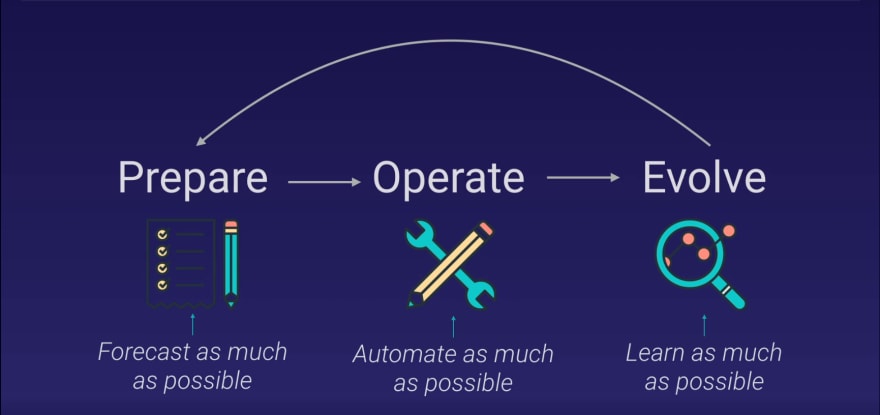
Prepare - Prioritize
You must prioritize your objectives align with business priorities:
- What is the business goal?
- What are the critical pieces need to meet that goal?
- Any compliance restrictions/requirements?
- Map up dependencies between services?
Prepare - Design
You must design your architecture to support business priorites:
- Is the design observable?
- Is the entire design code?
- Are your logs & observations actionable?
Prepare - Readiness
Is your workload ready to go live?
- Are your processes consistent?
- Is operational code properly managed?
- Are tests in place?
- Always anticipate failure
Operate - Operational Health
Ensure your workload is actually working.
- Metrics should indicate health of each service
- Metrics must show overall health
- Are you monitoring business metrics too?
Operate - Responding to Events
Shit Happens. Be Ready
- Anticipate planned and unplanned events
- Respond in code
- Connect observations with 3rd party tools as needed
- Automate everything
Evolve
Learn from success and failures.
- Post-event, have run books changed?
- Are teams evaluating their processes?
- Test assumptions
- Experiment early and often to find better solutions
The key takeaways in this pillar is "Everything is Operations: Operations are no longer an isolate discipline"
Operations is the whole shooting match and because of this I remember a tweet from @acloudguru several days ago.

Follow or Connect with me:

Top comments (0)