Introduction
Running large language models (LLMs) locally has become increasingly accessible, thanks to advancements in hardware and model optimization. For .NET programmers, understanding the performance differences between CPUs and GPUs is crucial to selecting the best setup for their use case.
In this blog post, we’ll explore these differences by benchmarking the Llama 3.2 Vision model using a locally hosted environment with ollama running in docker.
Watch the Video Tutorial
Before diving in, check out the video tutorial for a quick overview of the process and key concepts covered in this blog post.

Goal of the Comparison
The goal of this exercise is to evaluate:
- Execution Time : How fast can the model process queries on CPU vs GPU?
- Resource Utilization : How do hardware resources (memory, power) compare between the two setups?
- Suitability : Which setup is better for different programming tasks?
By the end, you’ll have a clear understanding of the trade-offs and be equipped to choose the most appropriate setup for your projects.
How to Run the Test Using the Sample Code
1. Setup
Start by cloning the sample GitHub repository:
git clone https://github.com/elbruno/Ollama-llama3.2-vision-Benchmark
cd Ollama-llama3.2-vision-Benchmark
Ensure you have the necessary dependencies installed:
For .NET > Install .NET SDK
2. Model Download
- Install Docker.
- Run the Docker container for GPU and CPU:
- GPU running on port 11434 (default)
-
docker run -d –gpus=all -v ollama:/root/.ollama -p 11434:11434 –name ollama ollama/ollama
CPU running on port 11435
-
docker run -d -v ollamacpu:/root/.ollamacpu -p 11435:11434 –name ollamacpu ollama/ollama
- On each container pull the llama3.2-vision image. Run the command ollama run llama3.2-vision
- You will have docker running 2 instances of ollama, similar to this image:
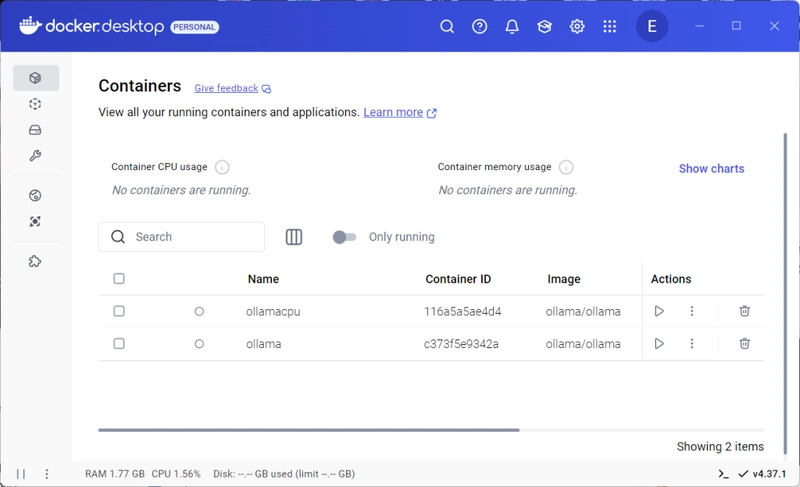
3. Run Code
For benchmarking, we are using BenchmarkDotNet for .NET.
Open the OllamaBenchmark.sln and run the solution.
4. Results Analysis
The .NET solution will output detailed performance metrics, including execution time and resource usage. Compare these metrics to identify the strengths of each hardware setup.
Conclusions
- Performance : GPUs consistently outperform CPUs in execution time for LLMs, especially for larger models like Llama 3.2 Vision.
- Resource Efficiency : While GPUs are faster, they consume more power. CPUs, on the other hand, are more energy-efficient but slower.
-
Use Cases :
- CPU : Best for lightweight, cost-sensitive tasks or development environments.
- GPU : Ideal for production workloads requiring high throughput or real-time inference.
Running benchmarks is a straightforward way to determine the best hardware for your specific needs. By following the steps outlined here, you can confidently experiment with LLMs and optimize your local environment for maximum efficiency.
For a detailed walkthrough, check out the video tutorial.
Happy coding!
Greetings
El Bruno
More posts in my blog ElBruno.com.
More info in https://beacons.ai/elbruno

Top comments (0)