Est-ce un Pokémon ? Non, mais le thème de cet article vous permettra de tout attraper.

Vues rapidement dans un article précédent, les expressions régulières sont un langage de programmation qui va vous permettre de filtrer du texte de façon très précise.
Pour suivre les exercices de cet article, je vous invite à ouvrir une nouvelle fenêtre ou onglet avec https://regex101.com/ afin de tester en temps réel les commandes.
Regex101.com est un site qui vous permet de tester vos expressions régulières sur un texte de votre choix.
Pour être sûr que tout fonctionne, assurez vous que vous avez les options "global" et "multiligne" activées en cliquant sur le bout droit de la première fenêtre :

Bases
Allons directement au vif du sujet. Dans cette première partie, nous allons travailler sur ce texte de Guillaume Apollinaire (que vous pouvez copier dans la seconde fenêtre sur Regex101) :
NUIT RHÉNANE (1913)
Mon verre est plein d’un vin trembleur comme une flamme
Écoutez la chanson lente d’un batelier
Qui raconte avoir vu sous la lune sept femmes
Tordre leurs cheveux verts et longs jusqu’à leurs pieds
Debout chantez plus haut en dansant une ronde
Que je n’entende plus le chant du batelier
Et mettez près de moi toutes les filles blondes
Au regard immobile aux nattes repliées
Le Rhin le Rhin est ivre où les vignes se mirent
Tout l’or des nuits tombe en tremblant s’y refléter
La voix chante toujours à en râle-mourir
Ces fées aux cheveux verts qui incantent l’été
Mon verre s’est brisé comme un éclat de rire
Une question de caractères
Les regex comprennent le texte comme un ensemble de caractères. On peut regrouper ces caractères grossièrement en trois groupes :
- les caractères alphabétiques (représentés par
a-zA-Zou\w) - les caractères numériques (représentés par
0-9ou\d) - les caractères spéciaux (
!@#$%^&*():""etc.)
dans la première fenêtre écrivez mais n'appuyez pas sur Entrée :
\w

Vous remarquez que tous les caractères alphabétiques sont surlignés en bleu. Donc, ils sont couverts par la recherche \w. Ce n'est pas le cas de certains caractères spéciaux comme "à" ou "ù". Donc, nous filtrons ici toutes les lettres sans accents.
Si l'on effectue la recherche a-zA-Z, on trouvera le même résultat.
effacez
\wet écrivez maintenant :\d

Ici tous les chiffres sont couverts.
Il est aussi possible de choisir tous les caractères sauf les caractères alphabétiques avec \W et pareil pour tous les caractères sauf numériques : \D
Attention : utiliser une recherche par négation donne des résultats différents. C'est-à-dire que \d n'est pas équivalent à \W. \W donnera comme résultat aussi des caractères comme les espaces, les caractères spéciaux et les retours à la ligne.
Un peu comme un.e typographe qui prépare une page, vous devez penser le texte comme un ensemble de caractères qui dessinent le texte ; cela comprend les espaces et les retours à la ligne.
Essayez des recherches avec
(a-zA-Z)(tout caractères entre "a" et "z" minuscule ou majuscule) et modifiez les intervalles (exemple :(a-cA-O)). Quel est le résultat ? Que donne la recherche :(1-3)?
Note : les caractères () définissent un groupe de recherche
Après les caractères alphanumériques (a-zA-Z0-9), nous pouvons aussi rechercher des caractères plus spécifiques comme les espaces (insécables et sécables) \s, les retours à la ligne \n, les retours chariots \r. #salutLesTypographes
Une question de position
Que ce passe-t-il lorsque vous recherchez un mot particulier, par exemple, tous les mots qui commencent par "C".
Pour cela, les regex utilisent des caractères de position: ^ pour définir le début d'une ligne $ pour définir la fin d'une ligne.
Donc pour toutes les lignes commencent par un caractère alphabétique : ^\w

Et toutes les lignes qui commencent par "C" : ^C (majuscule vus que dans ce texte toutes les lignes commencent par une majuscule).

Pour rechercher tous les débuts de chaîne de caractères (en gros un groupe de lettres et de chiffres séparées par un espace), il faudra utiliser l'ancre : \b. Exemple : tous les mots commençants par "c" - \b[c].
Les parenthèses carrées
[]trouveront une occurrences dans la liste présente à l'intérieur. Donc[c]trouvera la lettre "c". La recherche[ces]recherchera les occurrences de "c", "e" ou "s". Dans le cas où vous désirez faire une recherche pour un groupe, il faudra utiliser les parenthèses simples :(ces). Cette dernière recherche filtrera toutes les occurrences du groupe de lettres "ces".
\b est un peu malicieux car il recherchera des espaces avant un caractère alphabétique mais pas après sauf si vous le précisez en le plaçant à la fin. L'inverse de \b est \B ; tout caractère alphabétique non précédé par un espace donc "à l'intérieur d'un mot mais pas au début".
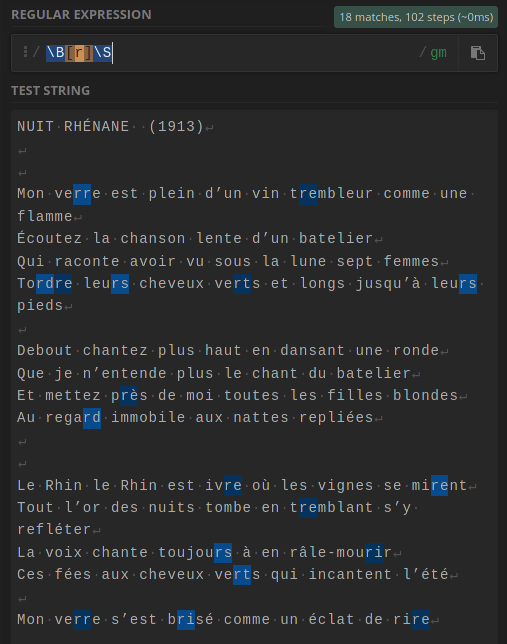
Essayez la recherche suivante :
\b(err)et ensuite(er)\b.
Pour recherchez la lettre "r" qui ne se trouve pas au début d'un mot, ni à la fin d'un mot : \B[r]\B ou bien \B[r]\S. Ici \S représentes tous les caractères qui ne sont pas des espaces.
Recherche modulaire
C'est déjà beaucoup, mais maintenant, il est possible de rajouter un couche de précision dans nos recherches grâce à des "modules".
Nous avons déjà vu ^ et $ qui définissent le début et la fin d'une ligne. Donc, par exemple : [a-z]\.[a-z]$ trouvera toutes les lignes avec une lettre, suivie d'un point (".") et un caractère alphabétique.
Pourquoi des
\devant les caractères spéciaux ? Chaque caractère a une signification et une fonction particulière. Nous voulons considérer ces caractères de façon littérale, donc nous devons les échapper avec le caractère\. C'est-à-dire, préciser à l'ordinateur qu'il ne faut pas les considérer comme des fonctions mais comme de simples caractères. C'est le cas pour les/,.,^ou$si vous recherchez ces caractères dans un fichier.Que fait "." lorsqu'il n'est pas échappé ? Les regex le remplacent par n'importe quel caractère. Donc par exemple,
[c].[s]donnera des résultats pour un mot commençant par "c", finissant par "s" mais ayant n'importe quel caractère, lettre, chiffre ou caractère spécial en seconde position.
Mais attention, car lorsqu'il est à l'intérieur de parenthèses carrées, ^ défini une négation. Donc ^a-z et [^a-z] ne donneront pas le même résultat ! La première version prendra toutes les lignes qui commencent par une lettre et le suivant toutes les occurrences qui n'ont pas de lettres.
+ et * associé aux ancres comme \d ou \w vont rechercher respectivement une ou un nombre illimité d'occurrences ou, dans le cas de *, zéro ou un nombre illimité d'occurrences.
Vous pouvez aussi préciser le nombre d’occurrences avec les moustaches {}. Par exemple, \w{1, 4} cherchera entre une lettre suivie de jusque trois autres lettres.

Cas pratique
Ici, vous devez être un peu perdu.e.s, donc essayons de prendre des exemples pratiques.
Si vous n'avez pas lu les articles précédents, je vous invite à le faire dans le cas où certaines parties des exemples ne sont pas claires. Premier article et second article
Regex101 est fun, mais mettons nous dans une situation réaliste.
Téléchargeons ce fichier de logs :
wget https://gist.githubusercontent.com/christalib/0dd247443fb8251af3ff24c5eb511073/raw/ca9a0b1f8ce90529cc299dea87002f1eb21234a8/gistfile1.txt -O access_log.txt
Le fichier est assez imposant :
cat access_log.txt | wc -l
# 1173
Il est possible de faire toutes les opérations que nous avons vues précédemment avec
cut,cat,|etc.
Des chiffres...
Commençons par faire des opérations avec les chiffres.
Nous voulons : tous les groupes de plus de trois chiffres.
grep --color -E "[0-9]{3,}" access_log.txt
L'option
-Eutilisera les regex étendues (voir fin de l'article pour plus de détails). L'option--colorcoloriera le résultat de notre recherche.
Si tout va bien, votre résultat ressemblera plus au moins à ceci :

Vous remarquerez que la première partie de la ligne est une adresse IPv4. Il est possible de les filtrer avec : cat access_log.txt | cut -d " " -f 1. Mais comme nous faisons des regex, faisons-le à la main !
Une adrets IPv4 existe sous cette forme : chiffre entre 0 et 9 répété de 1 à 3 fois, suivi d'un point, 3 fois puis chiffre de 0 à 9.
Donc ici, nous avons un chiffre de 0 à 9 répété de une à trois fois :
0.
1.
2.
...
123.
...
567.
...
999.
En regex : [0-9]{1,3}\.
-
{3}le groupe est répété trois fois
0.0.0.
...
123.123.123.
...
999.999.999.
En regex : ([0-9]{1,3}\.){3}\.
Finalement le groupe est terminé par un chiffre de 0 à 9, répété de une à trois fois mais pas suivi d'un point.
0.0.0.0
...
123.123.123.123
...
999.999.999.999
En regex : ([0-9]{1,3}\.){3}[0-9]{1,3}
Et la commande complète :
grep -E "^([0-9]{1,3}\.){3}[0-9]{1,3}" access_log.txt
-
^donne l'indication que l'occurrence est au début de la ligne. -
()définissent un premier groupe d'occurrences qui sera traité ensemble. -
[]définissent un groupe dans lequel il y aura au moins un résultat -
0-9définit un nombre -
{1,3}définit une occurrence qui sera répétée entre 1 et 3 fois -
\.échappe le "." pour être considère comme un simple caractère
Et voilà le travail !

Que faire pour arriver au même résultat qu'avec cut ? C'est-à-dire sans avoir la ligne entière ? Rien de plus simple, ajoutons l'option -o pour dire à grep qu'il ne faut montrer que les occurrences et non toute la ligne.
grep -oE "^([0-9]{1,3}\.){3}[0-9]{1,3}" access_log.txt | sort -u

... et des lettres
Regardez le dessin suivant :

Il y a une erreur dans le regex, utilisez celui-là :
(([a-zA-Z\-0-9]+\\.)[a-zA-Z]{2,})$
Essayez de deviner que trouvera ce regex avant de le lancer, ou bien, lancez le simplement ! #yolo
Conclusion et remarques
Bon, c'était un peu prise de tête quand même.

Les regex sont un outil très puissant et vraiment utile lorsque vous faites de la recherche dans des centaines voire des milliers de fichiers. Nous avons vu grep mais sachez qu'il existe zgrep qui permet de chercher dans des fichiers compressés comme les .zip.
Il y a aussi une version plus puissante de grep, ripgrep qui décoiffe !
Les regex sont aussi un outil très compliqué, leurs possibilités sont très étendues et nous n'avons vu que la surface.
Leur implémentations peuvent varier aussi selon les langages. Si vous codez en Python, il est possible que certaines options ne soient pas disponibles. Par exemple, ce site permet de comparer certaines options des regex dans différents langages. Car les standards de regex varient en fonction des langages. Pourquoi faire simple...

Pour finir, j'espère que vous avez pu suivre cet article, et que les regex ont un peu plus de sens pour vous. Vous pouvez vous entraînez aux regex sur ce site web quand vous vous ennuyez : https://regexcrossword.com/challenges.
Merci à Dattaz et E. pour les relectures !

Top comments (0)