
Background
OpenMLDB is an open-source high-performance in-memory SQL database with numerous innovations and optimizations particularly tailored for time-series data storage, real-time feature computation, and other advanced functionalities. On the other hand, Redis is the most popular in-memory storage database widely used in high-performance online scenarios such as caching. While their respective application landscapes differ, both databases share a common trait of utilizing memory as their storage medium.
The objective of this article is to perform a comparative analysis of memory consumption under identical data row counts for both databases. Our goal is to provide users with a clear and intuitive understanding of the respective memory resource consumptions of each database.
Test Environment
This test is based on physical machine deployment (40C250G * 3) with the following hardware specifications:
- CPU: Intel(R) Xeon(R) CPU E5–2630 v4 @ 2.20GHz
- Processor: 40 Cores
- Memory: 250 G
- Storage: HDD 7.3T * 4
The software versions are as follows:

Test Methods
We have developed a Java-based testing tool using the OpenMLDB Java SDK and Jedis to compare memory usage between OpenMLDB and Redis. The objective is to insert identical data into both databases and analyze their respective memory usage. Due to variations in supported data types and storage methods, the data insertion process differs slightly between the two platforms. Since the data being tested consists of timestamped feature data, we have devised the following two distinct testing approaches to closely mimic real-world usage scenarios.
Method One: Random Data Generation
In this method, each test dataset comprises m keys serving as primary identifiers, with each key potentially having n different values (simulating time series data). For simplicity, each value is represented by a single field, and the lengths of the key and value fields can be controlled via configuration parameters. For OpenMLDB, we create a test table with two columns (key, value) and insert each key-value pair as a data entry. In the case of Redis, we use each key as an identifier and store multiple values corresponding to that key as a sorted set (zset) within Redis.
Example
We plan to test with 1 million (referred to as 1M) keys, each corresponding to 100 time-series data entries. Therefore, the actual data stored in OpenMLDB would be 1M * 100 = 100M, which is equivalent to 100 million data entries. In Redis, we store 1M keys, each key corresponding to a sorted set (zset) containing 100 members.
Configurable Parameters

Operations Steps (Reproducible Steps)
a. Deploy OpenMLDB and Redis
Deployment can be done through containerization or directly on physical machines using software packages. There is no significant difference between the two methods. Below is an example of using containerization for deployment:
-
OpenMLDB
- Docker image:
docker pull 4pdosc/openmldb:0.8.5 - Documentation: https://openmldb.ai/docs/zh/main/quickstart/openmldb_quickstart.html
- Docker image:
-
Redis:
- Docker image:
docker pull redis:7.2.4 - Documentation: https://hub.docker.com/_/redis
- Docker image:
b. Pull the testing code
c. Modify configuration
Configuration file:
src/main/resources/memory.properties[link]Note: Ensure that
REDIS_HOST_PORTandZK_CLUSTERconfigurations match the actual testing environment. Other configurations are related to the amount of test data and should be adjusted as needed. If the data volume is large, the testing process may take longer.
d. Rut the tests
[Related paths in the GitHub benchmark Readme]
e. Check the output results
Method Two: Using the Open Source Dataset TalkingData
To enhance the credibility of the results, cover a broader range of data types, and facilitate result reproduction and comparison, we have designed a test using an open-source dataset — the TalkingData dataset. This dataset is used as a typical case in OpenMLDB for ad fraud detection. Here, we utilize the TalkingData train dataset, which can be obtained as follows:
Sample data: sample data used in OpenMLDB
Full data: Available on Kaggle
Differing from the first method, the TalkingData dataset includes multiple columns with strings, numbers, and time types. To align storage and usage more closely with real-world scenarios, we use the “ip” column from TalkingData as the key for storage. In OpenMLDB, this involves creating a table corresponding to the TalkingData dataset and creating an index for the “ip” column (OpenMLDB defaults to creating an index for the first column). In Redis, we use “ip” as the key and store a JSON string composed of other column data in a zset (as TalkingData is time-series data, there can be multiple rows with the same “ip”).
Example

Configurable Parameters

Operation Steps (Reproducible Steps)
a. Deploy OpenMLDB and Redis
Same as in method one.
b. Pull the testing code
c. Modify configuration
- Configuration file:
src/main/resources/memory.properties[link] - Note:
- Ensure that
REDIS_HOST_PORTandZK_CLUSTERconfigurations match the actual testing environment. - Modify
TALKING_DATASET_PATH(defaults toresources/data/talking_data_sample.csv).
- Ensure that
d. Obtain the test data file
Place the test data file in the resources/data directory, which is consistent with the TALKING_DATASET_PATH configuration path.
e. Run the tests
[Related paths in the GitHub benchmark Readme]
f. Check the output results
Results
Random Data Test


Under the experimental conditions mentioned above, storing the same amount of data, OpenMLDB (memory storage-mode) consumes over 30% less memory compared to Redis.
TalkingData Test

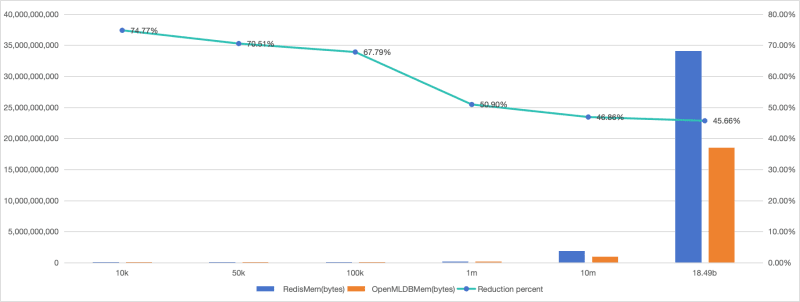
Thanks to OpenMLDB’s data compression capabilities, when sampling small batches of data from the TalkingData train dataset, OpenMLDB’s memory usage is significantly reduced by 74.77% compared to Redis. As the volume of test data increases, due to the nature of the TalkingData train dataset, a high number of duplicate keys during storage occurs, leading to a decrease in the storage advantage of OpenMLDB relative to Redis. This trend continues until all the train dataset is stored in the database, at which point OpenMLDB’s memory reduction compared to Redis is 45.66%.
Summary
For the open-source dataset TalkingData when storing data of similar magnitude, OpenMLDB reduces memory usage by 45.66% compared to Redis. Even on datasets consisting purely of string data, OpenMLDB can still reduce memory usage by over 30% compared to Redis.
This is because of OpenMLDB’s compact row encoding format, which optimizes various data types when storing the same amount of data. The optimization reduces memory usage in in-memory databases and lowers servicing costs. Comparisons with mainstream in-memory databases like Redis further demonstrate OpenMLDB’s superior performance in terms of memory usage and Total Cost of Ownership (TCO).
For more information on OpenMLDB:
- Official website: https://openmldb.ai/
- GitHub: https://github.com/4paradigm/OpenMLDB
- Documentation: https://openmldb.ai/docs/en/
- Join us on Slack!
This post is a re-post from OpenMLDB Blogs.

Top comments (0)