In C++, an unordered set is a container that stores a collection of unique elements in an unordered manner. It provides efficient storage and retrieval of data by using hash functions. Unlike a traditional set, the elements in an unordered set are not sorted. This allows for faster insertion, deletion, and search operations.
Unordered sets are particularly useful when the order of elements doesn't matter, and the focus is on efficient data retrieval.
In this comprehensive guide, we will explore the various features and functionalities of unordered sets in C++, along with examples and best practices for efficient data storage and retrieval.

What is an unordered set?
In C++, an unordered set is a container from the Standard Template Library (STL) that stores a collection of unique elements in no particular order. It is implemented as a hash table or hash set, which provides constant-time average complexity for insertion, deletion, and search operations.
The unordered set is defined in the header and is part of the C++ Standard Library since the C++11 standard. It is a template class that allows you to store objects of any type that supports hashing and equality comparison.
Here's an example of using an unordered set in C++:
#include <iostream>
#include <unordered_set>
int main() {
std::unordered_set<int> numbers;
// Inserting elements
numbers.insert(10);
numbers.insert(5);
numbers.insert(3);
// Checking if an element is present
if (numbers.count(5) > 0) {
std::cout << "5 is present in the set" << std::endl;
}
// Removing an element
numbers.erase(10);
// Iterating over the elements
for (const auto& num : numbers) {
std::cout << num << " ";
}
std::cout << std::endl;
return 0;
}
In this example, we create an unordered_set called numbers to store integers. We insert elements using the insert function, remove elements using erase, and check if an element is present using the count function. We can iterate over the elements using a range-based for loop.
The elements in an unordered set are stored in buckets based on their hash values, allowing for fast access and efficient element lookup. However, the order of elements in the set is not guaranteed and can vary between different runs or implementations.
The key features of an unordered set include:
- Fast element insertion, removal, and lookup with constant-time average complexity.
- Automatic handling of hash function and equality comparison for supported types.
- Ability to store and retrieve unique elements.
- Does not maintain any particular order of elements.
Implementing Unordered Sets in C++
Unordered sets are useful when you need a collection of unique elements and do not require a specific order. They are particularly efficient for scenarios where fast lookup is required.
To implement unordered sets in C++, follow these steps:
Step 1: Include the header:
#include <unordered_set>
This header provides the necessary definitions and functions for using unordered sets.
Step 2: Create an instance of std::unordered_set:
std::unordered_set<DataType> mySet;
Replace DataType with the appropriate data type you want to store in the set. For example, if you want to store integers, use std::unordered_set. This creates an empty unordered set of the specified data type.
Step 3: Insert elements into the set:
mySet.insert(element);
Use the insert function to add elements to the set. Replace element with the value you want to insert. You can repeat this step to add multiple elements.
Step 4: Check if an element is present:
if (mySet.count(element) > 0) {
// Element is present in the set
}
The count function returns the number of occurrences of a specific element. If the count is greater than 0, the element is present in the set.
Step 5: Remove an element from the set:
mySet.erase(element);
Use the erase function to remove an element from the set. Replace element with the value you want to remove. If the element is not present, no action is taken.
Step 6: Iterate over the elements in the set:
for (const auto& element : mySet) {
// Access and process each element
}
Use a range-based for loop to iterate over the elements in the set. Replace element with a variable name of your choice. Within the loop, you can access and process each element.
Hashing in Unordered Sets
Hashing in unordered sets is a fundamental concept that allows for efficient storage and retrieval of elements. It involves using a hash function to convert elements into unique integer values called hash codes. These hash codes are then used to determine the storage location (bucket) for each element within the set.
Here's how hashing works in unordered sets:
- Hash Function: A hash function takes an element as input and computes a hash code, which is an integer value. The hash function should ideally distribute the hash codes uniformly across the range of possible hash values, reducing the chances of collisions (multiple elements mapping to the same hash code).
- Hash Code to Bucket Mapping:Once the hash code is computed, it is converted to a bucket index within the set's internal data structure (typically an array of buckets). The number of buckets is usually larger than the number of elements to allow for efficient distribution and handling of collisions.
- Collision Handling: Collisions occur when multiple elements produce the same hash code and need to be stored in the same bucket. Common collision resolution techniques include separate chaining (using linked lists or other data structures to store multiple elements in the same bucket) or open addressing (probing nearby buckets to find an empty slot for the colliding element).
- Insertion and Lookup: When inserting an element into the unordered set, the hash function is applied to compute the hash code. The hash code is then used to determine the appropriate bucket for the element. If the bucket is empty, the element is placed directly into the bucket. In the case of collisions, the collision resolution technique is used to handle the situation.
During element lookup, the hash code is computed for the target element, and the set checks the corresponding bucket for the presence of the element. The hash code allows for quick identification of the bucket to search, significantly improving the efficiency of the search operation.
Here's an example that demonstrates hashing in unordered sets in C++:
#include <iostream>
#include <unordered_set>
struct Employee {
std::string name;
int age;
int employeeId;
};
// Custom hash function for the Employee struct
struct EmployeeHash {
std::size_t operator()(const Employee& emp) const {
std::hash<std::string> stringHash;
std::hash<int> intHash;
std::size_t hash = 0;
hash ^= stringHash(emp.name) + 0x9e3779b9 + (hash << 6) + (hash >> 2);
hash ^= intHash(emp.age) + 0x9e3779b9 + (hash << 6) + (hash >> 2);
hash ^= intHash(emp.employeeId) + 0x9e3779b9 + (hash << 6) + (hash >> 2);
return hash;
}
};
// Custom equality operator for the Employee struct
struct EmployeeEqual {
bool operator()(const Employee& emp1, const Employee& emp2) const {
return emp1.employeeId == emp2.employeeId;
}
};
int main() {
std::unordered_set<Employee, EmployeeHash, EmployeeEqual> employees;
// Create Employee objects
Employee emp1 = { "John", 30, 1001 };
Employee emp2 = { "Alice", 25, 1002 };
Employee emp3 = { "Bob", 28, 1003 };
// Insert employees into the unordered set
employees.insert(emp1);
employees.insert(emp2);
employees.insert(emp3);
// Find an employee by employeeId
Employee searchEmp = { "", 0, 1002 };
auto iter = employees.find(searchEmp);
if (iter != employees.end()) {
std::cout << "Employee found: " << iter->name << std::endl;
} else {
std::cout << "Employee not found" << std::endl;
}
return 0;
}
In this example, we have a struct Employee representing employee information. We want to use an unordered set to store unique employee objects based on their employeeId.
We define a custom hash function EmployeeHash that computes the hash code for an Employee object. The hash function combines the hash values of the name, age, and employeeId fields using the std::hash function and bitwise operations.
We also provide a custom equality operator EmployeeEqual that compares two Employee objects based on their employeeId fields.
In main(), we create an unordered set employees that stores Employee objects using the custom hash function EmployeeHash and equality operator EmployeeEqual.
We insert three Employee objects into the set using the insert function.
Next, we search for an employee with an employeeId of 1002 using the find function. If the employee is found, we print the employee's name. Otherwise, we print a message indicating that the employee was not found.
By defining a custom hash function and equality operator, we ensure that the Employee objects are hashed and compared based on their employeeId field when inserting and searching in the unordered set.
Iterating and Accessing Unordered Sets
Iterating and accessing elements in an unordered set in C++ is similar to other containers. We can use iterators to traverse the elements in the set. Here is an example of how to iterate through an unordered set:
std::unordered_set<int> mySet = {1, 2, 3, 4, 5};
// Using a range-based for loop
for (const auto& element : mySet) {
// Access the element
std::cout << element << " ";
}
// Using an iterator
for (auto it = mySet.begin(); it != mySet.end(); ++it) {
// Access the element
std::cout << *it << " ";
}
To access a specific element in the unordered set, we can use the find function or the count function. The find function returns an iterator to the element if found, or mySet.end() if not found. The count function returns the number of elements matching the specified key. Here is an example:
std::unordered_set<int> mySet = {1, 2, 3, 4, 5};
// Using find function
auto it = mySet.find(3);
if (it != mySet.end()) {
// Element found
std::cout << "Element 3 found in the unordered set" << std::endl;
} else {
// Element not found
std::cout << "Element 3 not found in the unordered set" << std::endl;
}
// Using count function
if (mySet.count(5) > 0) {
// Element found
std::cout << "Element 5 found in the unordered set" << std::endl;
} else {
// Element not found
std::cout << "Element 5 not found in the unordered set" << std::endl;
}
By using these techniques, we can efficiently iterate through and access elements in an unordered set in C++.
Avoiding Common Pitfalls and Best Practices
When working with the unordered set in C++, it is important to be aware of common pitfalls and adopt best practices to ensure efficient data storage and retrieval. Here are some tips to help you avoid common pitfalls and make the most of unordered sets:
- Choose the Right Hash Function: Selecting an appropriate hash function is crucial for efficient retrieval. Consider the characteristics of your data and choose a hash function that minimizes collisions.
- Reserve Sufficient Space: To avoid frequent rehashing and improve performance, allocate enough space for your unordered set using the reserve function. This prevents unnecessary memory reallocations as elements are added.
- Avoid Unnecessary Copies: When inserting elements into an unordered set, avoid making unnecessary copies by using move semantics whenever possible. This can significantly improve performance, especially for large objects.
- Avoid Modifying Elements: It is recommended to avoid modifying elements stored in an unordered set directly. Instead, remove the element, modify it, and then insert it back into the set. This helps maintain the integrity of the underlying data structure.
- Use Appropriate Load Factor: The load factor determines the average number of elements per bucket in the unordered set. Adjusting the load factor appropriately can balance memory usage and retrieval efficiency. Consider the trade-off between memory and performance when setting the load factor.
- Avoid Frequent Resizing: Frequent resizing operations can impact performance. Monitor the size of your unordered set and consider increasing the initial capacity if you anticipate a large number of elements.
- Understand Iterator Invalidations: Be aware that certain operations, such as erasing elements, can invalidate iterators. Avoid using invalidated iterators to prevent undefined behavior.
- Consider Thread Safety: If your application involves multiple threads, you need to ensure proper synchronization when working with unordered sets to avoid data races. Consider using appropriate synchronization mechanisms, such as mutexes or locks.
Learn C++ programming with C++ online compiler
Learning a new programming language might be intimidating if you're just starting out. Lightly IDE, however, makes learning programming simple and convenient for everybody. Lightly IDE was made so that even complete novices may get started writing code.
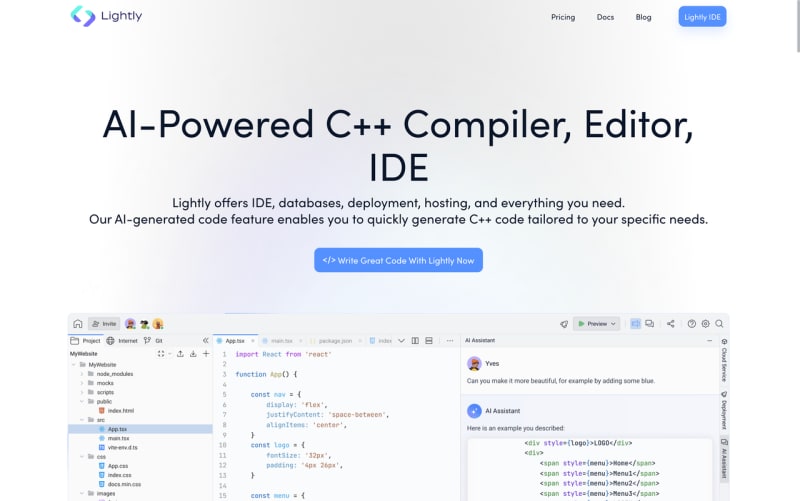
Lightly IDE's intuitive design is one of its many strong points. If you've never written any code before, don't worry; the interface is straightforward. You may quickly get started with programming with our C++ online compiler only a few clicks.
The best part of Lightly IDE is that it is cloud-based, so your code and projects are always accessible from any device with an internet connection. You can keep studying and coding regardless of where you are at any given moment.
Lightly IDE is a great place to start if you're interested in learning programming. Learn and collaborate with other learners and developers on your projects and receive comments on your code now.

Top comments (0)