| Menu | Next Post: Elastic Data Frame - Classification vs Regression |
Unlike the Anomaly Detection models, this is a multi-variate analysis, it enables a better understanding of complex behaviors that are described by many features. For this analysis we have 3 models with different algorithms and learning types (Outlier, Regression and Classification) and in this post we'll talk about Classification Analysis.
Classification predicts the class or category of a given data point in a data set (Supervised ML).

In regression the goal is to have our prediction close to the actual value. In classification the goal is to be correct (and heavily penalize incorrect predictions).
Evaluation of the Classification analysis
The algorithms we are using for Classification are Boosted Tree and Logistic Function.
A Logistic function can be fit to the data using a cross-entropy cost function, which essentially computes a measure of dissimilarity between the true (observed) probabilities and our model of the probabilities. The goal is to make the model output be as close as possible to the desired output (true classes).
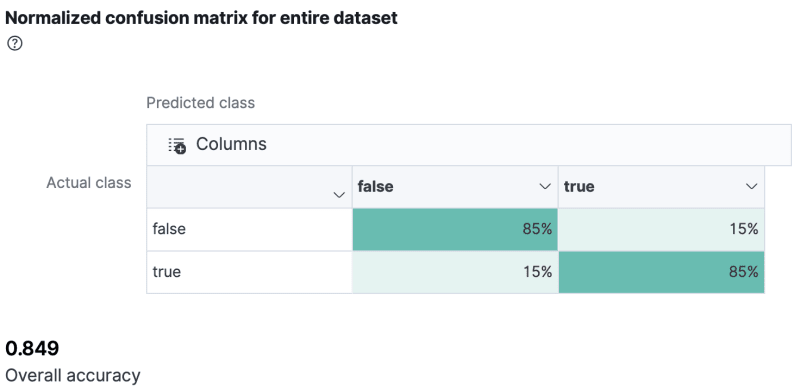
Kibana provides a normalized confusion matrix that contains the percentage of occurrences where the analysis classified data points correctly with their actual class, for example, TP and TN in the image below are good results when they have a higher percentage than FN and FP because this means that the prediction of "true and false" was correct, corresponding to the real value, in most cases. The higher the percentage in this case, the better.

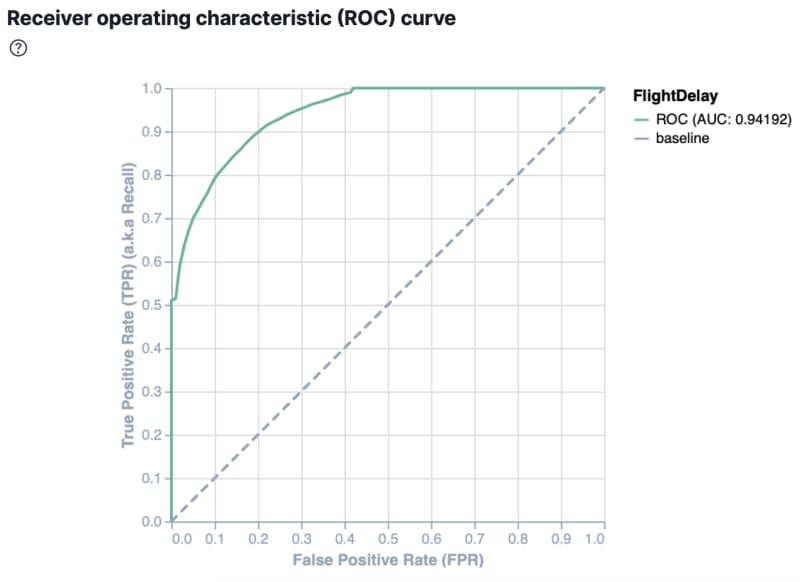
Kibana also provides the receiver operating characteristic (ROC) curve as part of the model evaluation. The plot compares the true positive rate (y-axis) to the false positive rate (x-axis) for each class; in this example, true and false. It is a number between 0 and 1. The higher the AUC, the better the model is at predicting the classes correctly.
| Menu | Next Post: Elastic Data Frame - Classification vs Regression |
This post is part of a series that covers Artificial Intelligence with a focus on Elastic's (Creators of Elasticsearch) Machine Learning solution, aiming to introduce and exemplify the possibilities and options available, in addition to addressing the context and usability.

Top comments (0)